Updated March 16, 2023
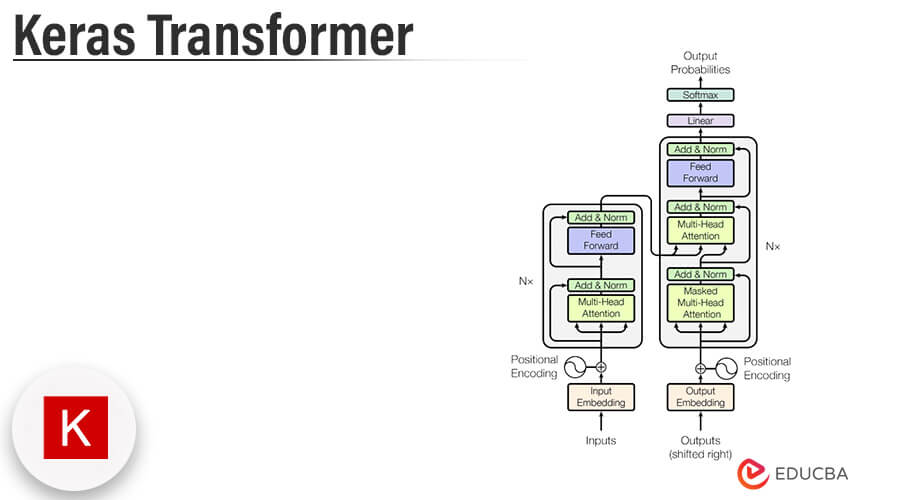
Introduction to Keras Transformer
Keras transformer is used to model sequential data in a natural language. It is more efficient and it was parallelizable by using several hardware like GPUs and TPUs. Transformers replaced recurrence and attention by using the main reason as computation. The output of the layer is calculated in parallel instead of in series like an RNN. They are able to capture long range distant contexts of distant position dependencies.
Key Takeaways
- Keras transformer token is first embedded into the space which was high dimensional and the input was embedded and added into the position encoding.
- The encoding which was summed is fed into the encoder. There are multiple layers of keras transformer available for encoding and decoding data.
What is Keras Transformer?
While using a transformer in keras longer connections are learned, and attention allows for each location that has access to the input layer. At the time RNN and CNN information needs to be passed through multiple processing steps for moving the long distance. Transformer is not making any assumptions regarding temporary and spatial relationships as per data, as we can say that it is ideal processing for a set of objects.
We are using a top-down approach while building the intuitions behind the architechture of the transformer. Basically, it consists of two modules first one encoding and the second is the decoder. Transformer source token was first embedded by using high dimensional space. The embedding of input is added by using positional encoding. The summed embeddings are fed into the encoder.
How to Use Keras Transformer?
To use the keras transformer we need to follow the below steps as follows, we need to import the required model.
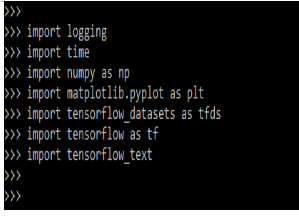
1. In the first step we are importing the required module by using the import keyword.
Code:
import logging
import time
import numpy as np
import matplotlib.pyplot as plt
…..
import tensorflow_textOutput:
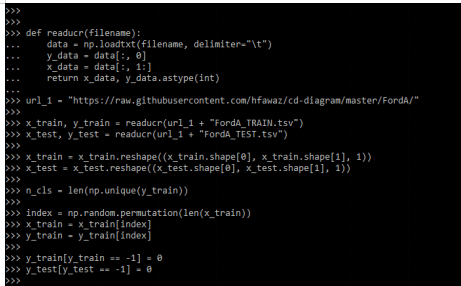
2. After importing the module now in this step we are loading the dataset by using url as follows.
Code:
def readucr(filename):
data = np.loadtxt (filename, delimiter="\t")
y_data = data[:, 0]
x_data = data[:, 1:]
return x_data, y_data.astype (int)
url_1 = ".."
