Removing duplicates from a list in Python
Python list is a versatile data structure serving as an ordered element collection. It is mutable, allows easy modification, and supports mixed data types. Accessed by index, it enables slicing and dynamic resizing, making it a fundamental and widely used feature in Python programming for managing and organizing data.

Table of content
- What is a Python list?
- Key Takeaways
- Why remove duplicates from the list?
- Methods to remove Duplicates from a list
Key Takeaways
- Python lists are versatile data structures that allow you to store and manipulate ordered collections of items, providing dynamic resizing and supporting various operations like indexing, slicing, and iteration.
- Python offers various methods to remove duplicates from lists.
- Use Set-based approaches– set() method, collections.OrderedDict.fromkeys(), in, not in operators.
- Use Specialized Libraries and Tools- Counter and FreqDist, Numpy unique method, Pandas DataFrame.
- Use additional methods- list comprehension and Array.index() method, del keyword, for-loop, and dict methods.
Why remove duplicates from the list?
Removing duplicates from a list is crucial in maintaining data accuracy, optimizing code performance, and promoting efficient data handling and analysis.
Removing duplicates from a list is essential for several reasons.
- Efficiency- Eliminating duplicates optimizes code performance by reducing unnecessary iterations and operations, resulting in faster execution.
- Memory Usage- Lists with duplicates consume more memory. Removing them conserves memory resources and promotes efficient data storage.
- Data Integrity– Duplicate entries can lead to data analysis or processing inaccuracies. Removing duplicates ensures the accuracy and reliability of your data.
- Improved Readability- A list without duplicates is cleaner and easier to understand, making the code readable and maintainable for developers.
- Enhanced Analysis- In scenarios like data analysis, duplicate entries can skew results. Removing them ensures accurate and meaningful insights from your data.
- Consistency- Removing duplicates promotes consistency in data handling and prevents unintended consequences that may arise from duplicate entries.
- Optimized Algorithms- Many algorithms and data manipulation operations assume unique inputs. Removing duplicates ensures that these operations function as expected.
- Streamlined Operations- In scenarios such as searching, sorting, or filtering, removing duplicates simplifies these operations and avoids unnecessary redundancy.
Methods to remove Duplicates from a list
Direct Set-based Approaches
1. Using set() method
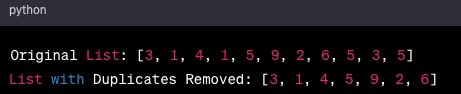
The set() method efficiently removes duplicates from a Python list, automatically eliminating duplicate values due to the unique property of sets. While this approach enhances data integrity and streamlines code, it’s essential to note that it doesn’t preserve the original order of elements.
To maintain the order, convert the resulting setback to a list using the list() method. This method offers a concise solution for scenarios requiring eliminating duplicate entries and optimizing data and code.
For example-
# Original list with duplicates
original_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# Using set() to remove duplicates
unique_set = set(original_list)
# Converting back to the list to maintain the original order
result_list = list(unique_set)
# Displaying results
print("Original List:", original_list)
print("List with Duplicates Removed:", result_list)Output-

2. Using collections.OrderedDict.fromkeys()
To remove duplicate elements from a Python list, use collections.OrderedDict.fromkeys(). This method maintains the original order while filtering out duplicates. The result is an ordered collection of unique values.
For example-
from collections import OrderedDict
# Original list with duplicates
original_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# Applying OrderedDict.fromkeys() to remove duplicates
unique_dict = OrderedDict.fromkeys(original_list)
# Extracting the list of unique elements in the original order
result_list = list(unique_dict.keys())
# Displaying results
print("Original List:", original_list)
print("List with Duplicates Removed:", result_list)Output-

