Updated March 4, 2023

Introduction to Hadoop Hue
- Normally, a Hue functions as a Hadoop framework which was introduced by Cloudera. Hadoop is said to be an ecosystem cracking data challenges for variable size but not working as a single tool.
- Also, Hue can be defined as a web user interface delivering several services together with a file path for browsing HDFS.
- Hue includes few chief features such as Hadoop Shell, Job Browser, Impala editor, Pig editor, User admin permissions, Ozzie web interface, HDFS file browser, Hadoop API Access and Hive editor. This features are accessible via Hue and also the users who are not familiar using the command line interface is able to implement Hue and access entire of its functionalities.
- Hue gives a web user interface type handy tool to the clients to programming languages for avoiding syntax errors during the SQL query execution.
Hue Installation
- Hue is considered as a graphical user interface for functioning and developing applications implemented for Apache Hadoop.
- You need to know that this Hadoop Hue can be configured or installed only via a web browser. Also, Hue need the Hadoop enclosed in Cloudera’s Distribution containing Apache Hadoop(CDH) of version 3 update 4 or advanced.
- Here, let us view the instructions for installing as well as configuring a Hue tarball tool on a multi-node cluster. Also, user require to install CDH along with updating few Hadoop configuration files to be done before executing Hue.
- Hue includes a web service which runs on a distinct node in the cluster that is selected where the Hue is to be run. That node indicates as the Hue Server. This must be one of the nodes inside the cluster for finest performance, however it can be an isolated node given that no overly restrictive firewalls are present. You can practice the prevailing master node for lesser clusters of fewer than 10 nodes such as the Hue Server. For downloading the Hue tarball, you can visit the link: http://github.com/cloudera/hue/downloads/
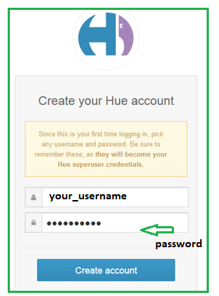
Hue Dependencies
Hue hires few Python modules that practice native code and involves definite development libraries to be connected on your system. One should have the below files installed for installing from the tarball. The prerequisite dependencies are:
| Redhat | Ubuntu |
| ant | ant |
| Gcc | gcc |
| Sqlite-devel | Libsqlite3-dev |
| Libxml2-devel | Libxml2-dev |
| Cyrus-sasl-devel | Libsasl2-dev |
| Libxslt-devel | Libxslt-dev |
| Cyrus-sasl-gssapi | Libsasl2-modules-gssapi-mit |
| Python-simplejson | Python-simplejson |
| Mysql-devel | Libmysqlclient-dev |
| Python-setuptools | Python-setuptools |
| Python-devel | Python-dev |
- Build:
You need to configure $PREFIX along with the path by running the following where the Hue is to be installed:
$PREFIX=/user/share make install
$cd /usr/share/hue
$sudo chmod 4750 apps/shell/src/shell/build/setuid
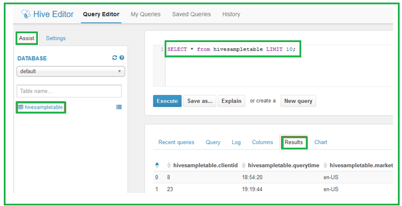
Hue can be setup wherever within the system and can be executed in place of a non-root user/opeartor. For beginning many sub-processes, the Shell application requires root privileges such as users that are logged in. For Hue, there should be the best practice for creating a new operator and moreover install Hadoop Hue application in that operator’s home directory otherwise also in the directory inside /usr/share.
Troubleshooting Hadoop Hue Tarball Installation
Q: Hue does not work correctly, after I have shifted the Hue installation from one directory to the other.
A: On moving the Hue installation due to the implementation of entire paths through few Python packages, a sequence of commands must be run. You need to execute the following commands in the new location:
$ rm app.reg
$ rm –r build
$ make apps
Q: Why other pieces of software are compiled by “make install”?
A: Hue installs a Python virtual environment that comprises its dependencies so that it confirms the ability of Hue to be constant on a variety of distributions plus architectures.
This confirms that the installing software is dependent on distinct versions of several Python libraries so that the user need not to be worried about missing the modules of software.
- Hue is shipped having a default configuration which functions for pseudo-distributed clusters.
Hadoop Hue create dashboard
- Dashboards basically are a collaborating way to discover the data swiftly and simply. For this practice, it does not need any programming and the analysis is completed by drag & drops with clicks.
- Concepts: Just drag & drop widgets which are interrelated together. It is inordinate for discovering new datasets or for checking devoid of having to type.
- Importing: You can drag and drop any CSV file and ingest it into an index just in a clicks through the Data Import Wizard(link). Here, the indexed data can be query able instantly and its magnitudes/facets is very fast for discovering.
- Browsing: In the last releases, the Collection browser has got issued delivering more data info on the columns. Here, the left metadata aid of Hue 4 creates it manageable for listing them and top at their content through the trial popup.
- Querying: In order to create the querying in-built and swift, the search box upkeep live prefix filtering of field data and originates along a Solr syntax autocomplete. Any field may be checked for its top standards of value. Thus, this type of study occurs precisely firm as the data is indexed.
- Databases: Solr – In this the top search bar option provides a complete autocomplete on all the values of the index. The “More Like This” feature allows you the nominated fields that the user may like to apply for discovering related records. It can be a prodigious method for discovering related concerns, consumers, individuals…. with concern to a list of elements.
SQL – Through the dashboards, we are able to query any configured SQL source..
- Reports: This option is work in development as the dashboards will shortly deliver a typical reporting opportunity.
- With Cloudera Quickstart VM where Hue, Hive, Solr and Hadoop are running and a dataset given, you require to open Hadoop Hue having credentials like username plus password. Then from the zipped folder, extract the file and then shift it to HDFS. Again, next the dataset should be moved into Hue, then the data need to index with Solr where create a fresh dashboard. Now follow the instructions and fill your dashboard having several charts conveying the data properly to elaborate the scenario.
Conclusion
- Hue is considered as a Web UI which aids the consumers to interact with the Hadoop ecosystem. The authentication system of Hue is pluggable type.
- Hue also facilitates with Web UI editor, accessed by Hive plus other programming languages.
- It is only available on Hadoop Framework which is Cloudera based and open source type making use of Apache Hadoop’s simpler.
Recommended Articles
This is a guide to Hadoop Hue. Here we discuss the Introduction, Hue Installation, Hue Dependencies, Troubleshooting Hadoop Hue Tarball Installation respectively. You may also have a look at the following articles to learn more –
