
Introduction to Kafka Replication
Replication is at the centre of architecture in Kafka. Kafka’s official documentation’s very first line sums it up as “a distributed, partitioned, replicated commit log service.” Replication is important because it is the way Kafka ensures availability and reliability when individual nodes eventually fail. Replication is the practice of having multiple copies of the data for the main aim of availability if one of the brokers fails to satisfy the requests. In Kafka, replication occurs at partition granularity, i.e. copies of the partition are stored in several broker instances using the partition’s write-ahead log.
What is Replication?
As we know, data in Kafka is grouped by topics. Every topic is partitioned, and every partition can have several replicas. These replicas are stored on brokers, and typically each broker stores more than hundreds of replicas from various topics and partitions. In Kafka, replication occurs at partition granularity, i.e. copies of the partition are stored in several broker instances using the partition’s write-ahead log. Every partition has a write-ahead log where all the messages are stored for that partition in the Kafka topic. Each message has an offset which acts as a unique identifier.
The replication factor determines the number of copies that must be held of the partition. There are two different types of replicas:
Leader Replica: Each partition is designated as the leader with a single replica. All demands for producing and consuming go through the leader to ensure consistency.
Followers Replica: All replicas are called followers for a partition that is not leaders. Followers do not answer client requests; their only task is to replicate the leader’s messages and keep up to date with the leader’s most recent messages. If a leader replica crashes for a partition, then one of the follower replicas will be promoted to become the new partition leader.
How does replication work in Kafka?
As we have read above, what is replication in Kafka now? Let us learn more about how does this replication take place in Kafka.
In a Kafka topic, every partition contains a write-ahead log that stores the messages. Each message can be identified with its unique identifier called offset, which specifies its location in the partition log.
Partition’s write-ahead log
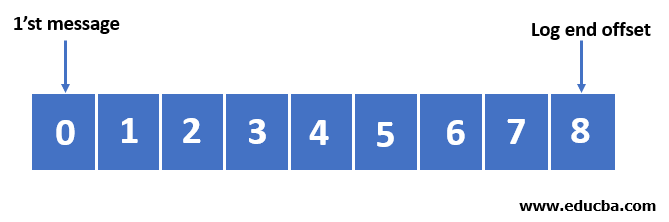
Each partition in the Kafka topic is replicated n times, where n stands for the topic’s replication factor. The replication factor determines the number of copies that must be held for the partition. If a cluster server fails, Kafka will finally be able to get back to work because of replication. From all of the total n replicas, there will be one dedicated replica that will be assigned as a leader. As the name suggests, the leader takes the writings from the producer, and the followers simply copy the log of the leader in order.
Kafka Cluster with replication factor 2
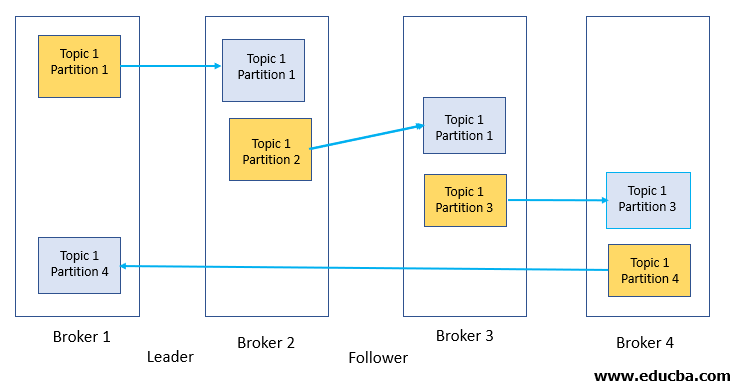
From the figure above, it is clear that the replication factor of 2 is specified, which means that there will be two copies for each partition.
So let’s see what happens when a broker going down. Let’s say Broker 3 goes down for some reason. Connection to partition 3 is now lost as the leader for partition 3 was broker 3. What’s going to happen now is that Kafka automatically picks one of the in-sync replicas (in this case, there is only 1 replica) and makes them the leader. Now when broker 3 comes online, it can seek to become the leader again. The leader manages
the in-sync replica (ISR) list for each partition by measuring each replica’s latency on its own. When a producer sends a message to the broker, the leader copies it and replicates it to all partition replicas. A message will only be committed after it has been effectively copied to all replicas in sync. Use the setting “acks,” producers may opt to receive acknowledgements for the data writes to the partition.
Let’s see what’s meaning for acks is in Apache Kafka and how to set them.
An acknowledgement (ACK) is a sign transmitted between communication networks to indicate acknowledgement which means reception of the message transmitted successfully. There are three types of acknowledgement that users can select from based on their Kafka use case.
- Acks=0:- Once the ack value is set to 0, the producer will not wait for an acknowledgement from the broker. So we don’t have any assurance that the broker has received the message successfully or The producer is not trying to send the message again as it won’t realize the record has been lost, so there are chances of data loss.
- Acks=1:- When the ack value is set to 1, the producer gets an acknowledgement after the record has been received by the It will reply without waiting for all followers for a complete acknowledgement. The message will only be lost if the leader fails directly after noticing the record even before the followers have replicated it. There is partial data loss.
- Acks=all:- When we set the ack value to all, it ensures that when all in-sync replicas get the data, the producer gets a The leader must wait to accept the record with the full set of in-sync replicas. This implies that sending a message with acks=all; takes a long time, but it does provide the best durability of the message, which means no data loss.
Importance of using replication in Kafka
Kafka clients will get the following benefits with replication.
- A producer can continue to publish messages during failure and may choose between latency and durability based on the use.
- A consumer always gets the right messages in real-time, even in the event of a
Conclusion
So far, we’ve seen what Kafka replication is, how it works, and why it’s important. Kafka ensures that if a message is acknowledged as committed, messages will not get lost even in the event of a leader breakdown.
Recommended Articles
This is a guide to Kafka Replication. Here we discuss introducing Kafka Replication, what is replication, how it works, and its importance. You can also go through our other related articles to learn more –