3. Using in, not in operators
To remove duplicates from a list in Python using the “in” and “not in” operators, you can iterate through the original list and selectively add elements to a new list only if they are not already present. This approach ensures a unique collection without duplicates, providing a straightforward and memory-efficient solution for handling duplicate entries in a list.
For example-
# Original list with duplicates
original_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# Remove duplicates using "in" and "not in" operators
unique_list = []
for element in original_list:
if element not in unique_list:
unique_list.append(element)
# Displaying results
print("Original List:", original_list)
print("List with Duplicates Removed:", unique_list)Output-

List Comprehension-based Approaches
1. Using list comprehension
It is a concise method that creates a new list by iterating through the original list and including only elements not already present.
For example-
# Original list with duplicates
original_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# Remove duplicates using list comprehension
unique_list = []
[unique_list.append(x) for x in original_list if x not in unique_list]
# Displaying results
print("Original List:", original_list)
print("List with Duplicates Removed:", unique_list)Output-

2. Using list comprehension with enumerate()
You can also remove duplicates from a list in Python using list comprehension with enumerate(). This approach maintains readability while iterating through the original list. By leveraging the index provided by enumerate(), it selectively includes elements in a new list only if they have yet to occur earlier in the iteration.
For example-
# Original list with duplicates
original_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# Remove duplicates using list comprehension with enumerate()
unique_list = [element for index, element in enumerate(original_list) if element not in original_list[:index]]
# Displaying results
print("Original List:", original_list)
print("List with Duplicates Removed:", unique_list)Output-
Specialized Libraries and Tools
1. Using Counter and FreqDist
The collections module’s Counter class and the nltk library’s FreqDist offer potent tools for actively analyzing and managing the frequency distribution of elements within a collection, such as a list.
The Counter class simplifies counting, creating a dictionary-like structure with elements as keys and their counts as values.
For example-
from collections import Counter
# Original list with duplicates
original_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# Using Counter to count element occurrences
element_counts = Counter(original_list)
# Displaying results
print("Original List:", original_list)
print("Element Counts:", element_counts)Output-
Simultaneously, FreqDist provides additional functionalities, especially in natural language processing tasks. Both methods actively contribute to gaining insights into element distribution, aiding in tasks like identifying common or rare elements and streamlining data preprocessing across diverse domains.
For example-
from nltk import FreqDist
# Original list with duplicates
original_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# Using FreqDist to get the frequency distribution
element_freq_dist = FreqDist(original_list)
# Displaying results
print("Original List:", original_list)
print("Element Frequency Distribution:", element_freq_dist)Output-

2. Using the Numpy unique method
You can leverage the numpy library’s unique method to remove duplicates from a list in Python. This method not only identifies individual elements but also preserves their original order.
For example-
import numpy as np
# Original list with duplicates
original_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# Remove duplicates using numpy's unique method
unique_array = np.unique(original_list)
# Convert the result back to a list
unique_list = unique_array.tolist()
# Displaying results
print("Original List:", original_list)
print("List with Duplicates Removed:", unique_list)Output-

In this example, NumPy’s unique method efficiently removes duplicates from the original list while maintaining the order of individual elements, providing a straightforward and optimized solution.
3. Using a Pandas DataFrame
You can also remove duplicates from a list using the pandas library’s DataFrame. This method identifies unique elements and provides a convenient framework for handling data.
For example-
import pandas as pd
# Original list with duplicates
original_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# Create a DataFrame and use drop_duplicates
unique_df = pd.DataFrame(original_list, columns=['Original'])
unique_df = unique_df.drop_duplicates().reset_index(drop=True)
# Extract the result as a list
unique_list = unique_df['Original'].tolist()
# Displaying results
print("Original List:", original_list)
print("List with Duplicates Removed:", unique_list)Output-

Additional Methods
1. Using list comprehension and Array.index() method
To remove duplicates from a list in Python, you can combine list comprehension and the index() method. This approach creates a new list by iteratively adding elements only if they have not been encountered before.
For example-
# Original list with duplicates
original_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# Remove duplicates using list comprehension and index() method
unique_list = [original_list[i] for i in range(len(original_list)) if i == original_list.index(original_list[i]) ]
# Displaying results
print("Original List:", original_list)
print("List with Duplicates Removed:", unique_list)Output-

