Updated March 16, 2023

Introduction to Keras GRU
Keras GRU abbreviation is gated recurrence unit which was introduced in 2014. It is very simpler and very similar to the LSTM. It is nothing but the LSTM without using an output gate. They are performing similarly to the LSTM for most of the tasks, but it will perform better on multiple tasks by using a smaller dataset and using data that was less frequently used in the keras network.
Key Takeaways
- The keras GRU is known as a gated recurrent unit or it is an RNN architecture that was similar to the units of LSTM.
- It will comprise the update gate and reset gate instead of using an input. The reset gate will combine new input from memory.
What is Keras GRU?
By using keras and tensorflow we are building the neural network which was very easy to build. We can easily build the neural network by using libraries of keras and tensorflow. Basically, GRU is an improved version of the RNN model. It is more efficient than the RNN model which was very simple. It is an improved version of the RNN model. This model is very useful and efficient compared to the RNN model.
The model contains two gates first is reset and the second is updated. We can also replace the simple RNN layer with the bidirectional gru layer. The GRU model will comprise the reset gate and update the gate instead of an input. It will forget the gate of the LTSM. The reset gate will determine how we are combining the new input by using previous memory and the output gate will define how much memory we are keeping around.
Keras GRU Layers
As per the available constraint and hardware, the GRU layer is choosing different implementations for maximizing the performance. If the gru is available and all the arguments of the layer are meeting the requirement of the cuDNN kernel. This layer will use the cuDNN implementation. The below example shows how keras gru uses the layer as follows.
Code:
tf.keras.layers.GRU(
units,
activation,
return_state = False,
go_backwards = False,
stateful = False,
unroll = False,
time_major = False,
reset_after = True,
recurrent_activation = "sigmoid",
use_bias = True,
kernel_initializer = "glorot_uniform",
recurrent_initializer = "orthogonal",
bias_initializer = "zeros",
bias_constraint = None,
dropout = 0.0,
recurrent_dropout = 0.0,
return_sequences = False,
)Output:
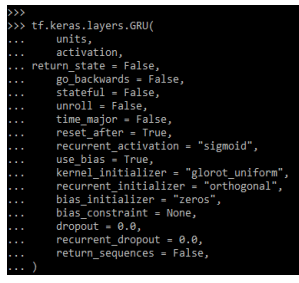
Basically, there are two variants available for GRU implementation. Default is based on the v3 and it contains the reset gate which was applied to the matrix multiplication. The other is based on the original and it contains the order reserved.
Code:
ip = tf.random.normal([22, 12, 6])
lay = tf.keras.layers.GRU (6)
op = lay(ip)
print(op.shape)Output:
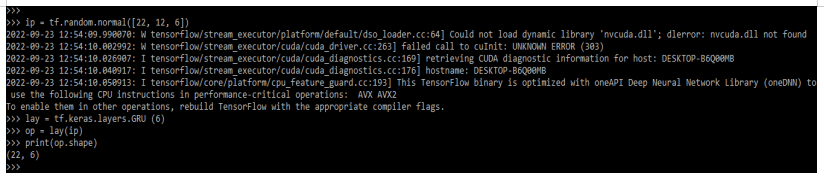
The below variant of gru layer is compatible with the GPU only. So it will contain separate biases.
Code:
lay = tf.keras.layers.GRU (4, return_sequences = True, return_state = True)
whole_sequence_output, final_state = lay (ip)
print(whole_sequence_output.shape)
print (final_state.shape)Output:
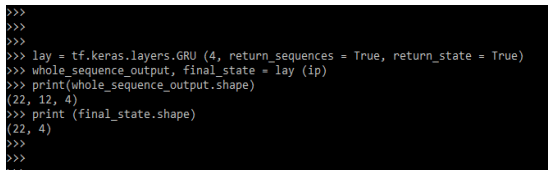
Keras GRU contains the below arguments which we need to define while implementing the gru layer.
- activation
- units
- recurrent_activation
- use_bias
- kernel_initializer
- recurrent_initializer
- bias_regularizer
- kernel_regularizer
- recurrent_regularizer
- go_backwards
- stateful
- bias_initializer
- activity_regularizer
- kernel_constraint
- recurrent_constraint
- bias_constraint
- dropout
- recurrent_dropout
- return_sequences
- return_state
- time_major
- reset_after
The keras gru layer also contains the call arguments i.e. mask, input training, and initial state. We can use all these arguments at the time of defining it.
Keras GRU Methods
Given below are the methods mentioned:
1. get_dropout_mask_for_cell
This method will get mask dropout from the cells RNN input. This method is creating mask based context into the cached mask. If suppose a new mask is generated it will update the cache in the cell. This method will contain count, input, and training arguments. The below example shows get_dropout_mask_for_cell method.
Code:
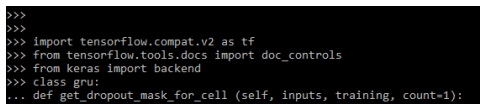
import tensorflow.compat.v2 as tf
from keras import backend
class gru:
def get_dropout_mask_for_cell (self, inputs, training, count=1):
if self.dropout == 0:
return NoneOutput:
2. get_recurrent_dropout_mask_for_cell
This method will get the recurrent mask dropout from the RNN cell. It will create mask based context which was existing in the cached mask. This method will contain count, input, and training arguments. Below example shows get_recurrent_dropout_mask_for_cell method.
