Updated November 16, 2023
Introduction to Java XML Parser
The following article provides an outline for Java XML Parser. XML parsing for Java is a stand-alone XML component that parses an XML document (and, in certain cases, a standalone DTD or XML Schema) so that a user program may process it. It may also include an XSL Transformation (XSLT) Processor for XML data transformation using XSL stylesheets. We may convert XML documents from XML to XML, XML to HTML, or nearly any other text-based format with the XSLT Processor.
Table of Contents
- Introduction
- What is XML parsing with Java?
- Syntax of Java XML Parser
- Steps to Using Java XML Parser
- How does Java XML Parser Work?
- Examples of Java XML Parser
What is XML parsing with Java?
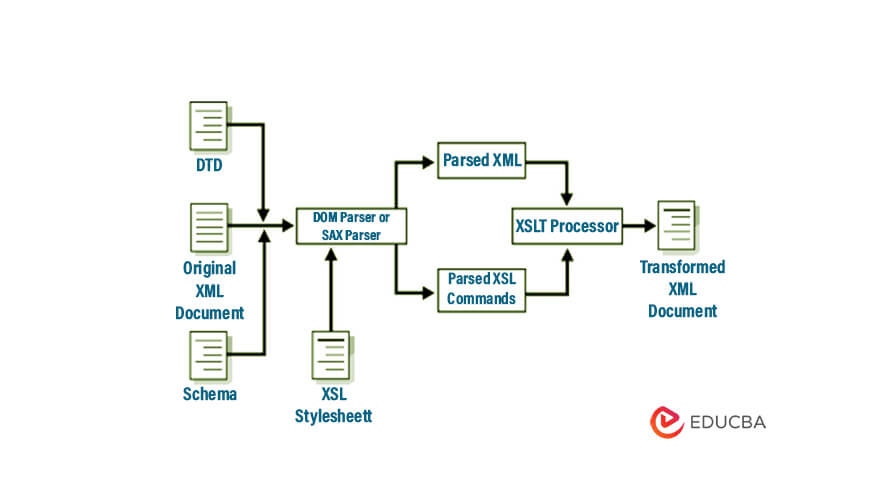
XML parsers are responsible for checking and validating the format of your XML document by scanning throughout the XML file and also providing the functionality to access or modify the data in it. The most important part of the process of development of XML is XML parsing. In Java, the XML parser is a standalone component of XML that helps in parsing DTD standalone files, XML documents, or even XML schema. The user can further process this parsed XML document. The below figure illustrates the process of parsing the XML documents in Java –
https://docs.oracle.com/cd/B25016_08/doc/dl/web/B14033_01/adxdk002.gif
In the above figure, we observe that the parser takes the main XML document ‘t’ as input, along with optional schema files and DTD. The parser generates output and then passes it to the DOM or SAX parser, depending on the chosen input method. The DOM or SAX parser also receives the XSL stylesheet file for designing and beautifying the data. Furthermore, it forwards the commands of parsed XSL, along with the parsed XML, to the XSLT processor, which ultimately produces the transformed XML document as its output.
Syntax of Java XML Parser
The general parsing format is given as:
1. Using DOM
DOMParser parser = new DOMParser();2. Using SAX
Parser parser = new SAXParser();XML (Extensible Markup Language) is a markup language that specifies a set of rules for encoding texts. To parse and process XML documents, Java provides several libraries. Java xml parser examples provide the essential functionality to read and change an XML file.
Steps to Using Java XML Parser
When parsing the XML documents, we need to follow the following steps listed below –
- Import all packages related to XML at the beginning.
- Create a new instance of DocumentBuilder.
- From the available stream or file, you should create a document
- Extract the root element.
- Examine attributes and sub-elements.
How does Java XML Parser Work?
When it comes to parsing XML documents, Java has a lot of possibilities.
