Updated March 14, 2023

Definition of Keras Datasets
Keras is a python-oriented library that comes as an extension to TensorFlow. Keras datasets library is used to deal with any deep learning or artificial intelligence-related model. Keras datasets help in providing proper data for preparing the models according to the requirement and specifically justifies the fit for any model. There are variants present as part of the keras.datasets module that is used for modeling and is considered for troubleshooting activities especially to find the insights which are also known “as a few toy datasets” that are present in vectorized and NumPy format.
What are keras datasets?
Keras datasets as an extension to TensorFlow include a module or library with tf.keras.datasets that are used for modeling and fitting data related to models with Artificial intelligence and deep learning. This library helps in providing actual and appropriate data as per the need of the model. All variants available as part of the keras datasets library are present in vectorized and NumPy format. It gives the advantage to debug or troubleshooting any simple code with ease. Formats or variants present are as follows MNIST (Used for classification of 10 digits), fashion MNIST (Used for classification of 10 fashion categories), CIFAR (Used for imaging with labels), etc.
Keras datasets classification
Keras datasets that are available for classifications are as follows. Each of the classifications made is as per requirement like whether it is with respect to the image or is with respect to the digits. Classification is as follows:
# MNIST classification datasets for digits
- MNIST datasets basically deal with the classification of digits that can be handwritten and can contain up to 10 digits.
# CIFAR 100 small classification datasets especially to be used (smaller images)
- CIFAR 100 small classification gels well with the smaller images classification that can take into consideration 50,000 images.
- It can take up to 32×32 color images in the training data set whereas it can consider up to 10000 data set as test images with classes of 100 fine granularities which can be grouped with 20 fine granular groups.
# IMDB sentiment classification review for any movie review
- The load function helps in loading the IMDB dataset which is used for reviewing movies up to 25000.
- It also considers labels with the respective sentiments or feedback as positive or negative.
- Reviews are provided in the form of an encoded list of words that are present in each of the indexes after preprocessing the data respectively.
- It contains a filtering process that can count words and consider up to 10,000 most common words and can eliminate up to 20 most common words.
- It also considers another function like get_word_per_index that is used for dict mapping of the word with its index.
# CIFAR 10 small classification datasets (smaller images)
- It helps in loading_function that is used for small images classification.
- The load_function can take a dataset of 50000 where 32×32 images can be taken as training data and test images up to 10000 with labels up to 10 categories.
# Boston housing regression type dataset for pricing models
- This helps in loading dataset which consists of Boston housing datasets used for getting and tracing the locations of Boston suburbs for houses located with houses in values of 13$.
# Reuters classification dataset for newswire.
- Reuters classification dataset for newswire is somewhat like IMDB sentiment dataset irrespective of the fact Reuters dataset interacts with the newswire.
- It can consider dataset up to 11,228 newswires from Reuters with labels up to 46 topics.
- It also works in parsing and processing format.
# Fashion MNIST dataset(alternative to MNIST)
- It Is a kind of alternative to MNIST where the fashion MNIST can consider a dataset of 60000.
- It takes gray scale image of 28×28 up to 10 fashion type categories with 10000 images.
- This dataset is considered as a replacement for MNIST.
Keras Datasets Arguments
Each of the classifications considers the following arguments with the loading of dataset:
# Arguments for MNIST classification datasets for digits
- Path: this argument basically points to map the relative path locally from cache to dataset that returns a tuple of NumPy arrays.
# Arguments for CIFAR 100 small classification datasets for smaller images
- label_mode: This argument is used as one of the “fine”, “coarse” in short as labels. If it is fine then that label is used for fine-grained labels and coarse as output label for coarse-grained superclass and returns tuple of NumPy arrays.
# Arguments for IMDB sentiment classification review for any movie review.
- Path: relative path from the cache to the dataset
- Num_words: number of words that need to be kept in frequency can be either integer or none.
- Skip_top: This argument is used for skipping the top N most frequently occurring words.
- Seed: used for data shuffling that can be reproducible for words from the index that needs to be manipulated.
# Arguments for CIFAR 10 small classification:
- Labels: According to different class levels.
# Arguments for Boston housing regression type dataset for pricing models
- Path: relative path from cache to dataset
- Test_split: portion or fraction of dataset for manipulation
- Seed: used for data suffling that can be reproducible for words from the index that needs to be manipulated.
# Arguments for Reuters classification dataset for newswire
- Path: relative path from cache to dataset
- Num_words: number of words that need to be kept in frequency can be either integer or none.
- Skip_top: This argument is used for skipping the top N most frequently occurring words.
- Seed: used for data suffling that can be reproducible for words from the index that needs to be manipulated.
# Arguments for Fashion MNIST dataset an alternative to MNIST.
- Labels: According to different class levels. (0-10)
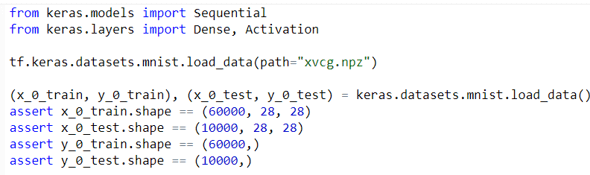
MNIST Datasets
- MNIST datasets are basically used for making a count or record over the number of digits used for MNIST classification.
- It can take up around 60000 digits in the training set and for test set it can take into consideration images up to 10000 images.
- Image size must be around 28×28 for any image manipulation approximately.
- Arguments taken are a path from cache to dataset.
- It is a subset of a larger set known as NIST.
- It is one of the best libraries for learning techniques and processing data with pattern recognition in real-world scenarios.
Example
Conclusion
Keras dataset plays a pivotal role when it comes to get the appropriate data for modeling the entire model based on requirements for deep learning. It provides a wide range of datasets whether images or digits for processing and playing around with the data.
Recommended Articles
This is a guide to Keras Datasets. Here we discuss the definition, What is keras datasets, classification, arguments, examples with code implementation. You may also look at the following articles to learn more-
