Updated March 15, 2023
Difference between Big Data and Machine Learning
Big data analytics is the process of collecting and analyzing a large volume of data sets (called Big Data) to discover useful hidden patterns and other information like customer choices, and market trends that can help organizations make more informed and customer-oriented business decisions. Big data is a term that describes the data characterized by 3Vs: the extreme volume of data, the wide variety of data types, and the velocity at which the data must be processed. Big data can be analyzed for insights that lead to better decisions and strategic business moves.
Machine learning is a field of AI (Artificial Intelligence) by using which software applications can learn to increase their accuracy for the expecting outcomes. In layman’s terms, Machine Learning is the way to educate computers on how to perform complex tasks that humans don’t know how to accomplish. Machine Learning field is so vast and popular these days that there are a lot of machine learning activities happening in our daily life and soon it will become an integral part of our daily routine.
So, have you noticed any of these machine learning activities in your everyday life?
- You know those movie/show recommendations you get on Netflix or Amazon? Machine learning does this for you.
- How does Uber/Ola determine the price of your cab ride? How do they minimize the wait time once you hail a car? How do these services optimally match you with other passengers to minimize detours? The answer to all these questions is Machine Learning.
- How can a financial institution determine if a transaction is fraudulent or not? In most cases, it is difficult for humans to manually review each transaction because of its very high daily transaction volume. Instead, AI is used to create systems that learn from the available data to check what types of transactions are fraudulent.
- Ever wondered what’s the technology behind the self-driving Google car? Again the answer is machine learning.
Now we know what Big Data vs Machine Learning is, but to decide which one to use at which place we need to see the difference between both.
Head to Head Comparison between Big Data and Machine Learning
Below is the top 8 Difference Between Big Data and Machine Learning:
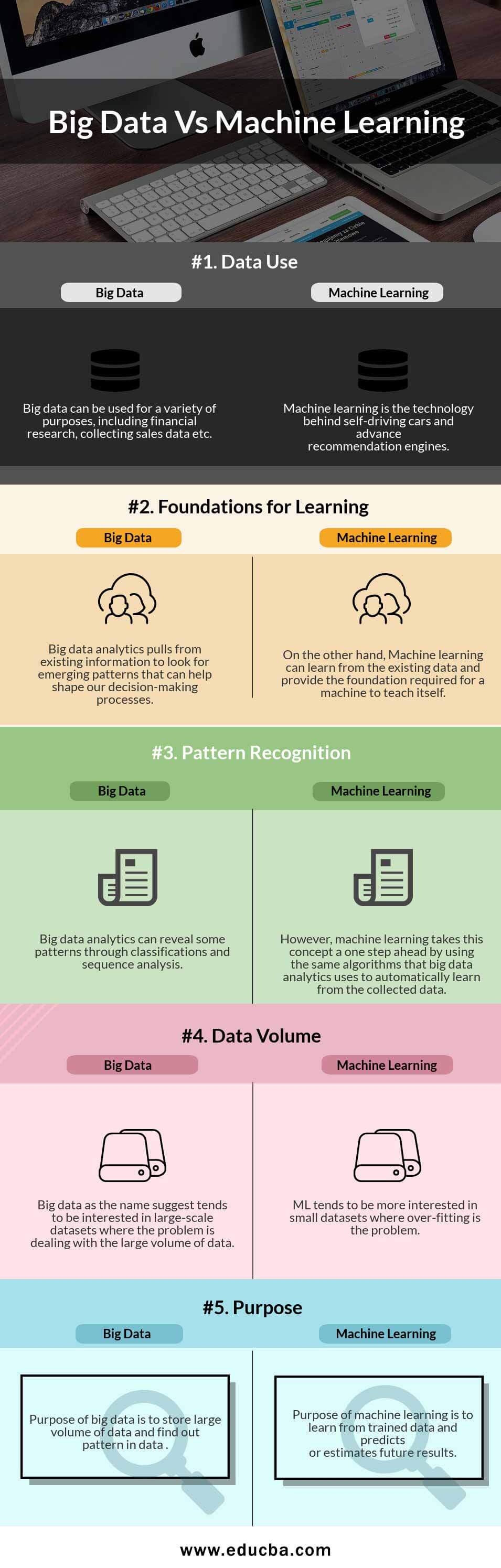
Key Differences Between Big Data and Machine Learning
Following is the key difference between Big Data and Machine Learning:
Both data mining and machine learning are rooted in data science. They often intersect or are confused with each other. They superimpose each other’s activities and the relationship is best described as mutualistic. It is impossible to see a future with just one of them. But there are still some unique identities that separate them in terms of definition and application. Here’s a look at some of the differences between big data and machine learning and how they can be used.
- Usually, big data discussions include storage, ingestion & extraction tools commonly Hadoop. Whereas machine learning is a subfield of Computer Science and/or AI that gives computers the ability to learn without being explicitly programmed.
- Big data analytics as the name suggest is the analysis of big data by discovering hidden patterns or extracting information from it. So, in big data analytics, the analysis is done on big data. Machine learning, in simple terms, is teaching a machine how to respond to unknown inputs and give desirable outputs by using various machine learning models.
- Though both big data and machine learning can be set up to automatically look for specific types of data and parameters and their relationship between them big data can’t see the relationship between existing pieces of data with the same depth that machine learning can.
- Normal big data analytics is all about extracting and transforming data to extract information, which then can be used to fed to a machine learning system in order to do further analytics for predicting output results.
- Big data has got more to do with High-Performance Computing, while Machine Learning is a part of Data Science.
- Machine learning performs tasks where human interaction doesn’t matter. Whereas, big data analysis comprises the structure and modeling of data which enhances decision-making system so require human interaction.
Big Data and Machine Learning Comparison Table
Below is the comparison table between Big Data vs Machine Learning.
| Basis For Comparison | Big Data | Machine Learning |
| Data Use | Big data can be used for a variety of purposes, including financial research, collecting sales data etc. | Machine learning is the technology behind self-driving cars and advance recommendation engines. |
| Foundations for Learning | Big data analytics pulls from existing information to look for emerging patterns that can help shape our decision-making processes. | On the other hand, Machine learning can learn from the existing data and provide the foundation required for a machine to teach itself. |
| Pattern Recognition | Big data analytics can reveal some patterns through classifications and sequence analysis. | However, machine learning takes this concept a one step ahead by using the same algorithms that big data analytics uses to automatically learn from the collected data. |
| Data Volume | Big data as the name suggest tends to be interested in large-scale datasets where the problem is dealing with the large volume of data. | ML tends to be more interested in small datasets where over-fitting is the problem |
| Purpose | Purpose of big data is to store large volume of data and find out pattern in data | Purpose of machine learning is to learn from trained data and predicts or estimates future results. |
Future of Big Data vs Machine Learning
By 2020, our accumulated digital universe of data will grow from 4.4 zettabytes to 44 zettabytes, as reported by Forbes. We’ll also create 1.7 megabytes of new information every second for every human being on the planet.
We’re just scratching the surface of what big data and machine learning are capable of. Instead of focusing on their differences, they both concern themselves with the same question: “How we can learn from data?” At the end of the day, the only thing that matters is how we collect data and how can we learn from it to build future-ready solutions.
Recommended Articles
This has been a guide to Big Data and Machine Learning. Here we have discussed Big Data and Machine Learning head to head comparison, key difference along with infographics and comparison table. You may also look at the following articles to learn more –