The following are some of the most widely used Java XML parsers:
- DOM
- SAX
- JAXB
- Streaming API for XML (Stax)
JAXB and Stax are new versions of Java. Stax parser uses a cursor and even iterator API for parsing XML documents. It takes two interfaces, Event Reader and Event Writer, and the application loops over the whole document for the next waiting Event.API type of Stax is pulled and streaming with no Xpath compatibility. Pull parsing allows the client to control the application thread and call parser methods as needed. Push processing allows the parser to control the application thread and the client to take only invocations from the parser. The abstract base class is XMLParser. An instantiated parser’s parse() method is used to read an XML document.
Java XML Parser Working:
- The XML Parser for Java receives an XML document as input.
- The DOM or SAX parser interface parses the XML document.
- The application receives the parsed XML and does the work further.
DOM Parser
The Document Object Model (DOM) creates a tree structure or representation inside the memory for the corresponding XML document passed to it. It provides methods and classes for processing the tree and navigating it within the application. Developers can use the interface of DOM, the most useful component of the XML tree, to manipulate structures actively. These manipulations involve deleting or adding old or new attributes and elements, reordering, and renaming the existing elements.
Developers prefer using the DOM API when they require random access to elements within their applications. You can use the DOM in XSL transformation tasks or when calling XPath. In short, we can say that whenever there is a requirement to use the iterations in a tree and need to scan or visit through the whole document, we can use the DOM API. It is also possible to customize the tree-building process in DOM. To reduce the size of the pipes in XML documents, we can use attributes more instead of elements in the DOM API.
SAX Parser
SAX stands for Simple API for XML, and the Push Parser is a stream-oriented XML Parser. The primary goal is to read the XML file and create an event to perform a call function or to use call-back routines. This parser works in the same way that the Java Event handler does. It’s required to register handlers to parse the page and handle various events. To offer the following call-backs, the SAX parser extends the Default Handler class:
- startElement: When a start tag is found, this event is triggered.
- endElement: When an end tag is met, this event is triggered.
- characters: When some text data is found, this event is triggered.
Examples of Java XML Parser
Below are the examples as follows:
Example #1 – Java DOM Parser
Read.java:
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
public class Read {
private static final String FILENAME = "D:\\parser\\amaz.xml";
public static void main(String[] args) {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder db = dbf.newDocumentBuilder();
Document doc = db.parse(new File(FILENAME));
doc.getDocumentElement().normalize();
System.out.println("Root Element :" + doc.getDocumentElement().getNodeName());
System.out.println("------");
// get <staff>
NodeList list = doc.getElementsByTagName("amz");
for (int temp = 0; temp < list.getLength(); temp++) {
Node node = list.item(temp);
if (node.getNodeType() == Node.ELEMENT_NODE) {
Element element = (Element) node;
String id = element.getAttribute("id");
String office = element.getElementsByTagName("office").item(0).getTextContent();
String location = element.getElementsByTagName("location").item(0).getTextContent();
String Country = element.getElementsByTagName("Country").item(0).getTextContent();
NodeList companyNodeList = element.getElementsByTagName("company");
String company = companyNodeList.item(0).getTextContent();
String growth = companyNodeList.item(0).getAttributes().getNamedItem("growth").getTextContent();
System.out.println("Current Element :" + node.getNodeName());
System.out.println("Staff Id : " + id);
System.out.println("office : " + office);
System.out.println("location : " + location);
System.out.println("Country : " +Country);
System.out.printf("company [growth] : %,.2f [%s]%n%n", Float.parseFloat(company), growth);
}
}
} catch (ParserConfigurationException | SAXException | IOException e) {
e.printStackTrace();
}
}
}amaz.xml:
This XML file contains xml attributes along with xml elements.
<?xml version="1.0"?>
<company>
<staff id="1001">
<firstname>yong</firstname>
<lastname>mook kim</lastname>
<nickname>mkyong</nickname>
<salary currency="USD">100000</salary>
</staff>
<staff id="2001">
<firstname>low</firstname>
<lastname>yin fong</lastname>
<nickname>fong fong</nickname>
<salary currency="INR">200000</salary>
</staff>
</company>Explanation: First, import the dom parser packages into the application in the above code.
