Updated April 6, 2023

Introduction to Kubernetes Autoscaling
As we know, Kubernetes is a container resources management and orchestration tool or, in simple words, a container management technology to manage containerized applications in pods across physical, Virtual, and Cloud environments. Kubernetes is inherently scalable with many tools that allow both applications as well as infrastructure nodes; to scale in and out based on demand, efficiency, threshold/limits and several other metrics. We have three kinds of autoscaling available, which we will try to elaborate on in this article.
- Vertical Pod Autoscaling (VPA)
- Horizontal Pod Autoscaling (HPA)
- Cluster Autoscaling (CA)
How does It Work?
Autoscaling is performed using the conditions set by us in configuration parameters on the command line, environment variables, and monitoring metrics. Let’s discuss the three types of autoscaling: –

1. Vertical Pod Autoscaling (VPA)
The VPA is only concerned with increasing the resources available to a pod that resides on a node by giving you control by automatically adding or reducing CPU and memory to a pod. VPA can detect out of memory events and use this as a trigger to scale the pod. You can set both minimum and maximum limits for resource allocation.
2. Horizontal Pod Autoscaling (HPA)
The HPA is what you can say is the main functionality of Kubernetes and will be using mostly. HPA can change the number of replicas of a pod, scale pods to add or remove pod container collections as needed. HPA achieves its goal by checking various metrics to see whether preset thresholds have been met and reacting accordingly. HPA takes care of scaling and distributing pods over the entire available nodes.
3. Cluster Autoscaling (CA)
CA automatically adds or removes nodes from a cluster node pool in order to meet demand and save money. It scales up or down the number of nodes inside your cluster. CA scales your cluster nodes based on pending pods. It periodically checks whether there are any pending pods and increases the size of the cluster if more resources are needed and if the scaled-up cluster is still within the user-provided constraints. In the latest versions of Kubernetes, it can interface with multiple cloud providers like Google Cloud Platform to request more nodes or remove used nodes.
Scaling is done based on metrics. There are three kinds of metrics:
- Default per pod resource metrics: – Like CPU, Memory, these metrics are fetched from the resource metrics API for each
- Custom per pod metrics: -These are such metrics which are not under the default category, but scaling is required based on the same. it works with raw values, not utilization values.
- Object metrics and external metrics: – a single metric is fetched, which describes Pod. This metric is then compared to the target or threshold value.
Benefits Of Kubernetes Autoscaling
There are several benefits we can list, but below are the primary ones, which I would like you to inculcate: –
- Today where our IT infrastructure is on Cloud and is Virtual, where costs are consumption-based. Kubernetes have the capacity to deploy and manage pods, pod clusters and automatically scale the overall solution in numerous ways. This is a tremendous asset and capability to reduce overall monthly.
- The ability to do dynamic resource management to not only individual containers but also to automate, scale and manage application state, Pods, complete clusters and entire deployments helps to ease your workload and ease the system administrator operations, especially when your environment is undergoing migrations, new environment creation and
- In the environments where the same nodes are used for VMs as well as Pods, Kubernetes autoscaling will help to make sure that you always have enough compute power to run your tasks.
Setting Up Kubernetes Autoscaling
Before starting to set up Kubernetes Autoscaling in your environment, you must first understand your environment and current as well as future needs of resources or pods.
Taking the below setup as an example, please consider below:
- Our Infrastructure is only Test Environment
- We must have a metrics server to collect custom metrics from Pods, based on which scaling will be done.
- Here we will show you how to set up HPA.
- We will set CPU metric to check, for which we set limit and accordingly, Pods can get created if CPU percentage increases.
Also note, the Horizontal Pod Autoscaler is an API resource in the Kubernetes autoscaling API group. The current stable version, which only includes support for CPU autoscaling, can be found in the autoscaling/v1 API version. When you create a Horizontal Pod Autoscaler API object, make sure the name specified is a valid DNS subdomain name.
Here we have a setup for HPA, for which we have some pre-requisites done beforehand:
- Kubernetes master
- Application cluster deployed in a single node.
- Docker, Kubeadm packages installed and configured on master as well as minion/worker nodes.
- Configuration for docker and Kubernetes is already done.
- An application like ngnix’s docker image is used in this lab.
To achieve HPA, you can do autoscaling in two ways.
1. Creating a YAML File
- First, create a Deployment using a Yaml file named “ngnix.yaml” like below:

- Then use the kubectl command to apply it and implement it.

- Check the number of pods deployed in this deployment. As you can see, there are 3 pods replicas created.
![]()
- Create an HPA file like below: –
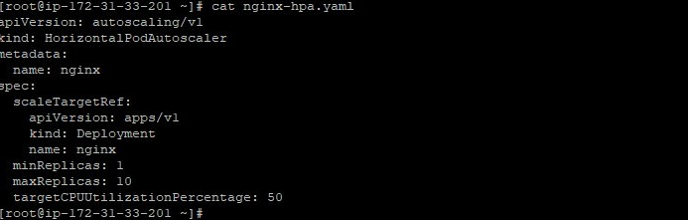
- Then apply this using

- You can check HPA status:

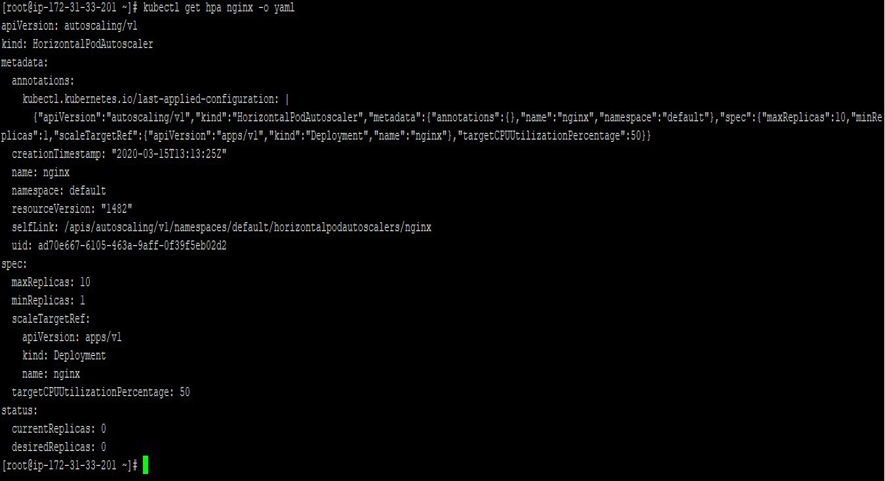
- To get details about the HPA, you can use “kubectl get hpa” with the “-o yaml.”
The status field contains information about the current number of replicas and any recent autoscaling events.
2. Use Command Line
- Set a new deployment or use the one which is deployed in step 1 viz. named “nginx.”
- To create HPA in a single command like below

- Check HPA status

Conclusion
Kubernetes Autoscaling is what we can say is the core of Kubernetes which you must use in a production environment to ease your job. Having Kubernetes skills with hands-on experience in Autoscaling make you a competent Kubernetes Administrator. Put in mind, Autoscaling is what should be on your To-Do list when designing an architecture that uses container-based microservices with Kubernetes, especially when running hybrid systems, including multi-cloud and on-premises deployments.
Recommended Articles
This is a guide to Kubernetes Autoscaling. Here we also discuss the Introduction and how to work Kubernetes Autoscaling? along with different examples and its code implementation. You may also have a look at the following articles to learn more –

