Updated March 16, 2023
Introduction to Hadoop WordCount
The Hadoop wordcount is one of the program types, and it is mainly used to read text files. It often counts the values in the files and other documents based on the user inputs; the output will be received if the input is in text format; the output is also the same for user input; the word is counted and more often used by the UI widgets like a tab.

What is Hadoop WordCount?
Word count is the type of application that mainly counts the occurrences based on the user inputs. It may be of any datatype that works with stand-alone-based applications. The pseudo-codes distributed either partially or fully distributed Hadoop installation come under the single node setup. The primary function of the word count is to count the characters based on the user inputs; the number will have occurred at each word series of formats like text, pdf, word, and other formats. The basic structure and mechanism, like the MapReduce algorithm, step to analyze the source codes’ word count.
How to Run Hadoop WordCount?
We can run the word count in any Hadoop environment for downloading the installation, like Cloudera quickstart VM, etc. Before running the word count, we must create the input and output locations using HDFS. Using the command sudo su hdfs for entering the hdfs file system, we make the directory like Hadoop fs -mkdir directory name to create the directory in the system. Next, we will assign the roles and access for the specified directory using the command options like Hadoop fs -chown directory name to give the user access to the specified directory. Next, we create the sample file using formats like text, document, etc., and move the duplicate files to the wordcount input directory on the HDFS system.
We can choose any file format based on the user’s convenience; when we use Linux or centos, the shell command will take more part of the user inputs for both small and large purposes. So that the word count is called as the simple application first name will check in the result file and used in the directory from the file system with the specific commands. Using the map-reduce technique, the input and output process will take the process with the jar files. After completing the task results, the data will be placed in the output directory. The resulting file sizes are created in the named directory like the user Hadoop output systems.
First, we ensure java is installed on the machine-like command called the java -version.

Then make sure we install the ssh server in the operating system like a command.
Sudo apt-get install ssh-server is installed on the Linux machine.
Next, we can Generate the RSA token key pair by using the public and private modes.
ssh-keygen -t rsa -P “if we prompted the file name using the save key command and pressed the enter command to leave it as a blank space.
Then type the below command to authorize the keys in the system.
Cat directory path keyfile.pub >> directory path authorized keys.
The Ssh localhost is installed on the system to perform the secure host on the Hadoop installation with the upgraded version.
After downloading the Hadoop and install in the operating system, we can edit and configure the Hadoop in the system like sudo gedit ~/.bashrc. After the Hadoop system configures, mapred-site, core-site, hdfs-site.xml, and yarn-site.xml are accessed by the HDFS system file nodes and name nodes, including the data nodes for each system.
Hadoop WordCount Command
The word count tool helps to forward the user data, which needs to create the local data repository for any big data application. A repository may be of any java file with input and output file systems that make the local repository, which contains the outside directory of the Hadoop data source. Using the MapReduce concept, we can compute the decomposition of large manipulation jobs, executing tasks with parallel clusters across the servers. Mainly it will get the results during the tasks that can be combined to compute a final set of results. The map-reduce will mostly have two sets of steps like Map function and Reduce function.
1. First, we need to go to the directory C:\Windows\System32\cmd.exe

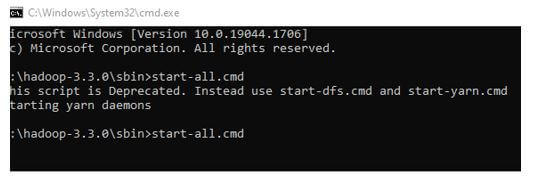
2. Navigate to cmd and enter start-all.cmd to start all the Hadoop services.
3. Create a directory by using the mkdir command.

4. Put or deploy the text file in the directory

5. To list all the files using the ls command.

6. After compressing and creating the java class in the jar file, execute the below command to count the words in the specified file.

Hadoop WordCount Web Pages
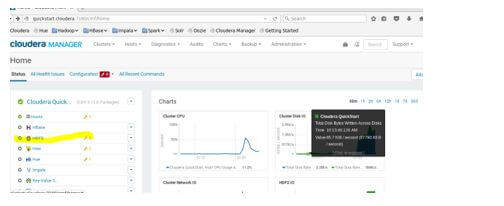
First, we need to start the HDFS service in the Cloudera manager after login the quickstart.cloudera:7180/cmf/home.
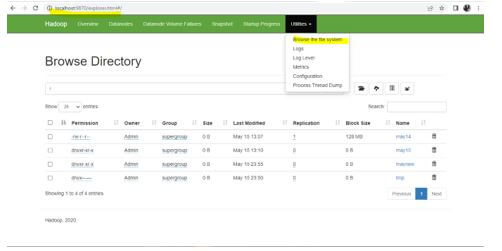
We can select the file directory in the localhost url so that we can choose the may14 directory.
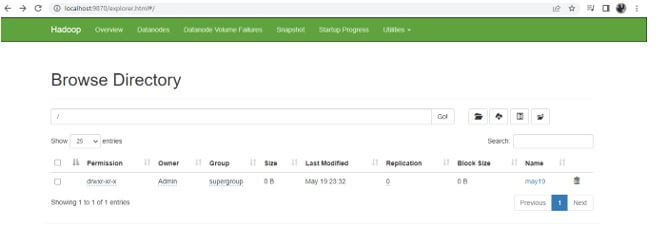
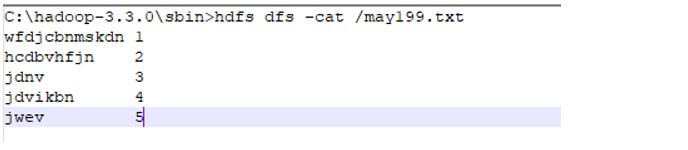
Created a new directory called may19 by using the below hdfs command.

First.java:
Code:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
public class first extends MapReduceBase implements
Mapper<LongWritable,Text,Text,IntWritable>{
private final static IntWritable vars = new IntWritable(3);
private Text vars1 = new Text();
public void firsts(LongWritable lw, Text tx,OutputCollector<Text,IntWritable> outs,
Reporter rep) throws IOException{
String str = value.toString();
StringTokenizer tk = new StringTokenizer(str);
while (tk.hasMoreTokens()){
vars1.set(tk.nextToken());
output.collect(vars1, vars);
}
}
}Second.java:
Code:
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
public class second extends MapReduceBase implements Reducer<Text,IntWritable,Text,IntWritable> {
public void rdss(Text tx, Iterator<IntWritable> values,OutputCollector<Text,IntWritable> out,
Reporter reporter) throws IOException {
int vars2=0;
while (values.hasNext()) {
vars2+=values.next().get();
}
out.collect(tx,new IntWritable(vars2));
}
}Then we create the jar files of the above two java classes by using the below command:
![]()
Finally, we will check the word count of the specified file by using the cat command:
Conclusion
The hdfs file system has many default concepts and features to perform big data operations in real-time applications. Like word count is the type of tool that can count the characters of the user inputs files; it may be of any file format.
Recommended Articles
This is a guide to Hadoop WordCount. Here we discuss the introduction and how to run Hadoop WordCount with commands and web pages. You may also have a look at the following articles to learn more –