- Next, the DocumentBuilder object will be created.XML file is taken to the document object. Finally, parse the XML file and save it in the document class.
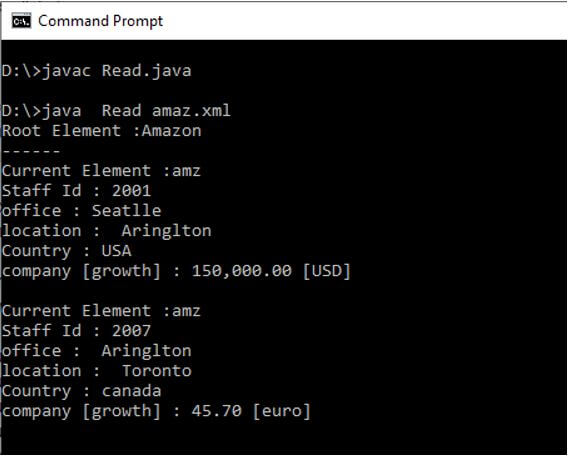
Output:
Example #2 – Java SAX Parser
Read.java:
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class Read
{
public static void main(String args[])
{
try
{
SAXParserFactory f = SAXParserFactory.newInstance();
SAXParser saxP= f.newSAXParser();
DefaultHandler hdl = new DefaultHandler()
{
boolean fid = false;
boolean fname = false;
boolean fproduct = false;
boolean discount = false;
boolean dataware = false;
public void startElement( String sg, String pp,String q, Attributes a) throws SAXException
{
System.out.println("First Node :" + q);
if(q.equalsIgnoreCase("FID"))
{
fid=true;
}
if (q.equalsIgnoreCase("FNAME"))
{
fname = true;
}
if (q.equalsIgnoreCase("FPRODUCT"))
{
fproduct = true;
}
if (q.equalsIgnoreCase("DISCOUNT"))
{
discount = true;
}
if (q.equalsIgnoreCase("DATAWARE"))
{
dataware = true;
}
}
public void endElement(String u, String l, String qNa) throws SAXException
{
System.out.println("Final Node:" + qNa);
}
public void characters(char chr[], int st, int len) throws SAXException
{
if (fid)
{
System.out.println("FID : " + new String(chr, st, len));
fid = false;
}
if (fname)
{
System.out.println("Shop details: " + new String(chr, st, len));
sname = false;
}
if (fproduct)
{
System.out.println("Remaining Product: " + new String(chr, st, len));
fproduct = false;
}
if (discount)
{
System.out.println("discount given: " + new String(chr, st, len));
discount = false;
}
if (dataware)
{
System.out.println("location : " + new String(chr, st, len));
dataware= false;
}
}
};
saxParser.parse("D:\\parser\\amaz.xml", handler);
}
catch (Exception ex)
{
ex.printStackTrace();
}
}
}amaz.xml:
<?xml version="1.0"?>
<onlineshop>
<flipkart>
<fid>301</fid>
<fname> ethinic</fname>
<fproduct> kurtas</fproduct>
<discount> 10</discount>
<dataware> bangalore</dataware>
</flipkart>
<flipkart>
<fid>401</fid>
<fname> partywear</fname>
<fproduct> saree</fproduct>
<discount> 20</discount>
<dataware> mumbai</dataware>
</flipkart>
<flipkart>
<fid>501</fid>
<fname> kids</fname>
<fproduct> t-shirts</fproduct>
<discount> 12</discount>
<dataware> Uttarpradesh</dataware>
</flipkart>
</onlineshop>Explanation:
- The above code implements an SAX parser that takes a new instance from the Flipkart shopping file. It parses node by node.
