Updated March 4, 2023

Introduction to Kafka Cluster
The Kafka cluster is a combination of multiple Kafka nodes. On top of Kafka nodes, we need to deploy the multiple Kafka services like Kafka Broker, Kafka consumer, Kafka Producer, Zookeeper, etc. In the Kafka cluster, we are getting multiple functionalities like a failure, replication, data high availability, multiple partition support, etc. In simple terminology, we can say that the Kafka Custer is the combination of multiple brokers and distribute the data on multiple instances. In the Kafka cluster, the zookeeper is having a very critical dependency. Here, the zookeeper is playing a role as a synchronization service and handle the distributed configuration. Zookeeper Server also plays an important role in terms of coordinator interface in between the stack of Kafka brokers and consumers.
Syntax:
As such, there is no specific syntax available for the Kafka Cluster. Generally, we are using any big data tool to deploy the Kafka cluster. We can also create the Kafka cluster in standalone mode also.
Note: It is recommended that we need to deploy the Kafka cluster with the help of big data tools like Ambari or Cloudera. If we will deploy the cluster with the help of this tool it will be easy to administration of the complete Kafka cluster administration.
How Kafka Cluster Works?
It is majorly recommended for the production environment. When we are working on the Kafka cluster level, we need to take care of lots of things like networking, clustering, hardware level, throughput, etc. As per the data or messages, we need to tune the Kafka cluster i.e. in terms of memory level (cluster level), node-level (hardware level), etc.
In the Kafka cluster, we are having multiple components. Kindly go through with the below one.
- Kafka Broker: In the Kafka cluster, we have seen the combination of number brokers. It will help to maintain the load balance. The Kafka brokers are stateless in nature. Hence, the Kafka broker uses the zookeeper for maintaining their state in the cluster. In Kafka, the write operation will handle by the selected Kafka broker leader and the remaining broker will serve the read operation. In some case, the Kafka leader may down or not accessible then the zookeeper helps to select the Kafka broker role in the cluster environment. The single Kafka broker will handle the hundreds or thousands of reads and writes per second. Even though the single Kafka broker will handle TB of messages without impacting the slowness.
- Zookeeper: Zookeeper is playing a very important role to manage and coordinate with the stack of Kafka broker. The Zookeeper service is mainly used to inform the Kafka producer and Kafka consumer about the presence of the number of broker in the environment or cluster. It will also notify if any new broker in the Kafka system may add or not. If any failure may happen or any broker may not reachable then it will inform to the Kafka ecosystem. When the zookeeper will notify regarding the Kafka broker failure or not reachable then the Kafka producer and consumer will make the decision. It will coordinate with the different broker for producing or consuming the data in the Kafka environment.
- Producers: In Kafka, the producer is playing a role to push data to the Kafka broker. When any new broker will be attached or sync with the Kafka eco-system then all the Kafka producers search it with the help of zookeeper. Then it will automatically start to push the message or data (records) to that new broker. In the Kafka producer, the producer will not wait for the record acknowledgment from the Kafka broker. It will directly send the messages and at the end, the Kafka broker will handle the message from there end. In the Kafka cluster level, the message handle frequency is very high.
- Consumers: We have seen that the Kafka brokers are stateless in nature that’s why the Kafka broker uses the zookeeper for maintaining their state in the cluster. It means that we need a mechanism to know how much data we have consumed and how much yet to consume. If we don’t have such a mechanism then it will be more difficult to process the data because the number of time it will process the older data. To avoid this condition, we need a Kafka offset concept. With the help of offset value, the consumer has maintained how many messages have been consumed from the Kafka topic. When the consumer has acknowledged for the particular message offset value then it means that the Kafka consumer has consumed all previous messages from the Kafka partition. In the Kafka cluster, the consumer offset value will update by the Zookeeper.
Example
Kafka Cluster Overview
As we have discussed with the multiple components of the Kafka Cluster. The same components come with the Kafka cluster. But in Ambari UI, we have only seen the Kafka Broker only but in the backend, we can use all the Kafka components.
Syntax:
For the Kafka cluster, there is no specific syntax, we just need to follow the procedure to enable the Kafka cluster.
The syntax term will applicable while creating the Kafka topic, Kafka broker, Kafka consumer, etc.
Explanation:
As per the below Screenshot 1 (A), we can see the Kafka service overview. Here, we can see there are 3 Kafka broker preset in the Kafka cluster. All three Kafka broker is managed by the cluster zookeeper.
As per the below Screenshot 1 (B), we will get the Kafka cluster matrix view
As per the below Screenshot 1 (C), we will get the Kafka cluster configuration properties.
Output :
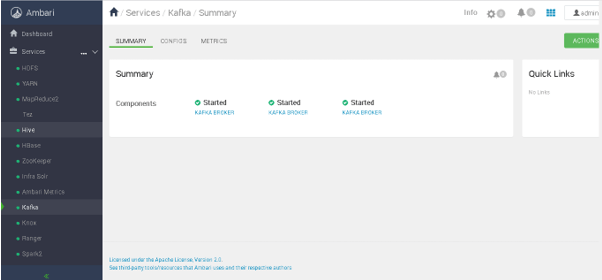
Screenshot 1 (A)
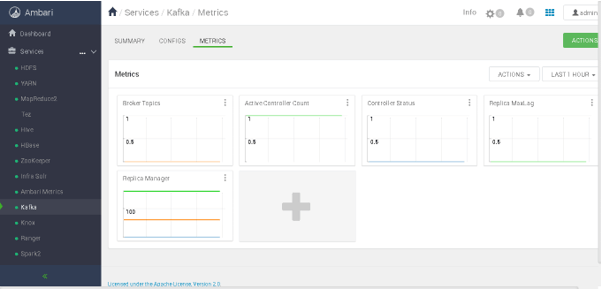
Screenshot 1 (B)
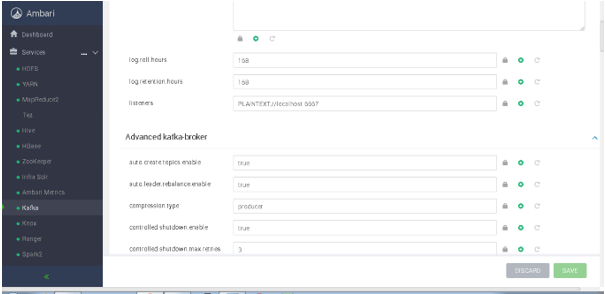
Screenshot 1 (C)
Conclusion
We have seen the uncut concept of “Kafka Cluster” with the proper example, explanation, and cluster method. The Kafka Cluster is very important in terms of the production environment. If we will enable the cluster with the help of Ambari or CDH platform then the cluster administration is easy.
Recommended Articles
This is a guide to Kafka Cluster. Here we discuss the Introduction, syntax, How Kafka Cluster Works and examples. You may also have a look at the following articles to learn more –
