Updated September 2, 2023

Table of Contents
Introduction to Hive Database
Hive Databases provides the facility to store and manage huge records or datasets on top of a distributed Hadoop platform. It can store structured and semi-structured data. With JDBC Driver’s help, the end-user can connect with the Hive database and fetch the data/records with the support of SQL Query. In the Hive, the database framework is developed by Facebook to analyze structured data or semi-structured data. The database framework supports all the regular commands like create, drop, alter, and use database.
We can also use the database layer with different Hadoop components like Hbase, Kafka, Spark, various streaming tools, etc.
Syntax
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database name
[COMMENT 'database information | database comment' ]
[LOCATION ' HDFS Path' ]
[WITH DATABASE PROPERTIES (property name= property value, ...)];How to Create a Database in Hive?
We can create a database similar to the SQL one. But the major thing is whether the tables are created in the internal table format or external table format. If all the tables are created in the internal table format, the database is also called an internal database. If all the tables are created in an external table format, the database is also called an external database. In the database, the data is stored in a tabular manner. The default storage location of the hive database varies from the hive version. From HDP 3.0, we are using version 3.0 and more. The default database location was changed. The location for the external hive database is “/warehouse/tablespace/external/hive/” and the location for the manage database is “/warehouse/tablespace/managed/hive”.
In the older version of the Hive, the Hive database’s default storage location is “/apps/hive/warehouse/”.
Query to Create Hive Database
To create a database, you can utilize the CREATE DATABASE instruction in HiveQL. Here’s an example:
Query
create database organization;Output
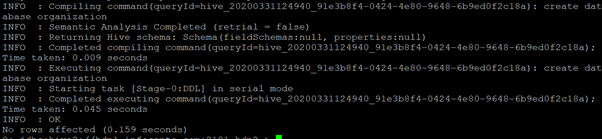
When accessing the Hive DB, you must establish the connection between the Hive client and server. To establish the connection, we need to configure the Hive JDBC/ODBC connection string in the hive client and establish the hive server’s connection. We can connect with the database with the help of Hive View, Hive CLI, Beeline(interactive and non-interactive), or different third-party client software.
Note
- JDBC and ODBC are two different ways to connect with Hive. Few applications like MSTR support ODCB connection only. We need to configure the MSTR “ini” file. Few applications, like Zeppelin and Squirrel client, support the JDBC connection.
- With the help of Knox Gateway, we can connect with the Database.
- Hive View is only available in Ambari 2.6 or less. From version 2.7 and above, Hive view is not available.
How to Modify or Alter Hive Database?
We can modify the database, including comments and properties. We can also alter the database as below.
Alter in Database Properties
When using Hive, you can change various configuration settings related to a database by altering its properties. This includes modifying its description, location, and ownership. By altering database properties, you can effectively manage and organize your databases while keeping metadata and access control intact.
Example
ALTER(DATABASE | SCHEMA) database name SET database properties (property name = property value, ...);Alter the Owner
In a database or data management system, altering the owner refers to changing the user or entity with administrative control and permissions over a particular database or object. This process allows for transferring ownership rights, enabling a different user or entity to manage and access the database’s contents, often for administrative or security reasons.
Example
ALTER (DATABASE| SCHEMA) database name SET OWNER [USER|ROLE ] user or role;Alter the HDFS Location
If you need to change the HDFS location of a Hive table, you can use the ALTER TABLE statement with the SET LOCATION clause. Include the new HDFS path where you want to store the table’s data. This will move the data to the new location and update the table’s location metadata. You can then reorganize or relocate the data as needed, and Hive will query the table from the updated location.
Example
ALTER (DATABASE|SCHEMA ) database name SET LOCATION HDFS Path;Hive Query to Alter Database
In Hive, you cannot directly alter a database using an ALTER DATABASE statement as you would with tables. Instead, you typically work with tables within a database. To modify a database’s properties or permissions, you must use administrative actions outside of Hive, such as modifying the database directory or changing the Hadoop file system-level permissions. It primarily focuses on altering tables, partitions, and other objects within a database.
Query
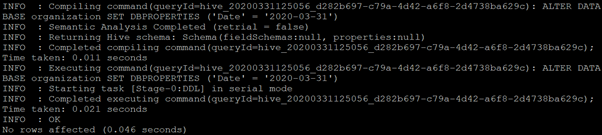
ALTER DATABASE organization SET DBPROPERTIES ('Date' = '2020-03-31');Output
How to Drop Database in Hive?