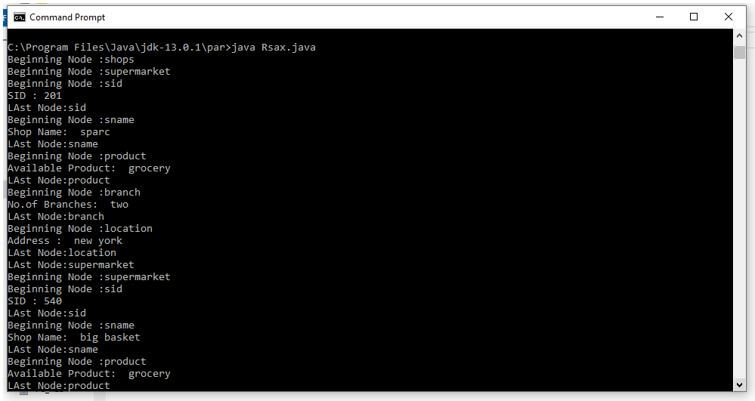
Output:
Example #3
The file that needs to be parsed will be the XML file shown below –
xml file:
<?xml version = "1.0"?>
<class>
<article articleNo = "393">
<topic>Android Auto</topic>
<nameOfAuthor>Payal</nameOfAuthor>
<genre>Android Auto</genre>
<numberOfPages>85</numberOfPages>
</article>
<article articleNo = "493">
<topic>PostgreSQL</topic>
<nameOfAuthor>Mayur</nameOfAuthor>
<genre>Database</genre>
<numberOfPages>95</numberOfPages>
</article>
<article articleNo = "593">
<topic>MySQL</topic>
<nameOfAuthor>Meera</nameOfAuthor>
<genre>DBMS</genre>
<numberOfPages>90</numberOfPages>
</article>
</class>Now, we need to write a class in Java that can write the business logic as well as try to parse the XML file using a DOM parser whose name is EducbaDomParserExample. and the contents of the file are as shown below –
EducbaDomParserExample.java
package com.educba.xml;
import java.io.File;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.DocumentBuilder;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
import org.w3c.dom.Node;
import org.w3c.dom.Element;
public class EducbaDomParserExample {
public static void main(String[] args) {
try {
File xmlFileToParse = new File("educbaXML.txt");
DocumentBuilderFactory instanceOfDocBuilderFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder educbaDocBuilderObj = instanceOfDocBuilderFactory.newDocumentBuilder();
Document sampleDocument = educbaDocBuilderObj.parse(xmlFileToParse);
sampleDocument.getDocumentElement().normalize();
System.out.println("Element present at the root of the tree :" + sampleDocument.getDocumentElement().getNodeName());
NodeList nodeListInstance = sampleDocument.getElementsByTagName("article");
System.out.println("__________________________");
for (int temporaryVar = 0; temporaryVar < nodeListInstance.getLength(); temporaryVar++) {
Node singleNode = nodeListInstance.item(temporaryVar);
System.out.println("\nElement Being Traversed :" + singleNode.getNodeName());
if (singleNode.getNodeType() == Node.ELEMENT_NODE) {
Element particulerElement = (Element) singleNode;
System.out.println("Article Number : "
+ particulerElement.getAttribute("articleNo"));
System.out.println("Topic: "
+ particulerElement
.getElementsByTagName("topic")
.item(0)
.getTextContent());
System.out.println("Author Name : "
+ particulerElement
.getElementsByTagName("nameOfAuthor")
.item(0)
.getTextContent());
System.out.println("Genre: "
+ particulerElement
.getElementsByTagName("genre")
.item(0)
.getTextContent());
System.out.println("Number Of Pages : "
+ particulerElement
.getElementsByTagName("numberOfPages")
.item(0)
.getTextContent());
}
}
} catch (Exception sampleException) {
sampleException.printStackTrace();
}
}
}The output of the execution of the above java file will produce the result shown in the below image –

Conclusion
A Java application will parse the XML or document, which is an extensible markup language file, using various types of parsers such as DOM parser, SAX parser, etc. In this article, we show how to convert that XML file into a tree-like structure, showing all the hierarchies inside the memory and how we can access or modify each element or attribute in the Java program.
Recommended Articles
This is a guide to Java XML Parser. Here,e we discuss the introduction: how does Java XML parser work? SAX parser and examples, respectively. You may also have a look at the following articles to learn more –

