Updated March 15, 2023
Difference Between Hadoop and HBase
Hadoop is an open-source Java framework, used for managing and processing a huge amount of structured and unstructured data. Hadoop is massively scalable hence is used to process Big data workloads. Big data is stored, accessed and processed on the reliable and expandable cluster. HBase (Hadoop Database) is a non-relational and Not Only SQL i.e. NoSQL database that runs on the top of Hadoop as a distributed and scalable big data store. It is an open-source database in which data is stored in the form of rows and columns, in that cell is an intersection of columns and rows.
Below are the core components of Hadoop architecture:
- Hadoop Distributed File System (HDFS): Hadoop includes a distributed storage system, the Hadoop Distributed File System (HDFS). HDFS is the master-slave architecture that stores data across the cluster. Data is distributed on several slave nodes by the master node in the form of a block. The master node is called Namenode and slave nodes are called Datanode. HDFS is easily expandable and stores a huge amount of data on Datanodes. HDFS has a configurable replication factor with a default value of 3 which can be editable.
- MapReduce: MapReduce is a programming paradigm, processes in parallel on a huge number of datasets over the network. MapReduce refers to two different tasks: map the input data in which data is divided into a subset of data called tuples and reduce task takes these tuples from the map as input and combines to form the output of the original.
- Yarn: YARN stands for Yet another resource navigator that computing resources such as manages CPU and memory, and scheduling of resource requests.
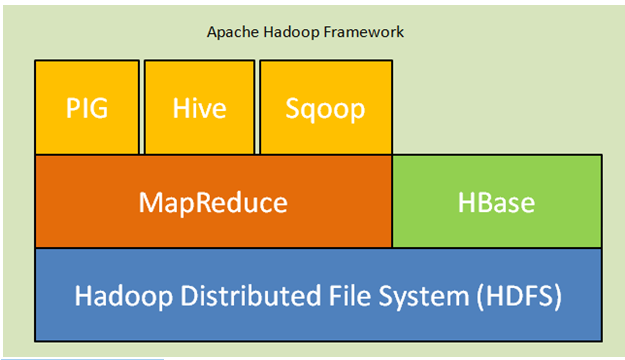
Fig. Apache Hadoop Framework
Region server serves data for reading/write operations. All the HBase data is stored in the HDFS file. The HDFS Datanode stores the data that the Region Server is managing. The HDFS Namenode keeps metadata information for all the physical data blocks that comprise the files.
Versioning is used to track cell changes, which keeps the track of content version. From that it any version of content can be retrieved. Each cell value includes the ‘version’ attribute with respect to the timestamp to retrieve the cell. Each value in the map is an uninterrupted array of bytes. The map is indexed by a row key, column key, and timestamp. The architecture of HBase is highly scalable, sparse, distributed, persistent, and multidimensional-sorted maps.
