Updated March 4, 2023

Definition of Hashing in Data Structure
Hashing is the process of mapping large amounts of information to a smaller table with the assistance of hashing function. Hashing is otherwise called Hashing Algorithm or Message Digest Function. It is a procedure to change a range of key qualities into a range of records of an array.
Hashing permits to refresh and recover any information section in less time. Steady time implies the activity doesn’t rely upon the size of the information. Hashing is utilized with a database to empower things to be recovered all the more rapidly. It is utilized in the encryption and decryption of advanced and digital signatures.
How Hashing Works in a Data Structure?
A fixed procedure changes over a key to a hash key and is known as a Hash Function. This function takes a key and guides it to an estimation of a specific length which is known as a Hash Value or Hash. This Hash Value is the real string of characters, yet it is typically slightly small than the original one. It moves the computerized or digital signature and afterward, both hash value and signature are sent to the beneficiary. The recipient utilizes a similar hash capacity to produce the hash value and afterward contrasts it to the message In the event that the hash value is the same, the message is transmitted without mistakes.
Hashing is executed in two stages:
An Element is changed over into an integer by utilizing a hash function. This element can be utilized as a list to store the real element, which falls into the hash table. The element is stored in the hash table where it tends to be immediately recovered utilizing a hashed key.
hash = hashfunc(key)
index = hash % array size
In this strategy, the hash is independent of the array size and it is then diminished to a list or index (a number among 0 and array size − 1) by utilizing the modulo operator (%).
Hashing Algorithm: Core to Hashing?
As we talked about, a hash work lies at the core of a hashing algorithm. The hash value is calculated after the data is partitioned into different blocks. This is on the grounds that a hash function takes in information at a fixed-length. These squares are called ‘data blocks.’ This is exhibited in the picture underneath.
The choice of size of the data blocks depends on the scenario where the algorithm needs to be applied. For instance, SHA-1 takes in the message/information in blocks of 512-bit. In this way, if the message is actually of 512-bit length, the hash work runs just a single time (80 rounds if there should be an occurrence of SHA-1).
Notwithstanding, 99 percent of the time, the message won’t be in the products of 512-bit. For such cases (practically all cases), a procedure called padding is used. By this padding strategy, the whole message is isolated into fixed-size information squares or data blocks.
According to the Avalanche effect, the blocks are processed each in turn. The output from data blocks is passed to the next blocks as input. Subsequently, the second data block is fed as input to the subsequent. In this way, we are making the last yield the consolidated output of the considerable number of blocks. In the event that you change the slightest bit anyplace in the message, the whole hash value changes.
Various Hashing Algorithms available are :
- Message Digest (MD) Algorithm
- Secure Hash Algorithm (SHA)
- RACE Integrity Primitives Evaluation Message Digest (RIPEMD)
- Whirlpool
- RSA
Example of Hashing
FUNCTION OF HASH
From subject to an integer
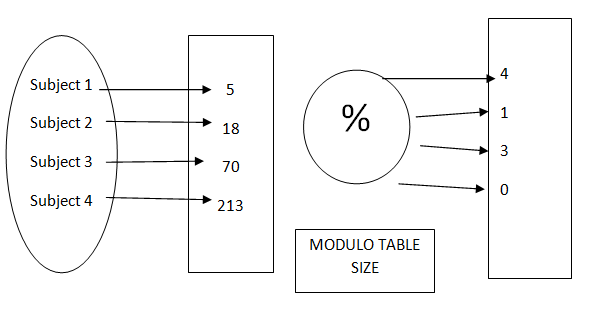
Consider the above example for where we will use hashing to map different employees in different blocks partitioning based on their employee id as a key.
The procedure of storing objects utilizing the function of hash.
Make a size S array. Pick a function h, those maps from the subjects into numbers from 0 to 1 less of the array size S. Now mark these articles in an array at indices figured by means of the function index = h (subject). This kind of cluster array is known as a table of hash or hash table.
How We Must Chose a Hash Function?
One must chose a hash function wisely to avoid collisions while allocating different blocks to the elements in the hash table.
One example of such function can be – p(k) = floor (n*k /r)
Where n, r can be any random numbers and k is the key for function p.
Example:
def display_employee(data):
for i in range(len(data)):
print(i, end = " ")
for j in data[i]:
print("-->", end = " ")
print(j, end = " ")
print()
empTable = [[] for _ in range(10)]
def methHashing(key):
return key % len(empTable)
# Insert Function to add
# values to the hash table
def insert(empTable, key, num):
myHashKey = methHashing(key)
empTable[myHashKey].append(num)
# Driver Code
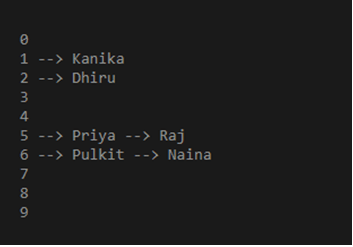
insert(empTable, 125, 'Priya')
insert(empTable, 145, 'Raj')
insert(empTable, 101, 'Kanika')
insert(empTable, 102, 'Dhiru')
insert(empTable, 156, 'Pulkit')
insert(empTable, 136, 'Naina')
display_employee(empTable)
Output:
Conclusion – Hashing in Data Structure
Taking everything into consideration is a helpful means which checks that the information is duplicated accurately between two resources. It can likewise check if the information is indistinguishable without opening and contrasting them. You use hashing fundamentally for the recovery of things in a database as it makes it quicker to discover the thing utilizing a short hash key than to find it utilizing the original value.
Hashing guarantees that the messages during transmission are not altered and in this manner assumes a crucial role in the information security framework. It is additionally used to encode and decode advanced marks and digital signatures utilizing hashcodes. You can likewise make huge benefits through data monetization by coding your algorithm and using an array for node storage.
Recommended Articles
This is a guide to Hashing in Data Structure. Here we also discuss the definition and how hashing works in a data structure? along with how we must chose a hash function?. You may also have a look at the following articles to learn more –
