Updated May 22, 2023

Difference Between Text Mining vs Text Analytics
The following article provides an outline for Text Mining vs Text Analytics. Structured data has been out there since the early 1900s, but what made text mining and text analytics so special is leveraging the information from unstructured data (Natural Language Processing). Once we can convert this unstructured text into semi-structured or structured data, it will be available to apply all the data mining algorithms. Ex. Statistical and machine learning algorithms.
Even Donald Trump was able to leverage the data and convert it to information that helped him to win the US presidential elections; well, basically, he didn’t do it. His subordinates did. There is an excellent article out there https://fivethirtyeight.com/features/the-real-story-of-2016/. You can go through it.
Many businesses have started using text mining to use valuable inputs from the text available; for example, a product-based company can use Twitter data/ Facebook data to know how well or bad their product is doing in the world using Sentimental Analysis. In the early days, the processing used to take a lot of time, days, to process or even implement the machine learning algorithms, but with the introduction of tools such as Hadoop, Azure, KNIME, and other big data processing software the text mining has gained enormous popularity in the market. Amazon’s Recommendation engine is one of the best examples of text analytics using association mining, which automatically gives customers recommendations on what else other people buy when buying any particular product.
Making it is one of the biggest challenges of applying text mining tools to something not in a digital format/ on a computer drive. The old archives and many vital documents available only on paper are sometimes read through OCR (Optical Character Recognition), which has many errors. Sometimes data is entered manually, which is prone to human mistakes. We want these because we may be able to derive other insights that are not visible from traditional reading.
Some of the steps of text mining are as below:
- Information Retrieval
- Data Preparation and Cleaning
- Segmentation
- Tokenization
- Stop-word Numbers and Punctuation Removal
- Stemming
- Convert to Lowercase
- POS Tagging
- Create Text Corpus
- Term-Document Matrix
And below are the steps in Text Analytics that are applied after the Term Document Matrix is prepared.
- Modeling (This may include inferential models, predictive models, or prescriptive models)
- Training and Evaluation of Models
- Application of these Models
- Visualizing the Models
The only thing one must never forget is that text mining always precedes text analytics.
Head-to-Head Comparison Between Text Mining vs Text Analytics (Infographics)
Below are the top 5 comparisons between Text Mining vs Text Analytics:

Key Differences Between Text Mining vs Text Analytics
Let’s differentiate text mining vs text analytics based on the steps which are involved in a few applications where these text mining and text analytics both are applied:
Classification of documents: Text mining includes steps such as tokenization, stemming and lemmatization, removal of stopwords and punctuation, and computation of term frequency or document frequency matrices.
- Tokenization: The process of splitting the whole data (corpus) into smaller chunks or smaller words, usually single words, is known as tokenization (N-Gram model or Bag of Words Model).
- Stemming and Lemmatization: For example, the words big bigger, and biggest all mean the same, and it will form duplicate data, to keep the data redundant, we do lemmatization, linking words with the root word.
- Removing stop words: Stop words are not used in analytics, including words like is, the, etc.
Term frequencies: This matrix has row headers as the document names and columns as the terms(words), and the data is the frequency of the words occurring in those particular documents.
Below is a sample screenshot.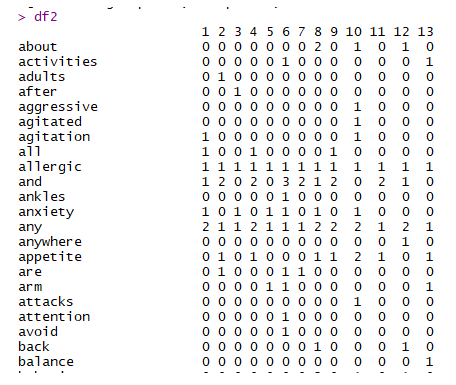
The above figure shows the attributes in the rows (words), the document number as columns, and the word frequency as the data.
Now coming to text analytics, we have the following steps that need to be considered:
- Clustering: Using K-means clustering/Neural Networks/ CART(Classification and regression trees) or any other clustering algorithm, we can cluster the documents based on the generated features (features here being the words).
- Evaluation and visualization: We can plot the cluster into two dimensions and look at how these clusters vary from each other, and if the model holds good on test data, we can deploy it in production, and it will be a good document classifier which will classify any new documents which are given as input, and it would just name the cluster in which it will fall into.
Sentiment Analysis
One of the most powerful tools out there in the market to help in processing Twitter data/ Facebook data, or any other data which can be used to derive the sentiment out of it, whether the sentiment is good, bad, or neutral to any particular process/product or person is sentiment analysis.
The source of the data can easily be available by using Twitter API / Facebook API to get the tweets/comments/likes etc., on the tweet or a post of a company. The major problem is this data is hard to structure. The data would contain various advertisements, too. The data scientist who works for the company must ensure the data selection is made correctly so that only selected tweets/posts go through pre-processing stages.
Other tools include Web- Scraping, a part of text mining wherein you scrap the data from websites using crawlers.
The process of text mining remains the same as tokenization, stemming, and lemmatization, removing stopwords and punctuation, and finally, computing the term frequency matrix or document frequency matrices. Still, the only difference comes while applying the sentiment analysis.
Usually, we give a score to any post/tweet. When you purchase and review a product, you can provide stars and post a comment. Google, Amazon, and other websites use the stars to rate the comment; not only this, but they also take the tweets/posts and give them to human beings to rate them as good/bad/neutral, and on combing these two scores, they generate a new score to any particular tweet/post.
One can use a word cloud and bar charts of the frequency term matrix to visualize sentiment analysis.