x_train, y_train = readucr (url_1 + "FordA_TRAIN.tsv")
x_test, y_test = readucr(url_1 + "FordA_TEST.tsv")
x_train = x_train.reshape ()
x_test = x_test.reshape ()
n_cls = len(np.unique(y_train))
index = np.random.permutation (len(x_train))
x_train = x_train[index]
y_train = y_train[index]
y_train[y_train == -1] = 0
y_test[y_test == -1] = 0Output:
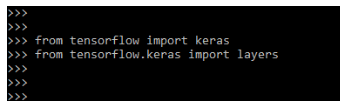
3. After loading the dataset in this step, we are importing the module which was required for building the model.
Code:
from tensorflow import keras
from tensorflow.keras import layersOutput:
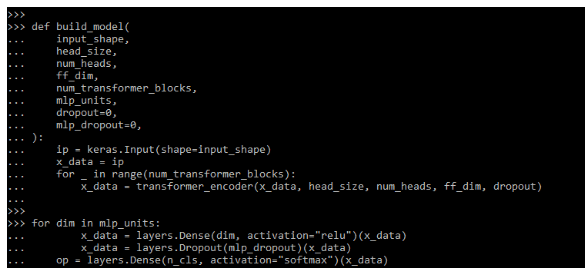
4. After loading the dataset, now we are building the model as follows.
Code:
def build_model (
input_shape,
……
mlp_dropout = 0,
):
ip = keras.Input (shape=input_shape)
x_data = ip
for _ in range (num_transformer_blocks):
x_data = transformer_encoder ()
for dim in mlp_units:
x_data = layers.Dense (dim, activation = "relu") (x_data)
x_data = layers.Dropout (mlp_dropout) (x_data)
op = layers.Dense ()Output:
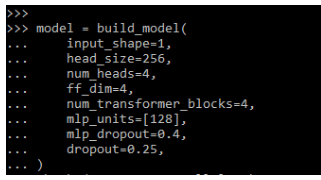
5. After building the model now in this step we are training the specified model.
Code:
model = build_model(
input_shape=1,
….
dropout=0.25,
)Output:
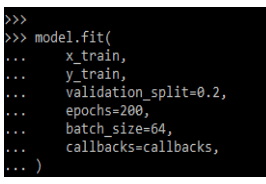
6. After training the model now in this step we are evaluating the specified model.
Code:
model.fit(
x_train,
y_train,
…..
Callbacks = callbacks,
)Output:
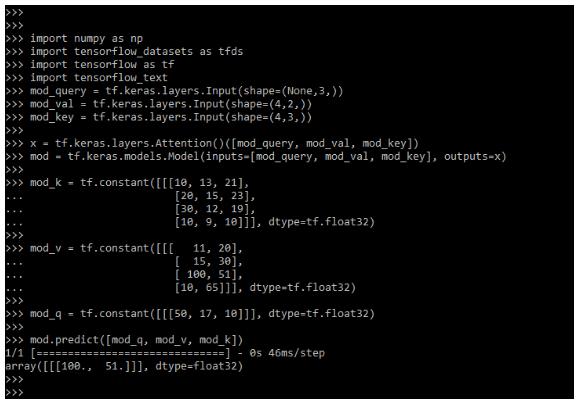
Keras Transformer Model
Neural network for machine translation contains the encoder for reading input sentences and generating the representation. The keras transformer decoder will generate output sentences one by one by consulting the representation which was generated by the encoder. The transformer is starting generating initial representations. Those steps are repeated multiple times in parallel for generating new representations.
The below example shows how we can define the keras transformer model as follows.
Code:
import numpy as np
import tensorflow_datasets as tfds
import tensorflow as tf
import tensorflow_text
mod_query = tf.keras.layers.Input (shape=(None,3,))
mod_val = tf.keras.layers.Input (shape=(4,2,))
mod_key = tf.keras.layers.Input (shape=(4,3,))
x = tf.keras.layers.Attention ()([mod_query, mod_val, mod_key])
mod = tf.keras.models.Model (inputs = [mod_query, mod_val, mod_key], outputs = x)
mod_k = tf.constant([[[10, 13, 21],
[20, 15, 23],
[30, 12, 19],
[10, 9, 10]]], dtype = tf.float32)
mod_v = tf.constant ([[[ 11, 20],
[ 15, 30],
[ 100, 51],
[10, 65]]], dtype = tf.float32)
mod_q = tf.constant([[[50, 17, 10]]], dtype = tf.float32)
mod.predict ([mod_q, mod_v, mod_k])
mod.summary ()Output:
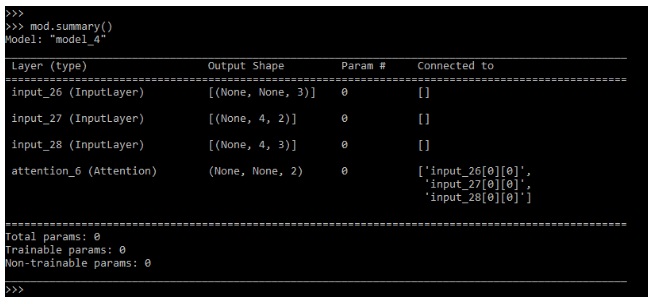
Keras Transformer and NLP
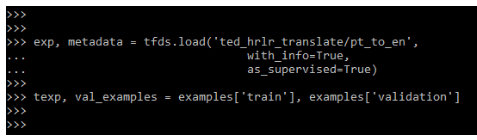
Transformers will excel in the sequential data from the natural language. In the below example, we are loading the dataset as follows.
