Updated March 4, 2023

Introduction to Kafka Topic
The Kafka, we are having multiple things that are useful for real-time data processing. It is useful to store the records or data and publish. The topic will further be distributed on the partition level. The same functionality will helpful for the better reliability of the data. It will also helpful for the data or record replication (subject to cluster configuration). As per the requirement, we can store the record or data on the topic partition. While storing the data, the offset key plays an important role. With the help of this, we are able to store the data or record on the different partition with different offset keys.
Syntax:
./kafka-topics.sh --create --zookeeper 10.10.132.70:2181 --replication-factor 1 --partitions 1 --topic kafka_topic
- Shell Script: To create the Kafka topic, we need to use the Kafka-topics.sh file or script. We can use the default Kafka topic variable also.
- Zookeeper: In the topic command, we need to pass the zookeeper server details.
- Replication: We need to define the replication value. As per the recommended value, we need to define it as 3.
- Partition: We can also define the partition while creating the topic.
- Topic Name: At the end, we need to define the topic name.
Note: In the HDP environment, we need to use the default path for the topic creation. Path: /usr/hdp/current/kafka-broker/bin
How Kafka Topic Works?
It is useful to store the records or messages on a specific topic. For the proper data manipulation, we can use the different Kafka partition. Here, we can use the different key combinations to store the data on the specific Kafka partition.
Below are the lists of configuration options:
1. create. topics. enable: It will help to create an auto-creation on the cluster or server environment.
Type: Boolean
Default: true
Valid Values: N/A
Importance: high
Update Mode: read-only
2. topic. enable: It will help to enable the delete topic. We can use the Kafka tool to delete. There is no impact if we will have no effect if we will disable the config with offsetting.
Type: Boolean
Default: true
Valid Values: N/A
Importance: high
Update Mode: read-only
3. topic. compression.codec: With the help of this topic, we can compress codec for the offset topic. To get the automatic commit option, we need to use this configuration property.
Type: int
Default: 0
Valid Values: N/A
Importance: high
Update Mode: read-only
4. topic. num.partitions: It will help for the number of topic partitions (point to the offset commit topic). Once the configuration was done at the time of deployment. After that, it will not change.
Type: int
Default: 50
Valid Values: [ 1, … ]
Importance: high
Update Mode: read-only
5. topic. replication.factor: It will help to set the replication factor of the Kafka offset topic. If we will choose the higher replication value then we will get the higher availability of the data. While creating the internal Kafka topic if we haven’t set the proper replication factor then it may get an error while creating a Kafka topic.
Type: short
Default: 3
Valid Values: [1,…]
Importance: high
Update Mode: read-only
6. topic. segment.bytes: We need to set the offsets topic segment value in the format of the byte. It should be kept relatively small. The same value will help for the faster cache loads and the log compaction.
Type: int
Default: 104857600 (100 mebibytes)
Valid Values:[1,…]
Importance: high
Update Mode: read-only
7. replication.factor: It will help to set the default replication factors. It will implement for the automatic Kafka topic creation.
Type: int
Default: 1
Valid Values:
Importance: medium
Update Mode: read-only
8. partitions: It will help to for the default number of log partitions per Kafka topic.
Type: int
Default: 1
Valid Values: [1,…]
Importance: medium
Update Mode: read-only
9. topic.policy.class.name: With the help of this property, we can create the topic policy class. Basically, it will use for validation purposes. The same configuration will help for the class (for the implementation of the org.apache.Kafka.server.policy.CreateTopicPolicy interface).
Type: class
Default: null
Valid Values: N/A
Importance: low
Update Mode: read-only
Example for the Kafka Topic
Overview
As we have discussed with the multiple components in the Kafka environment. We will create the Kafka topic in multiple ways like script file, variable path, etc. As per the production Kafka environment, it will be recommended that we need to go with Kafka topic replication value 3.
Syntax :
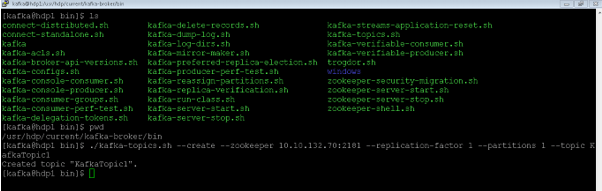
./kafka-topics.sh --create --zookeeper 10.10.132.70:2181 --replication-factor 1 --partitions 1 --topic KafkaTopic1
Explanation:
As per the above command, we are creating the Kafka topic. Here we are using the zookeeper host and port (Hostname: 10.10.132.70, Port No: 2181). Need to define the replication factor i.e. 1 and define the number of partition in the topic. At the last, we need to provide the topic name i.e. KafkaTopic1.
As per the below Screenshot 1 (A), we can create a new Kafka topic.
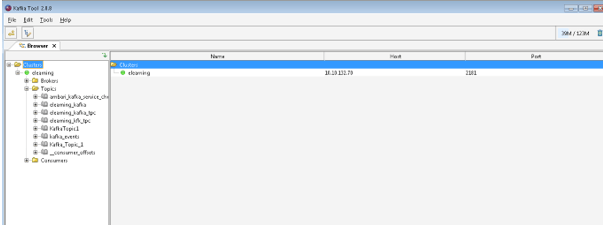
As per the below Screenshot 1 (B), we have connected the environment with the Kafka tool. Here, we need to define the zookeeper configuration in th tool.
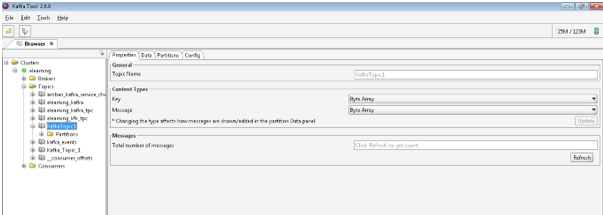
As per the below Screenshot 1 (C), we can get the newly created Kafka topic in the Kafka tool. We will get detail information of Kafka topic like partition information, etc.
Output :
Screenshot 1 (A)
Screenshot 1 (B)
Screenshot 1 (C)
Conclusion
We have seen the uncut concept of “Kafka Topic” with the proper example, explanation, and cluster method. It is very important in terms of Kafka environment. It will help to store the messages or records on the Kafka topic. We can create multiple partitions. We can use the different offset keys to store the records or messages into the different Kafka partitions.
Recommended Articles
This is a guide to Kafka Topic. Here we discuss the introduction, syntax, How Kafka Topic Works? and examples with code implementation. You may also have a look at the following articles to learn more –
