Updated June 28, 2023

Introduction to Big Data and Hadoop
Data is growing exponentially every day, and with such growing data comes the need to utilize those data. Like in older days, we used to have floppy drives to store data, and data transfer was also slow, but nowadays, these are insufficient, and cloud storage is used as we have terabytes of data. In today’s world, we have social media contributing the highest in data growth. It consists of people’s behavior, mindset, and several other aspects. It is said that in every minute, 300 hours of video is uploaded on YouTube, over 20 million photos are uploaded on Facebook and many others. Moreover, there is no proper structure of the data being uploaded which is the biggest challenge for processing those data.
As enormous data is being generated at high velocity, traditional RDBMS systems were not able to handle such fast-paced growth. Moreover, they are also not capable of handling unstructured data. It became very difficult to handle such a huge amount of heterogeneous data growing rapidly and to process these data with high processing speed. Thus, came a need for such a system that is capable of handling large dataset efficiently. Hence, to solve the scenario, Hadoop came into existence. HDFS is the component of Hadoop that addressed the storage issue of the large dataset by using distributed storage, while YARN is the component that addressed the processing issue bringing down the processing time drastically.
Hadoop is an open-source software framework for storing and processing big data sets using a distributed large cluster of commodity hardware. It was developed by Doug Cutting and Michael J. Cafarella and licensed under Apache. It is written using Java and was developed based on the paper written by Google on the MapReduce system, and it applies concepts of functional programming. It is reliable, economical, flexible, and scalable.
The Core Components of Hadoop
The core components are as follows
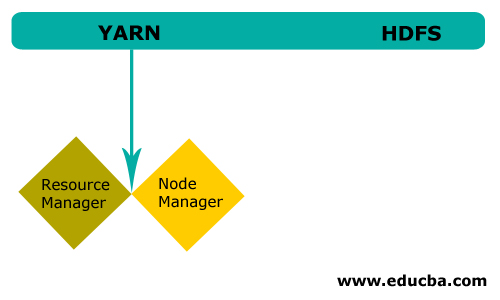
HDFS
HDFS or Hadoop Distributed File System have Namenode and data node. Namenode is the master node running the master daemon, and it manages the data nodes and keeps track of all operations. Datanodes are the slaves where the data is actually stored.
YARN
YARN consists of two main components:
1. ResourceManager: It runs on the master node and manages all resources, and schedule all applications. It has Scheduler & ApplicationManager.
2. NodeManager: It runs on each slave node and is responsible for managing containers and monitoring resource utilization.
Several Components of Hadoop
There are several components like the pig, hive, sqoop, flume, mahout, oozie, zookeeper, HBase, etc.
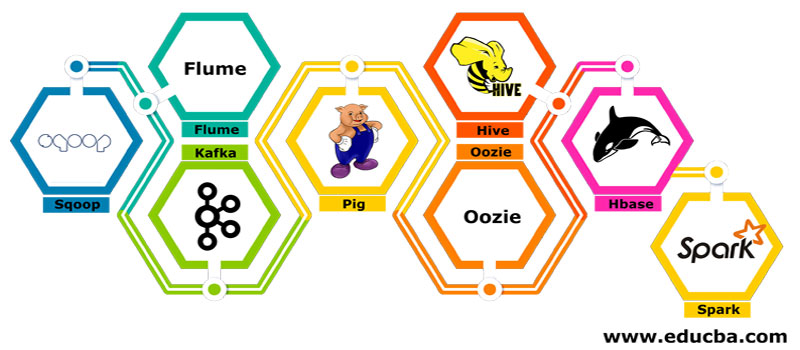
- Sqoop – It is used to import and export data from RDBMS to Hadoop and vice versa.
- Flume – It is used to pull real-time data into Hadoop.
- Kafka – It is a messaging system used to route real-time data.
- Pig – It is used as a scripting language for data processing.
- Hive – It is a data warehousing framework build on HDFS so that users familiar with SQL can execute queries to get the data. These queries are called HiveQL.
- Oozie – It is used to schedule the workflow of jobs to run on specified events or times.
- Hbase – It is the no SQL database provided as part of Apache Hadoop.
- Spark – It is used to perform in-memory processing, which is much faster than Hadoop map-reduce.
Hadoop Providers
There are lots of companies offering Hadoop distributions.
Below are the few best providers:
- Cloudera
- Hortonworks
- MapR
There are a few pre-requisites for learning Hadoop. Prior experience in Java and scripting language is necessary. Although it already has its own high-level programming languages like pig and hive that generate the backend code for further processing, still it is possible to create its own map-reduce program in any programming language like Ruby, Python, Perl, and even C programming.
Bigdata and Hadoop are in high demand in today’s market. This is going to increase more in the coming days. Lots of organizations have already moved into Hadoop and those who have not are going to move soon. There is a current report stating that major corporations have started investing in big data analytics. Big data marketing forecast is always in the upward trend, and it is not at all a short-lived state. Apart from all these, the jobs in Hadoop and big data are always offering high pay as compared to other technologies.
Top Big Data and Hadoop Companies
Below are a few top companies employing the most number:
- Yahoo
- Amazon
- Royal Bank of Scotland
- British Airways
- Expedia
- Walmart
There are a lot of companies using big data applications. These are:
Nokia
It uses Cloudera and Hadoop components like HDFS, HBase, Sqoop, Scribe for the application. It used user data effectively to understand and improve the user’s experience. It uses data processing and complex analyses for building the map with predictive traffic and layered elevation models.
SAS
It has collaborated with Hadoop to help data scientists to gain better insight by providing an environment that gives visual and interactive experience, thus helping to explore new trends. The analytical programs extract meaningful insights from data, and the in-memory technology helps faster data access.
There are also lots of other companies using big data platforms for various analysis. These are flights data analysis of the black box in the aviation industry, the different analysis in the share market, etc.
Advantages of Hadoop
Below are a few of the advantages of Hadoop:
- Scalable – Unlike traditional RDBMS, it is a highly scalable platform as it can store large datasets in distributed clusters over commodity hardware operating in parallel.
- Cost-effective –The cost was too high for RDBMS to store data which has been relieved in Hadoop.
- Fast and flexible – It offers data to be accessed in a fast manner over its distributed file system. It also offers to derive business insights from semi-structured and unstructured data.
- Fault-tolerant – Whenever any data is sent to a node, the same data is replicated into other nodes, which can be accessed in case of any failure of the first node.
Conclusion – What is big data and Hadoop
Data is continuously growing, and hence there is always going to be a need for big data and Hadoop to make sense out of those data. For this reason, professionals with Hadoop skills will always find ample opportunities in the coming days and can be a vital asset for an organization boosting the business and their career.
Recommended Articles
This has been a guide on what is Big Data and Hadoop. Here we have discussed the basic concepts and Components of Big Data and Hadoop. You may also look at the following article to learn more –

