Updated March 6, 2023
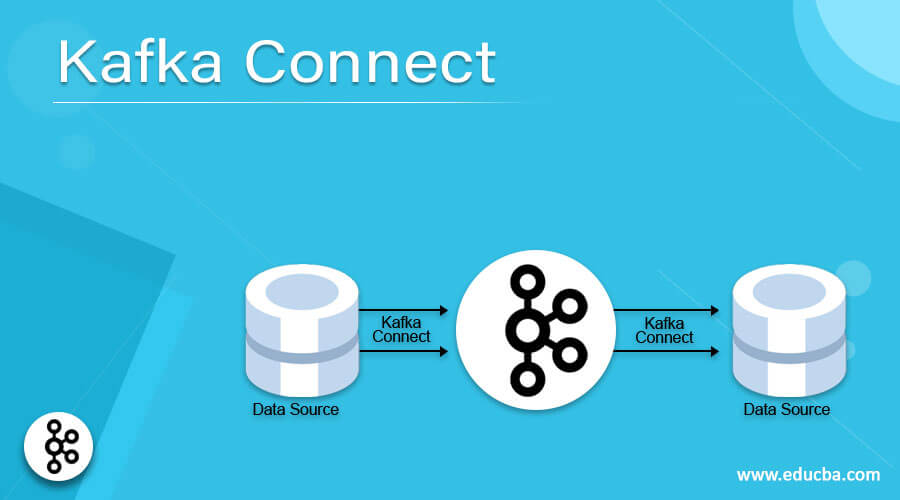
Introduction to Kafka Connect
Kafka Connect acts as a mediator between the apache Kafka and different or other data-driven systems. The Kafka connector is nothing but a tool for reliable as well as scalable streaming solutions. It will help to move a large amount of data or large data sets from Kafka’s environment to the external world or vice versa. The Kafka connector is helping with the data transfer, and it will help for the ingestion. It will ingest all the data into the Kafka topics. The Kafka connector provides low latency data access functionality. As per the requirement, we can use the Kafka export connector. It will help for the data deliver from the Kafka topics into the secondary catalogs like the ELK stack, elastic search, solr, etc.
Syntax of the Kafka Connect
As such, there is no specific syntax available for the Kafka connect. Generally, we are using the installation command for the Kafka connect.
Note:
1. While working with the Kafka connect. We are using the core Kafka commands and use the connect or connect parameters in it.
2) At the time of Kafka connect installation, we are using the CLI method. But generally, we are using the UI tool only.
How Kafka Connect Works?
The Kafka connect is act as a moderator in between the Kafka system to external analytics world. But the scope of the Kafka connector is low. It is majorly focusing on the streaming data copy in and out from Kafka. It will not be handling or responsible for any other task in the Kafka environment. The major focus is on the developer front to write or create high-quality code, reliable and high recital Kafka connector plugins, etc. By the stream treatment framework, it is avoiding duplicate functionality. But the Kafka connect is not an ETL pipeline. When the stream processing framework and Kafka combine, only we can say that Kafka connects part of the ETL Component.
Below are the lists of key-value option that are compatible with the Kafka connect.
| Sr No | Key-Value | Type | Importance |
| 1 | bootstrap.servers | List | It will be the combination of host and port pairs. It will help to use for establishing the connection with the Kafka cluster. The bootstrap server is helping to communicate with both the consumer and the producer. It will also help to connect the external environment and Kafka topic. As Cloudera suggested, we need at least 3 Kafka brokers in the cluster environment. |
| 2 | key.converter | Class | It will help to convert the class for the key data connect. It will help to convert the data. It will write the Kafka for the source connectors. The public format of the key converter is JSON and Avro. |
| 3 | value.converter | Class | It will help to convert the value data to connect. It will help to convert the data. It will write the Kafka for the source connectors. The public format of the key converter is JSON and Avro. |
| 4 | internal.key.converter | Class | It will help to convert the internal key data to connect and perform the converter interface. It will help to convert the data, i.e. offsets and configs. |
| 5 | internal.value.converter | Class | It will help to convert the offset value data and perform the converter interface. It will help to convert the data, i.e. offsets and configs. |
| 6 | offset.flush.timeout.ms | Long | The value of these properties is in milliseconds. It will be the max number of milliseconds to be waited for the records to be flush. But the partition data offset to be committed to storage offset before performing the cancel operation on the process. We can also restore the data offset in future operations or attempts. |
Examples to Implement or Check Kafka Connect
Here are the following examples mention below
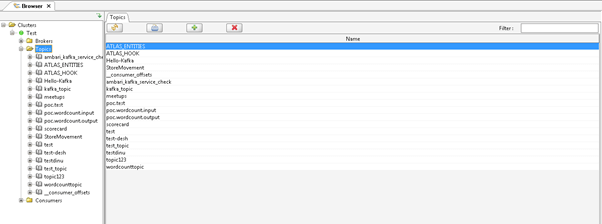
Example #1 – Check the List of Kafka Topics
In the Kafka environment, all the data or messages are stored on the Kafka topics. The data storage policy on the topics depends on the Kafka data retention period. With the help of Kafka connect, we can find the list of topics available in the environment.