2. Using the del keyword
We use the del keyword to remove items from a list based on their index positions. This method is particularly effective for smaller lists with few duplicate elements.
For example-
# Original list with duplicates
original_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# Remove duplicates using the del keyword
index = 0
while index < len(original_list):
element = original_list[index]
if original_list.count(element) > 1:
del original_list[index]
else:
index += 1
# Displaying results
print("Original List:", original_list)Output-
![]()
3. Using for-loop
Using a for-loop involves creating a new empty list and iteratively appending only the first occurrence of each element. This straightforward approach ensures the resulting list contains unique elements while preserving their order.
For example-
# Original list with duplicates
original_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# Using a for-loop to remove duplicates
unique_list = []
for element in original_list:
if element not in unique_list:
unique_list.append(element)
# Displaying results
print("Original List:", original_list)
print("List with Duplicates Removed:", unique_list)Output-

4. Using dict
To remove duplicates from a Python list, employ the dict method. Create a dictionary from the original list, leveraging its unique, essential requirement to eliminate duplicates automatically. This method, utilizing the inherent properties of dictionaries, produces a clean and ordered list without redundant entries, providing a concise and effective solution for enhancing data integrity in list manipulation.
For example-
# Original list with duplicates
original_list = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# Using dict method to remove duplicates
unique_dict = dict.fromkeys(original_list)
# Extracting the result as a list
unique_list = list(unique_dict.keys())
# Displaying results
print("Original List:", original_list)
print("List with Duplicates Removed:", unique_list)Output-

Conclusion
This tutorial explored various techniques for eliminating duplicate elements from a Python list. We discovered that the del keyword is adequate for smaller lists, but methods like for-loops and list comprehension offer better efficiency for more extensive lists. Additionally, we explored the unique property of set values and dictionary keys, making them practical for duplicate removal.
Furthermore, we discussed how dictionary subclasses share a similar approach to dictionaries in removing duplicates. Lastly, we delved into NumPy and Pandas‘ methods, highlighting alternative approaches for obtaining unique elements from a list.
FAQs (Frequently Asked Questions)
Q1. What are lists in Python?
Answer: In Python, a list is a versatile and fundamental data structure used to store a collection of items. Lists are mutable, meaning their elements can be modified after creation. They are ordered, allowing for indexing and slicing to access specific elements. Lists can contain various data types, including numbers, strings, and other lists, making them flexible for multiple applications.
Lists in Python are defined using square brackets [], and commas separate elements within the list.
For example-
my_list = [1, 2, 'apple', 'orange', [3.14, 'pie']]Critical operations on lists include appending, extending, inserting, removing, and slicing elements. Lists provide a dynamic and efficient way to organize and manipulate data, making them a fundamental tool in Python programming.
Q2. Can I modify a Python list while iterating over it using a for loop?
Answer: Modifying a Python list directly while iterating using a for loop can lead to unexpected behavior. To avoid issues, iterate over a copy of the list or use techniques like list comprehension or functions such as filter or map to create a new modified list.
Q3. How can I efficiently check if a specific element exists in a Python list?
Answer: You can use the in keyword to check if a specific element is in a Python list. It returns True if the element is found in the list and False otherwise.
For example-
my_list = [1, 2, 3, 4, 5]
# Check if 3 is on the list
if 3 in my_list:
print("3 is present in the list.")
else:
print("3 is not present in the list.")This method provides a simple and readable way to determine the existence of an element in a list. Additionally, using a set for membership testing may offer better performance for large lists.
Recommended Articles
We hope this EDUCBA information on the “remove duplicates from a list in Python?” benefited you. You can view EDUCBA’s recommended articles for more information.