We can drop or delete the database form from the Hive system in the Hive. By default, there is a restriction on the drop database command. We cannot drop the existing database with the subject to the database is empty. If the database is empty, then only we can drop the database. If we have the tables in the database, then there is a restriction on the drop. There are two ways to drop the database having the tables in it.
- First Way: We must drop all the tables in the current database. Then, we can drop the current hive database.
- Second Way: If we want to drop the hive database without the current tables. Then, we can use the “CASCADE” keyword in the drop query. With the help of “CASCADE”, we can drop the hive database without touching the database’s internal tables.
Hive Drop Query with Empty Database
In Hive, when you issue a DROP DATABASE query for an empty database, the database is deleted without any issues. Hive will remove the empty database and all associated metadata, leaving no data or objects behind. This straightforward operation doesn’t result in data loss or complications since there’s no data to remove.
Query
drop database organization;Output
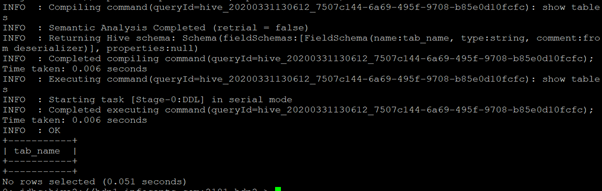
The above shows that the hive database “organization” is empty. We can easily drop the database using a hive query.
Hive Drop Query with Table Contain
A “DROP TABLE” query permanently removes a table and its associated data from the database in Hive. Executing a “DROP TABLE” query with a table name deletes the table, metadata, and data files, freeing up storage space. This operation is irreversible; It’s essential to exercise caution when using this function and ensure that the necessary permissions are in place before execution.
Query
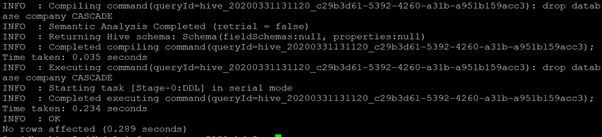
drop database company CASCADE;Output
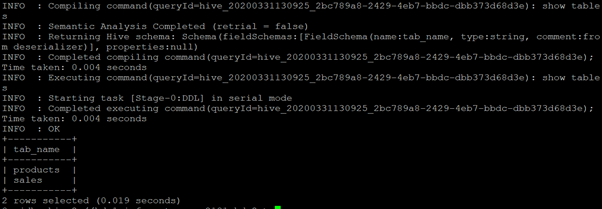
As per the above screenshot, we can see the “company” DB has two tables. (table1: products and table2: sales).
Suppose we use the drop command “drop database company;” to drop the company DB. Then the command will not work due to tables are present in it.
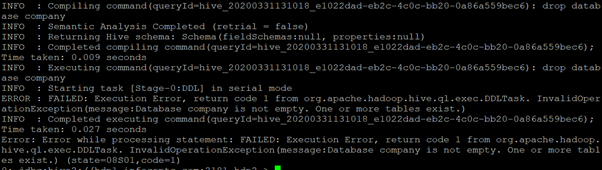
We can drop the database when we use the “CASCADE” keyword in the query.
Conclusion
We have seen the uncut “Hive Database” concept with the proper example, explanation, syntax, and SQL Query with different screenshots. This framework resides on top of Hadoop. It will summarize the huge datasets/records and do querying on them. Helpful for easy analysis on top of it. If the datasets increase, we can add the number of machines without impacting the performance.
FAQs
Q1. Is Hive a SQL language?
Ans: Hive uses a SQL-like query language called HiveQL. While not identical to traditional SQL, it provides a familiar syntax for querying and managing data stored in Hive tables. Users can write queries using HiveQL to interact with large-scale data in the Hadoop Distributed File System (HDFS) without requiring a predefined schema, making it accessible to those familiar with SQL.
Q2. Is Hive an ETL tool?
Ans: Hive is mainly used for data warehousing and querying large datasets in a Hadoop environment, using SQL-like operations to manipulate data. However, it does not offer the advanced data transformation and workflow management features in specialized ETL tools. Hive is best for querying and reporting on data rather than carrying out complete ETL processes.
Recommended Articles
We hope that this EDUCBA information on the “Hive Database” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