Head to Head Comparison Between Hadoop and HBase (Infographics)
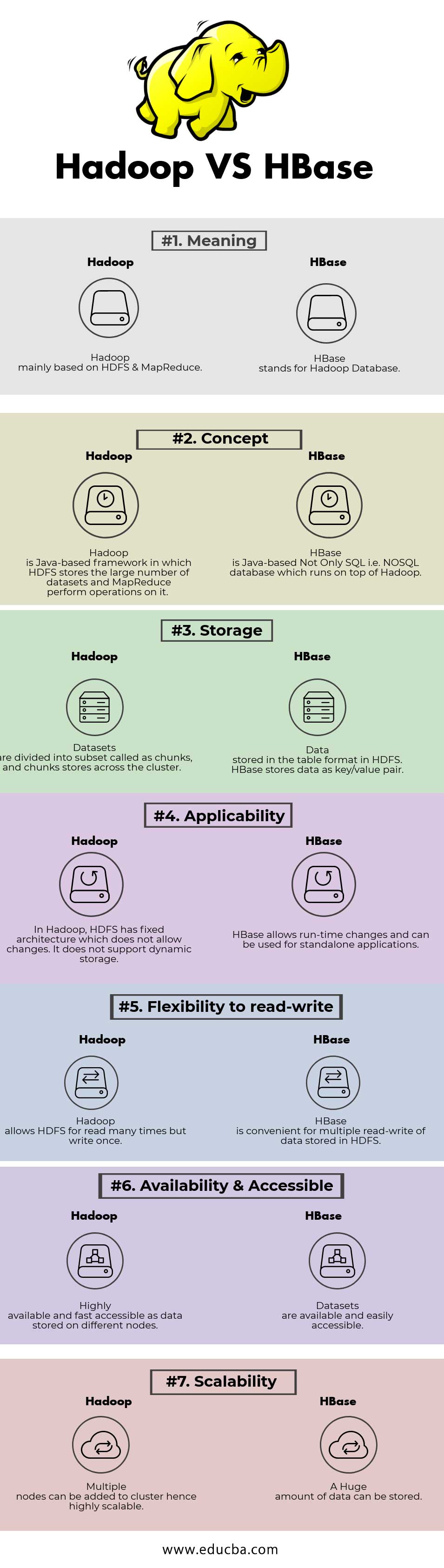
Key Differences between Hadoop vs HBase
The difference between Hadoop and HBase are explained in the points presented below:
- Hadoop is not suitable for Online analytical processing (OLAP) and HBase is part of Hadoop ecosystem which provides random real-time access (read/write) to data in Hadoop file system.
- Hadoop framework is fault-tolerant by design and supports rapid data transfer between nodes even during system failures. HBase is a non-relational and open source Not-Only-SQL database that runs on top of Hadoop. HBase comes under CP type of CAP (Consistency, Availability, and Partition Tolerance) theorem.
- Hadoop is most suitable for performing batch analytics. However, one of its biggest drawbacks is its inability to perform real-time analysis, the trending requirement of the IT industry. HBase, on the other hand, can handle large data sets and is not appropriate for batch analytics. Instead, it is used to write/read data from Hadoop in real-time.
- Both Hadoop and HBase are capable of processing structured, semi-structured as well as unstructured data. In Hadoop, HDFS lacks an in-memory processing engine slowing down the process of data analysis; as it is using plain old MapReduce to do it. HBase, on the contrary, boasts of an in-memory processing engine that drastically increases the speed of read/write.
- Hadoop is very transparent in its execution of data analysis. HBase, on the other hand, being a NoSQL database in tabular format, fetches values by sorting them under different key values.
Hadoop vs HBase Comparision Table
Below are the comparison.
| Basis of Comparison | Hadoop | HBase |
| Meaning | Hadoop mainly based on HDFS & MapReduce. | HBase stands for Hadoop Database. |
| Concept | Hadoop is a Java-based framework in which HDFS stores the large number of datasets and MapReduce perform operations on it. | HBase is Java-based Not Only SQL i.e. NoSQL database which runs on top of Hadoop. |
| Storage | Datasets are divided into subset called as chunks, and chunks stores across the cluster. | Data stored in the table format in HDFS. HBase stores data as key/value pair. |
| Applicability | In Hadoop, HDFS has fixed architecture which does not allow changes. It does not support dynamic storage. | HBase allows run-time changes and can be used for standalone applications. |
| Flexibility to read-write | Hadoop allows HDFS for reading many times but write once. | HBase is convenient for multiple read-write of data stored in HDFS |
| Availability & Accessible | Highly available and fast accessible as data stored on different nodes. | Datasets are available and easily accessible |
| Scalability | Multiple nodes can be added to cluster hence highly scalable. | A Huge amount of data can be stored. |
Conclusion
Hadoop architecture mainly based on HDFS and MapReduce. HBase is the supporting component in the Hadoop system. HBase is capable of hosting huge tables and provide fast random access to available data while HDFS is suitable for storing large files. Both Hadoop and HBase provide fast access to data but with HBase read/write operations can be performed and for HDFS read many times and once write can be performed. This article described an understanding of Hadoop and HBase, briefly highlighted features, and compared wisely.
