Updated March 16, 2023
Introduction to Kafka Consumer
The Kafka consumer is defined as the confluent platform that can have consumers like java which are transferred from Apache Kafka, in which the consumer group is a set of consumers which helps to obsess the data which come from the identical groups and the division of all topics can be split into the group when new members can enter and old are left then the division can be modified so that every user get the equal shares which can be the rebalancing of the group. So the older can be considered high-level consumers, and new consumers can be the existing consumer depending on group management.
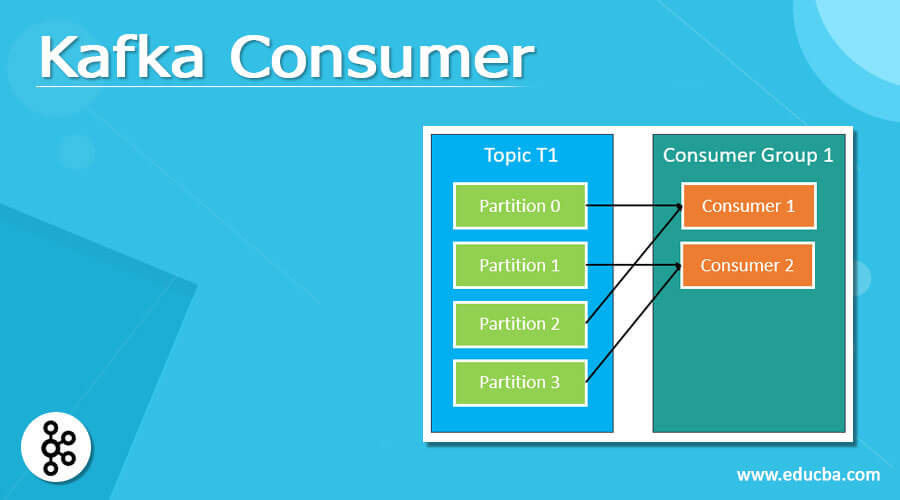
What is Kafka consumer?
The consumer is the one who can obsess or read the data from the Kafka group with the help of any topic. The consumer can understand from which dealer it can read the data in which consumer can read the data inside each division in an orderly manner, which can also mean that the consumer cannot be able to look at the data from offset 1 and prior to looking at the data in offset 0. A consumer can also be able to look at the data from multiple dealers at the same time.
For example, if we have two clients, Client 1 and Client 2, who are looking at or studying the data, in which Client 1 can allow studying the data provided by dealer 1, and simultaneously Client 2 can also read the data from dealer 2.
Kafka consumer configuration
The consumer configuration can contain the complete configuring setting; let us discuss some configuration settings and also how they can influence the bearing of the consumer,
a) Core configuration
In the core configuration, we need to set ‘bootstrap.servers’ as required. Still, we can able to set ‘client.id’ as long as it can authorize us to match up the appeal on the broker with the client occasion that can invent it. Generally, all clients under the identical group can split the identical consumer id to implement the client quotas.
b) Group configuration
In this configuration, we need to configure the ‘group id’ without the provision, we can use easy assignment API, and we do not have to reserve offsets in Kafka.
We can manage the session timeout by deciding the ‘session.timeout.ms’ value, which can have the default of 10 seconds for the C/C++ and java clients. Still, we can expand the time to avoid immoderate readjustment, e.g., because of deficient network connectivity.
The major disadvantage of utilizing the larger session timeout is that it can grasp longer for the coordinator to determine when any client can have the occasion which has been slammed; it means it can grip the longer for other consumers in any group to grasp its partitions, for example in shutdown the client can able to convey the direct request to the consumer in which it can be easy for coordinator can decide to vacate the group which can trigger the immediate rebalance.
The additional setting, which can act on the relocating feature of the ‘heartbeat.interval.ms’, can able to manage in such a way that the user can able to send a heartbeat to the coordinator; it is another path in which the client can able to determine when we required a rebalance, hence to have a less heartbeat interval can typically faster the rebalancing, which can have the default setting for three seconds.
Let us see another feature that can affect the unrestricted rebalancing that is ‘max.poll.interval.ms’, which can define the maximum time, which is the time between calls to the consumer poll method before failing the consumer procedure, which can have the default if 300 seconds and it can be protected to increase the requirement of the application to which can have the time to processing of the messages.
Kafka consumer groups command tool
Given below are the Kafka consumer group command tools:
1. List Groups
We can utilize the ‘Kafka-consumer-groups’ profitability in the Kafka dispersal to gain the index of working groups.
If we have a huge group, we can withdraw a list that can have an assembly and examine every broker in the group with the help of the below command.
bin/Kafka-consumer-groups –bootstrap-server host:9092 –list
2. Describe Group
In this tool, a utility ‘Kafka-consumer-groups’ can also be utilized to gather data on the surviving group; the following command has been used to understand the ongoing assignment for the ‘foo’ group.
bin/kafka-consumer-groups –bootstrap-server host:9092 –describe –group foo
If we wanted to turn on this when rebalancing can be in progression, then the above command can show an error, and when we try it again, we can see the assignment for all members in the present organization.
3. Manual offset control
The manual offset control can be set by setting as “auto.commit.offset=false,” in which we can execute the offset when the application can be directed by selecting it to perform, and to commit the offset non-simultaneously, we can able to utilize the below method for Kafka consumer,
‘public void commitAsync()’
When a consumer can accept the assignment from its helper, then it can define the starting position for every assigned division; when we try to generate the group before consuming the messages so the position can be set as per the configuration policy, which can be reset in ‘auto.offset.reset’, the policy of the offset can be critical to furnish the messages by using the application, the consumer can configure for utilization of the commit policy and that consumer can also manage the API for commit which can be utilized for manual offset management.
Conclusion
In this article, we conclude that the Kafka consumer can have the consumers from java and use Apache Kafka on the confluent platform. We have also discussed its tools and manual offset control, so this article will help to understand the concept of the Kafka consumer.
Recommended Article
This is a guide to Kafka Consumer. Here we discuss the introduction, What is Kafka consumer, configuration, and command tools, respectively. You may also have a look at the following articles to learn more –
