Updated March 6, 2023

Introduction to Hadoop fsck
In the Hadoop stack, we are having the HDFS service to manage the complete storage part of the Hadoop. The fsck command is used to check the various inconsistencies on the HDFS level or HDFS file system. To keep the HDFS file system healthy, we need the proper management of the HDFS file system. The HDFS file system is used to check the health of the file system. We are able to find the find under the replicated block, missing files block, corrupted blocks, over the replicated block, etc. As per the requirement, we can use the different command with the fsck command. In this topic, we are going to learn about Hadoop fsck.
Syntax of the HDFS fsck
hadoop fsck [ GENERIC OPTIONS ] < path > [-delete | -move | -openforwrite ] [-files [ -blocks [ -locations | -racks] ] ]
1. Hadoop: We can use the Hadoop keyword in the syntax or command. It will take the different arguments as an option and command. As the end result, we are able to check the status of the Hadoop HDFS file system.
2. fsck: To use the status of the HDFS file system. We need to use the fsck keyword in the HDFS or Hadoop command.
3. OPTION: We can provide the different flags as options that are compatible with the Hadoop fsck command. We need to use different compatible keywords like –delete, -move, -openforwrite, etc.
4. Path: As per the requirement, we can define the HDFS path to check the status of the HDFS file system.
How HDFS fsck Works?
In the Hadoop ecosystem, we are having multiple components or services. The HDFS is one of the important services to store the data in the distributed mode. While running any application job, it is important that the data should be a consistent state. As the data is distributed on different nodes, it may happen that the data will be in an in-consistence state. To fix this, we are having the hadoop fsck command. It will help to check the inconsistencies in the Hadoop file system. It is mainly designed for reporting problems on the HDFS file system. In reporting, it will give the information about the replicated block, missing files block, corrupted blocks, over the replicated block, etc. In the traditional fsck command, the fsck command will not correct the errors those was detected. In general, the namenode will automatically precise most of the file system recover alter or failure part. By default, the fsck command will ignore the open files but while reporting it will select all the files and give detailed information of it. The HDFS / Hadoop fsck command is not a shell command. Basically, it will run the ‘bin/hadoop fsck’ file.
The Hadoop fsck command deals with the Hadoop HDFS service. To work with the Hadoop fsck command, we can trigger the command in different ways like HDFS shell, Hue UI, Zeppelin UI, third party application tools, etc.
The Hadoop fsck command will trigger from the HDFS shell windows or any other tool. The HDFS compiler will validate the command first. If the command is valid then it will pass for the further process or it will through an error message. Once the command will valid then the request goes to the HDFS namenode. The namenode having the detail information of HDFS block. It will check the request if the block information is available or not. If the block information is available then it will do the necessary action on it. If the block information is not present then it will through an error message.
Below are the lists of options that are compatible with the Hadoop fsck command.
<path>: As per the quote “<>”, It will start the checking from the same path.
-move: It will help to move the corrupted files to the /lost+found.
-delete: It will help to delete the corrupted files on the HDFS level.
-openforwrite: It will print the out files opened for the write.
-files: It will display the files being checked.
-blocks: It will help to display the block report information of the HDFS file system.
-locations: It will display the locations for every block.
-racks: It will help to display the network topology for the data-node locations.
Example for the HDFS fsck
Here are the examples mention below
Hadoop fsck Command
In the Hadoop environment, the Hadoop fsck command is used to check the consistency status of the Hadoop file system. It will print the detailed report of the HDFS file system.
Syntax:
hadoop fsck /
Explanation:
As per the above command, we are getting the detailed report of the average block, missing block, corrupt block, missing internal, etc. We are getting the information on the “/” level. If you would need the information on a specific directory then we can mentation the path of the directory.
Output:
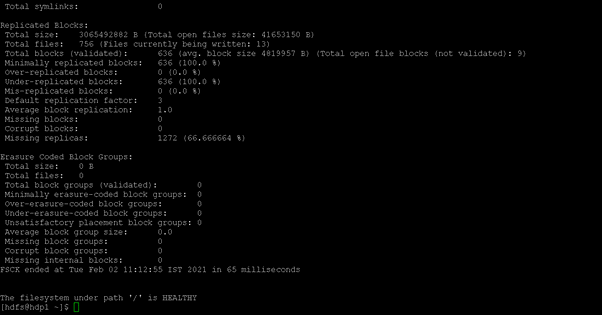
HDFS fsck: Check the Status of HDFS Corrupted Blocks
In Hadoop, we are having the functionality to print the HDFS corrected block only. It will help to identify the block information and try to repair it.
Syntax:
HDFS fsck / -list-corruptfileblocks
Explanation:
As per the above command, we are using the -list-corruptfileblocks option. It will help to print the block information on the “/” HDFS level only.
Output:
![]()
HDFS fsck: Get the Status of Under Replicated Block
In the Hadoop fsck command, we are having the functionality to print the under the replicated block.
Syntax:
HDFS fsck /spark2-history/ | grep 'Under replicated' | awk -F':' '{print $1}'
Explanation:
As per the above command, we are using the “/spark2-history/” directory. We are getting the information of the “Under replicated” block for the “/spark2-history/” directory.
Output:
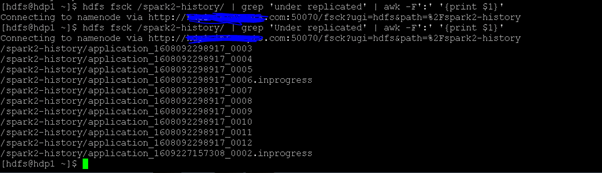
Conclusion – Hadoop fsck
We have seen the uncut concept of “HDFS fsck” with the proper example, explanation, and output. The HDFS fsck is very important in terms of the Hadoop file system data or file recovery. We are able to get detailed information of HDFS file system information in terms of the average block, missing block, corrupt block, missing internal, etc. It will also check the consistency status of the Hadoop file system.
Recommended Articles
This is a guide to Hadoop fsck. Here we discuss the uncut concept of “HDFS fsck” with the proper example, explanation, and output. You may also have a look at the following articles to learn more –