Method :
We need to click on the Kafka topics and expand them via clicking on the “+” symbol.
Explanation :
As per the below screenshot, we are set the connection name as “Test”. We can list out all the Kafka Topics on the UI Screen. It will help to quickly identify the number of topics available in the Kafka environment.
Output :
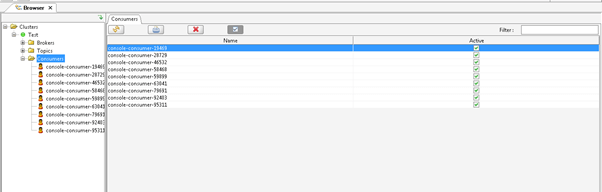
Example #2 – Check the List of Kafka Consumer
In the Kafka environment, all the data or messages are consumed by the Kafka consumers. As per the requirement, we can set single or multiple consumers to consume the Kafka data. With the help of Kafka connect, we can find the list of consumers that are available in the environment.
Method :
We need to click on the Kafka consumer and expand it via clicking on the “+” symbol.
Explanation :
As per the below screenshot, we are listing the number of consumers in the Kafka environment.
Output :
Example #3 – Capture the Kafka Messages
In Kafka, we can produce the messages and check on the UI level.
Command :
./kafka-console-producer.sh –broker-list 10.10.132.152:6667 –topic test_topic
Explanation :
As per Screenshot 1(A), we are producing the messages on the “test_topic”. In Screenshot 1 (B), we are capturing the same messages on the UI level and the byte format messages. In Screenshot 1 (C), we are changing the format from byte to string. Screenshot 1 (D), after changing the format. We can see producer messages.
Output :

Screenshot 1 (A)
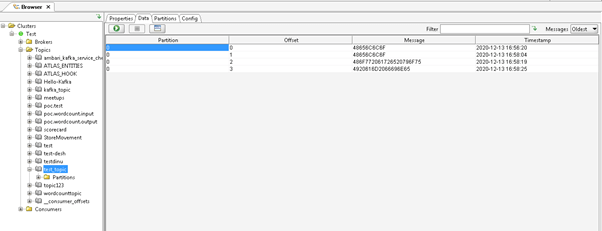
Screenshot 1 (B)
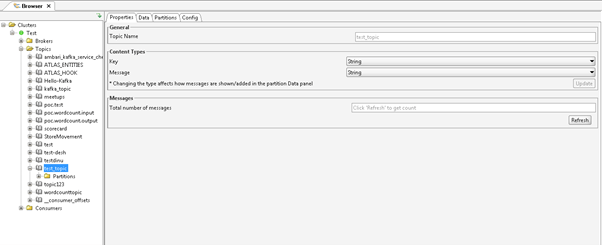
Screenshot 1 (C)
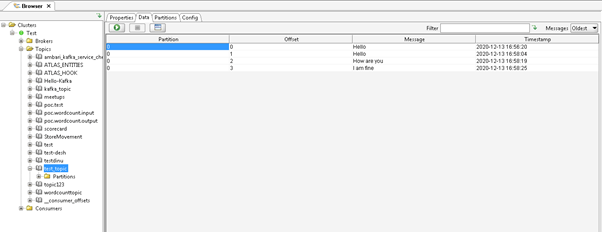
Screenshot 1 (D)
Conclusion
We have seen the uncut concept of “Kafka Connect” with the proper example, explanation, and methods with different outputs. As per the requirement, we can use Kafka Connect to connect the Kafka Environment with the external world. With the help of Kafka connect, we can do in and out of Kafka data.
Recommended Articles
This is a guide to Kafka Connect. Here we discuss the concept of Kafka Connect with the proper example, explanation, and methods with different outputs. You may also have a look at the following articles to learn more –