Code:
exp, metadata = tfds.load('ted_hrlr_translate/pt_to_en',
with_info=True,
as_supervised=True)
texp, val_examples = examples['train'], examples['validation']Output:
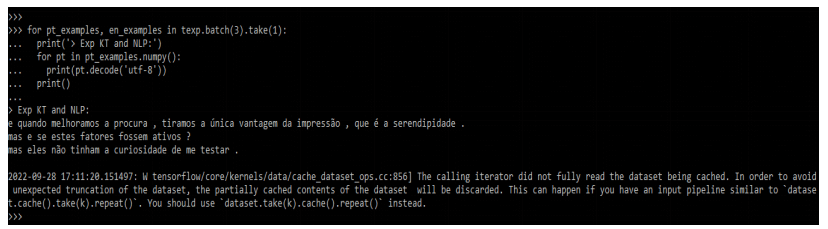
After loading the dataset now in this step we are printing the details of NLP from the dataset as follows.
Code:
for pt_examples, en_examples in texp.batch(3).take(1):
print('> Exp KT and NLP:')
for pt in pt_examples.numpy():
print(pt.decode('utf-8'))
print()Output:
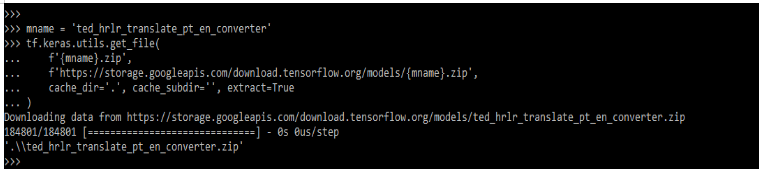
After printing the data now, we set up the tokenizer. We are creating the zip file for the same.
Code:
mname = 'ted_hrlr_translate_pt_en_converter'
tf.keras.utils.get_file(
f'{mname}.zip',
f'https: …. /{mname}.zip',
cache_dir ='.', cache_subdir='', extract=True
)Output:
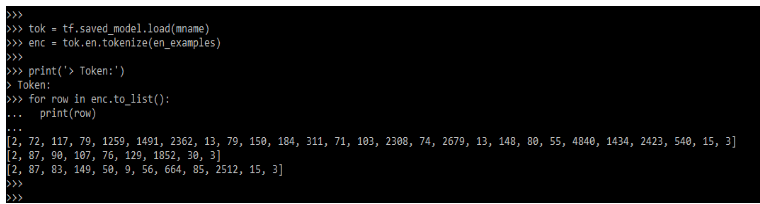
Now in the below example, we are using a tokenizer to convert the batch of strings that was padded into the token ID.
Code:
tok = tf.saved_model.load(mname)
enc = tok.en.tokenize(en_examples)
print('> Token:')
for row in enc.to_list():
print(row)Output:
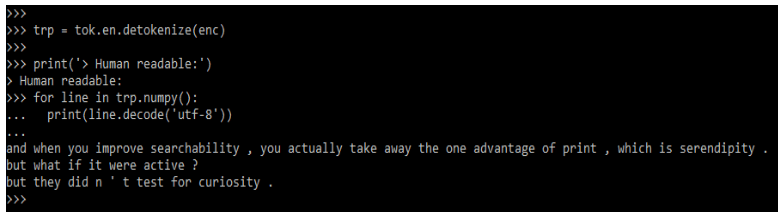
In the below example, we are using the detokenize method to read the data in the human-readable text.
Code:
trp = tok.en.detokenize (enc)
print('> Human readable:')
for line in trp.numpy ():
print(line.decode('utf-8'))Output:
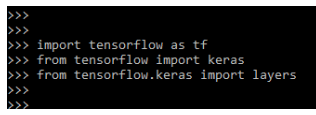
Keras Transformer Text Classification
While defining the keras transformer with text classification we need to import the module and prepare the dataset. In the below example, we are importing the modules.
