Updated March 22, 2023
Introduction to Hive Group By
Group By as the name suggests it will group the record which satisfies certain criteria. In this article, we will look at the group by HIVE. In legacy RDBMS like MySQL, SQL, etc., group by is one of the oldest clauses used. Now it has found its place in a similar way in file-based data storage famously know as HIVE.
We know that the Hive has surpassed many legacy RDBMS in handling huge data without a penny being spent on vendors to maintain the databases and servers. We need to configure HDFS to handle hive. Generally, we move to tables because the end-user can interpret from its structure and can query upon as files will be clumsy for them. But we had to do this by paying the vendors to provide servers and maintain our data in the format of tables. So Hive provides the cost-effective mechanism where it takes advantage of file-based systems (the way the hive saves its data) and tables (table structure for the end-users to query upon).
Group By
Group by uses the defined columns from the Hive table to group the data. Consider you have a table with the census data from each city of all the states where city name and state name are columns. Now in the query, if we group by states, then all the data from different cities of a particular state will be grouped together, and one can easily visualize the data better now before the way group by was applied.
Syntax of Hive Group By
The general syntax of the group by clause is as below:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition]
[ORDER BY col_list]]
[LIMIT number];
or for simpler queries,
<Select Clause> <rferenced Columns> from <table_name> Group By <The columns on which we want to group the data>
Select department, count(*) from the university.college Group By department;
Here the department refers to one of the college table columns, which is present in the university database, and its value is various in departments like arts, mathematics, engineering, etc. Now let see some example to demonstrate group by.
I have created a sample table deck_of_cards to demonstrate the group by. Its create table statement is as follows:
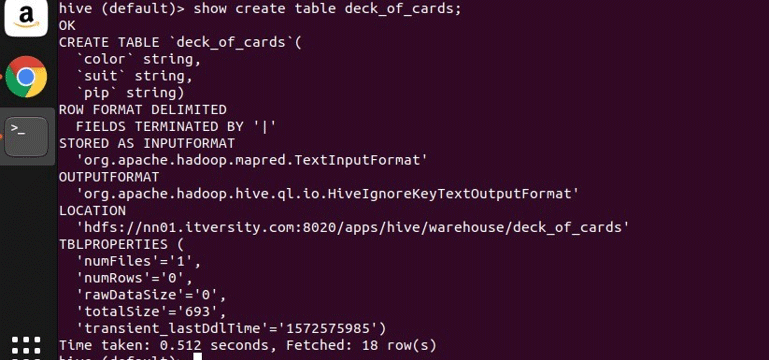
you can see from above that it has three string columns colour, suit, and pip. Let me write a query to group the data by its colour and get its count.
select color, count(*) from deck_of_cards group by color;
Hive basically takes the above query to convert it to the map-reduce program by generating corresponding java code and jar file and then executes. This process may take a bit of time, but it can definitely handle the big data compared to traditional RDBMS. See the below screenshot with the detailed log for executing the above query.
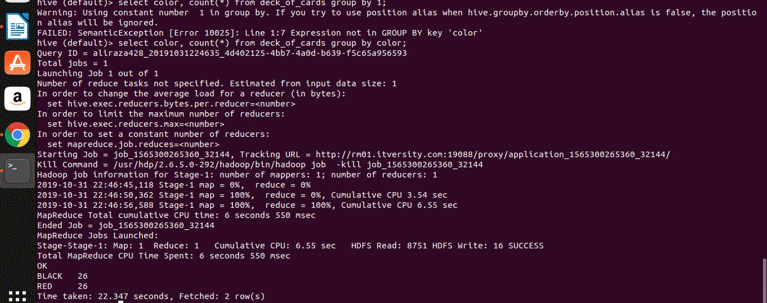
You can see that BLACK is 26 and RED is 26.
Let us apply the grouping on two columns (colour and suit and getting group count) and see the result below.
Select color, suit, count(*) from deck_of_cards group by color, suit
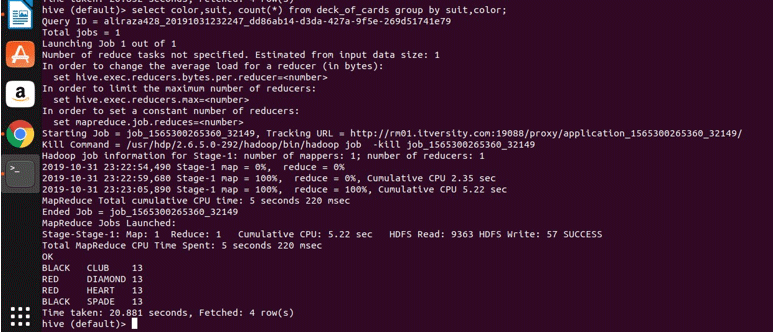
Basically, there are four distinct groups above Club, Spade which have colour black and Diamond and heart, which are colour red.