Association of Mining Analysis
One of the applications on which some guys were working was the “Adverse Drug Event Probabilistic model,” wherein one can check for which adverse events may cause other adverse events if he takes any particular medicine.
The text mining included the below workflow.
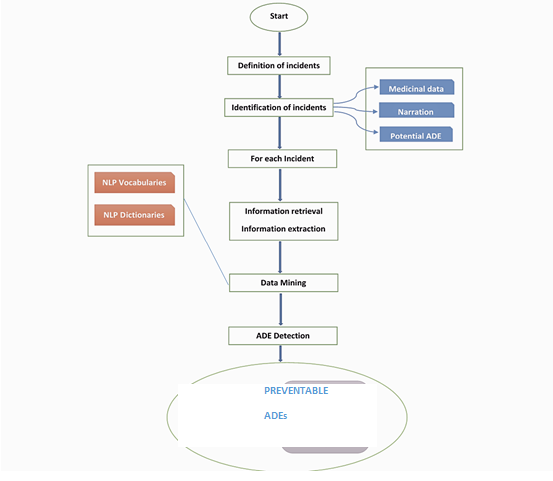
From the above figure, we can see that till data-mining, all steps belong to text mining which is identifying the source of data, extracting them, and then preparing it to be analyzed.
Then applying association mining, we have the below model. We can see that some arrow marks point toward the orange circle, and then one arrow points toward any particular ADE (Adverse drug event). Let’s take an example on the left bottom side of the image. We can find apathy, asthenia, and feeling abnormal leads to feeling guilty; well, one can say that’s obvious because, as a human, you can interpret and relate. Still, here a machine is interpreting it and giving us the next adverse drug event.
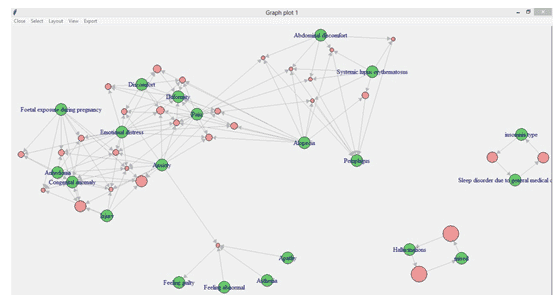
An example of the word cloud is as below:

Text Mining vs Text Analytics Comparison Table
Below are the lists of points that describe the comparisons between Text Mining vs Text Analytics:
| Basis for Comparison | Text Mining | Text Analytics |
|
Meaning |
Text mining is cleaning up data to be available for text analytics. | Text Analytics applies statistical and machine learning techniques to predict /prescribe or infer any information from text-mined data. |
|
Concept |
Text mining is a tool that helps to clean up data. | Text Analytics is the process of applying the algorithms. |
|
Framework |
If we talk about the framework, text mining is similar to ETL(Extract Transform Load), which means to be able to insert data into a database, these steps are carried out. | In-text analytics, this data is used to add values to the business, for example, creating word clouds, bi-grams frequency charts, and N-grams in some cases. |
|
Language |
Python and R are the most famous text-mining tools for text mining. | For text analytics, once the data is available at the database level, we can use any analytics software out there, including Python and R. Other software include Power BI, Azure, KNIME, etc. |
|
Examples |
|
|
Conclusion
The future of text mining and text analytics involves continuous advancements in linguistic tools, which are not limited to English alone, but are also used for analysis in other languages. Limited resources to analyze other languages will drive the growth of the scope and future of text mining.
Text Analytics has an extensive range of where it can be applied; some of the examples of industries where this can be used are:
- Social Media Monitoring
- Pharma/Biotech Applications
- Business and Marketing Applications
Recommended Articles
This is a guide to Text Mining vs Text Analytics. Here we have discussed Text Mining vs Text Analytics head-to-head comparison, key differences, and infographics. You may also look at the following articles to learn more –