Code:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layersOutput:
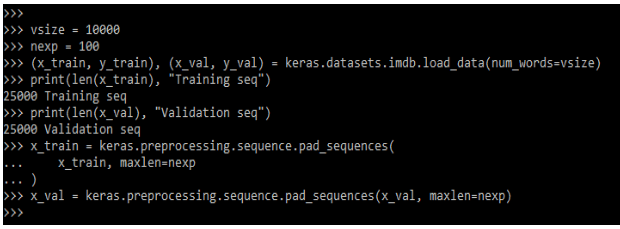
After importing the module we need to download and prepare the dataset as follows.
Code:
vsize = 10000
nexp = 100
(x_train, y_train), (x_val, y_val) = keras.datasets.imdb.load_data (num_words=vsize)
print(len(x_train), "Training seq")
print(len(x_val), "Validation seq")
x_train = keras.preprocessing.sequence.pad_sequences(
x_train, maxlen=nexp
)
x_val = keras.preprocessing.sequence.pad_sequences(x_val, maxlen=nexp)Output:
After downloading and preparing the dataset now below we are defining the hyperparameters.
Code:
embed_dim = 12
num_heads = 12
ff_dim = 12
num_experts = 10
batch_size = 50
learning_rate = 0.001
dropout_rate = 0.25
num_epochs = 3
nbatch = (
batch_size * nexp
)
Print (f" Token Num: {nbatch}")Output:
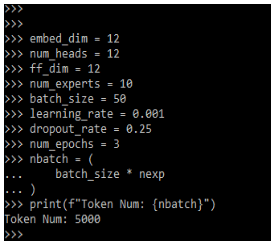
After defining the hyperparameters now in this step we are implementing the position and token of the embedding layer as follows.
Code:
class TEM(layers.Layer):
def __init__(self, maxlen, vsize, embed_dim):
super(TEM, self).__init__()
self.token_emb = layers.Embedding (input_dim=vsize, output_dim=embed_dim)
self.pos_emb = layers.Embedding(input_dim=maxlen, output_dim=embed_dim)Output:
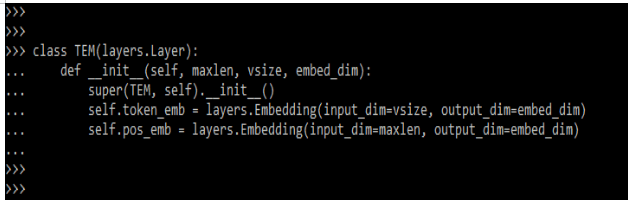
After implementing token and position now in this step we are training and evaluating the model.
Code:
def run_experiment(classifier):
classifier.compile(
optimizer=keras.optimizers.Adam(learning_rate),
loss="sparse_categorical_crossentropy",
metrics=["accuracy"],
)
his = classifier.fit(
x_train,
y_train,
batch_size=batch_size,
epochs=num_epochs,
validation_data=(x_val, y_val),
)
return hisOutput:
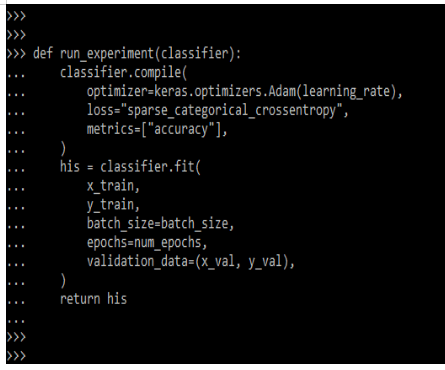
FAQ
Given below are the FAQs mentioned:
Q1. What is the use of keras transformer?
Answer: This model is used to obtain the sequential data which was defined in the natural language. This is more efficient.
Q2. Which module do we need to import while using the keras transformer?
Answer: While using it we need to import the keras, tensorflow, and numpy module in our project code.
Q3. Why keras transformer is significant?
Answer: Transformer will excel the sequential data modeling, we can say that natural language. It is more efficient and it is parallelized into several hardware like GPU.
Conclusion
We are using a top-down approach while building the intuitions behind the architechture of the transformer. It is used to model sequential data in a natural language. It is more efficient and it was parallelizable by using several hardware like GPUs and TPUs.
Recommended Articles
This is a guide to Keras Transformer. Here we discuss the introduction, how to use keras transformer. model and text classification. You may also have a look at the following articles to learn more –