Storing the Result from Group by Cause in Another Table
Hive also like any other RDBMS provides the feature of inserting the data with create table statements. Let us look at storing the result from a select expression using a group by into another table. Let me use the above query itself where I have used two columns in group by.
create table cards_group_by
as
select color,suit,count(*) from deck_of_cards
group by color,suit;
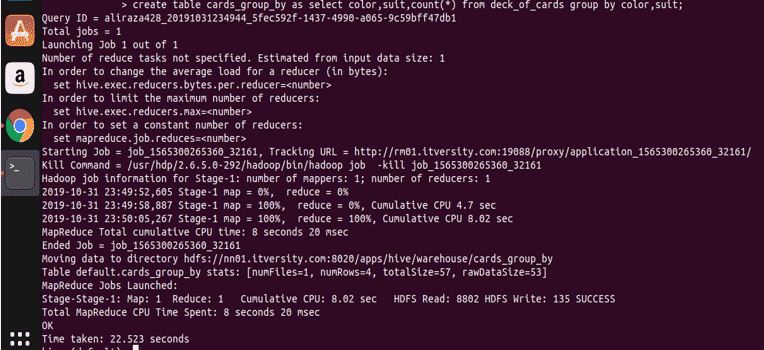
Now let us query upon the created table to see and validate the data.

Now let us restrict the result of the group by using having clause. As shown in the generic syntax, we can apply restriction on the group, by using having. Here I am using the ordser_items table, and its structure is as follows from the describe statement.
hive (retail_db_ali)> describe order_items;
OK
order_item_id int
order_item_order_id int
order_item_product_id int
order_item_quantity tinyint
order_item_subtotal float
order_item_product_price float
Time taken: 0.387 seconds, Fetched: 6 row(s)
select order_item_id, order_item_order_id from order_items group by order_item_id, order_item_order_id having order_item_order_id=5;
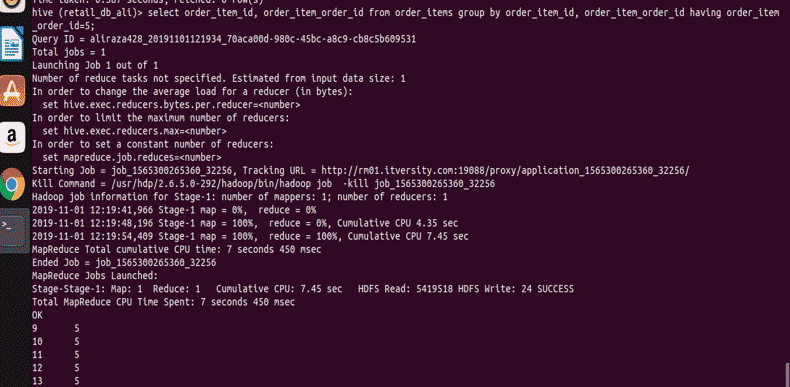
You can see from the result the screenshot that we have records only with order_item_order_id value 5.
Group by Along with Case Statement
Now let us look at bit complex queries involving the CASE statements with the group by. We will apply this to the order_items table. We will see below that we can categorize the nonaggregating columns on which we cannot directly apply the group by clause.
Select
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end
as order_profits,
count(*) from order_items
group by
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end;
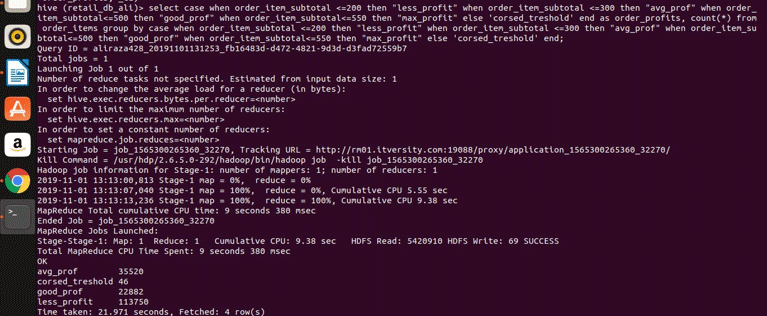
let us execute it in the hive for results
Conclusion
We can see that we have grouped the order_item_subtotal into four different categories (if you note that order_item_subtotal is a non-aggregating column and direct group by cannot be applied on to it). We have grouped them together and got their counts for the values that are satisfying the range as defined in the select expression. Here is the simple rule if the column is nonaggregating. Our select expression is complex, then whatever they’re in the select expression that should also be present in the group by clause expression. So we have seen how a famous clause RDBMS clause group can also be applied to the Hive without any restrictions. It can be applied to simple select expressions. Aggregate and filtering expressions, join expressions and complex CASE expressions as well.
Recommended Articles
This is a guide to Hive Group By. Here we discuss the group by, syntax, examples of the hive group by with different conditions and implementation in detail. You may also look at the following articles to learn more –