Code:
import tensorflow.compat.v2 as tf
from keras import backend
class gru:
def get_recurrent_dropout_mask_for_cell (self, inputs, training, count=1):Output:
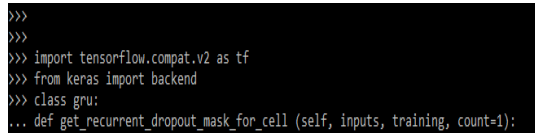
3. reset_dropout_mask
This method is used in resetting the dropout mask. This method is important in the RNN layer for invoking the call method so we can clear the cached method by calling the call method. The below example shows get reset_dropout_mask method.
Code:
import tensorflow.compat.v2 as tf
from keras import backend
class gru:
def reset_dropout_mask (self):Output:
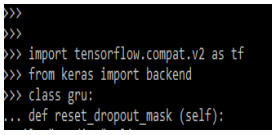
4. reset_recurrent_dropout_mask
This method is used in resetting the recurrent dropout mask. This method is important in the RNN layer for invoking the call method so we can clear the cached mask method. The below example shows get reset_recurrent_dropout_mask method.
Code:
import tensorflow.compat.v2 as tf
from keras import backend
class gru:
def reset_recurrent_dropout_mask (self):Output:
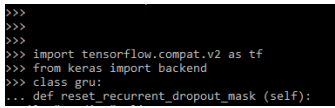
5. reset_states
This method is used to reset the recorded states from the RNN layer. We can use the RNN layer which was constructed from stateful arguments. Numpy array contains the initial state value. The below example shows reset_states method.
Code:
import tensorflow.compat.v2 as tf
from keras import backend
class gru:
def reset_states(states = None):Output:
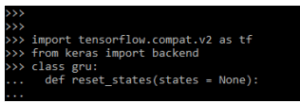
Keras GRU Network
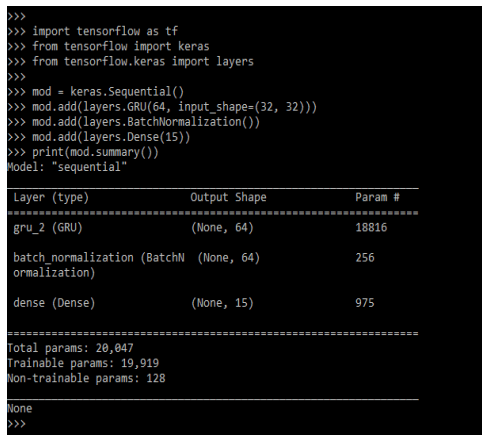
The GRU unit doesn’t need to use a memory unit for controlling the flow of information unit as LSTM. It will make use of hidden states without any control. GRU contains parameters for training the faster and generalizing the large data. The gru network is very similar to the LSTM except it will contain two gates update and reset gate. The reset gate will determine how we can combine the new input with the previous memory. The below example shows how keras gru works as follows. In the below example, we are creating the model.
Code:
mod = keras.Sequential()
mod.add(layers.GRU(64, input_shape=(32, 32)))
mod.add(layers.BatchNormalization())
mod.add(layers.Dense(15))
print(mod.summary())Output:
In the below example, we are using the fit method to define the keras gru network model.
Code:
model.fit (
x_train, y_train, …
)Output:

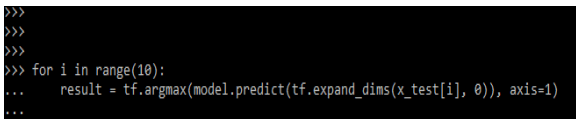
Now we are testing the keras gru network model. We are using for loop for the same.
Code:
for i in range(10):
result = tf.argmax()Output:
Examples of Keras GRU
Given below are the examples mentioned:
Example #1
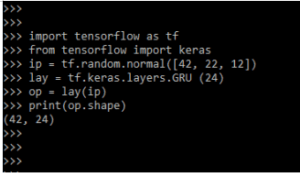
In the below example, we are using the layer.
Code:
import tensorflow as tf
from tensorflow import keras
ip = tf.random.normal([42, 22, 12])
lay = tf.keras.layers.GRU (24)
op = lay(ip)
print(op.shape)Output:
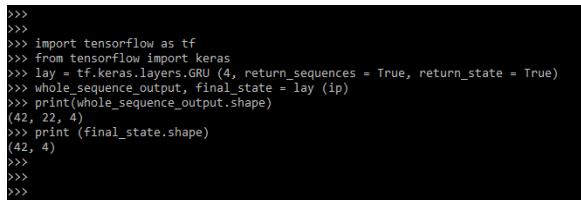
Example #2
In the below example we are importing the keras module.
Code:
import tensorflow as tf
from tensorflow import keras
lay = tf.keras.layers.GRU ()
whole_sequence_output, final_state = lay (ip)
print(whole_sequence_output.shape)
print (final_state.shape)Output:
FAQ
Given below are the FAQs mentioned:
Q1. What is the use of keras GRU?
Answer: Keras gru does not contain the memory unit for controlling the information flow like a unit of LSTM. It will make use of hidden states without using control.
Q2. Which libraries do we need to import at the time of using keras gru?
Answer: We need to import the tensorflow and keras library at the time of using keras gru. We also need to import the layers module.
Q3. How many methods are available in keras GRU?
Answer: Basically, there are five methods available at the time of working with keras gru.
Conclusion
We can easily build the neural network by using libraries of keras and tensorflow. Keras gru abbreviation is gated recurrence unit which was introduced in 2014. It is very simpler and very similar to the LSTM. It is nothing but the LSTM without using an output gate.
Recommended Articles
This is a guide to Keras GRU. Here we discuss the introduction, keras GRU layers, methods, network, examples, and FAQ. You may also have a look at the following articles to learn more –
