Updated April 18, 2023

Introduction to Linux Regular Expression
The Linux regular expression, basically it is a sequence of characters or string that would define the searching pattern. These searching patterns are used by the string search algorithms like vim, vi, sed, awk, find, grep, etc. It is a very powerful tool in Linux. We can use the same regular expression to identify or search the complex values in terms of row and column level. The Linux regular expression is also called as regexp or regex.
Syntax of Regular Expression command:
search/read command<pattern><fileName>- search/read command: We can use any searching or reading command in Linux like vim, vi, sed, awk, find, grep, etc.
- pattern: We need to provide the regular expression pattern in the syntax.
- file name: Input file.
How Linux Regular Expression Command works?
The regular expression is nothing but a symbolic representation in the searching algorithm. In any search algorithm, we need to pass these regular expressions to identify the complex string available in the input string or input data.
There are lots of different types of regular expression available in the Linux ecosystem.
| Sr. No | Regular Expression Symbol | Description |
| 1 | . | It will replace any character. |
| 2 | /b | It will match the empty character or string at the edge. |
| 3 | /B | It will match the empty character or string at the non-edge. |
| 4 | ^ | It will match the string of the string. |
| 5 | \< | It will match the empty string in the beginning at the word. |
| 6 | $ | It will match the character at the end of the string. |
| 7 | \> | It will match the empty string at the end of the word. |
| 8 | \ | It will represent the special characters. |
| 9 | () | It will group the regular expressions. |
| 10 | ? | It will match the same or exactly one character. |
Examples of Linux Regular Expression
Given below are the examples mentioned:
Example #1
Regular Expression with “^” symbol.
In the Linux regular expression, we are able to search the starting of the string associated with the “^” symbol. To search the string we need to use any text/string editor or searching algorithm.
Code:
cat file.txt | grep ^tExplanation :
We are having a sample directory, in the same directory there is filename “file.txt”. There are records in it. We are using the file.txt as an input to Linux regular expression. We need to identify the records that are starting with character “t”.
Output:

Example #2
Regular Expression with “$” symbol.
In the Linux regular expression, we are able to search the ending of character or string associated with the “$” symbol. To search the string, we need to use any text/string editor or searching algorithm.
Code:
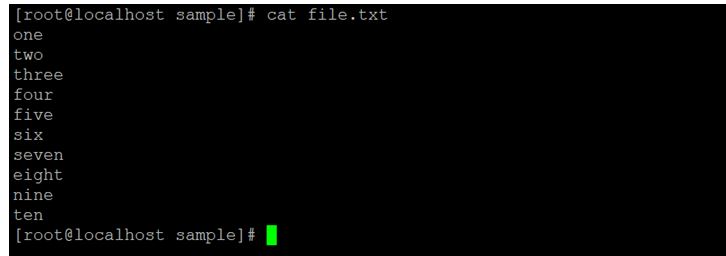
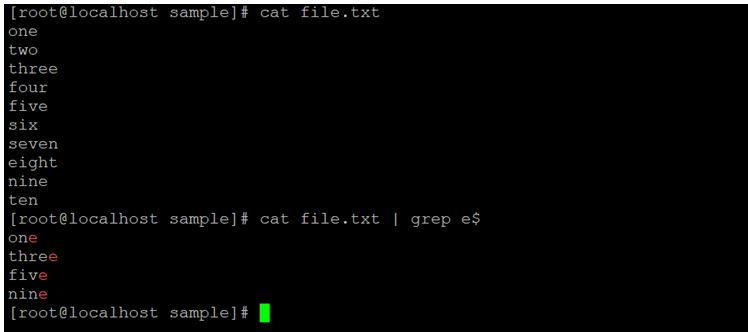
cat file.txt | grep e$Explanation:
In the same directory, there is filename “file.txt”. There are few records in it. We are using the file.txt as an input to Linux regular expression “$”. We need to identify the records that are ending with character “e”.
Output:
Example #3
Linux Regular Expression – Interval.
There are different types of regular expression in Linux. Interval is one of them. With the help of interval expression, we are able to find the expression that are coming number of occurrences in a string.
We need to use the “-E” option with the character/string interval value.
Code:
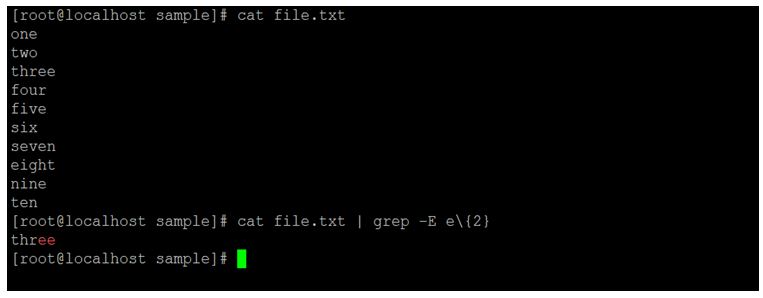
cat file.txt | grep -E e\{2}Explanation:
In the Linux ecosystem, we can able to search the different combination of character. As per the above command, we are able to find the same sequence of character number of time as per the given value assign in the command. We are identifying the sequence of character “e” coming two times in the string.
Output:
Example #4
Regular Expression with “\+” symbol.
In the regular expression, we want to filter out the matches one or more occurrences of the previous character from the input file.
Code:
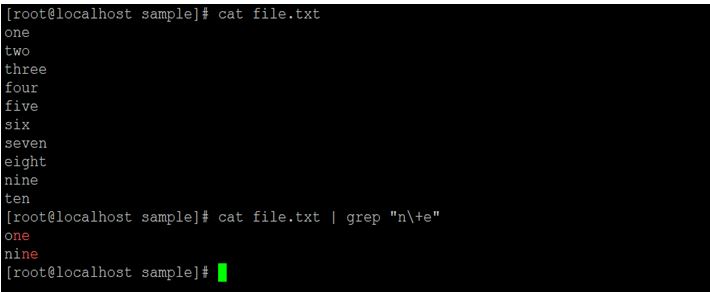
cat file.txt | grep "n\+e"Explanation:
We are using the input file as “file.txt”. We need to search the string from starting character as “n” and adjutant character as “e”. As per the above command, we are searching for a specific combination of characteristics from the input file.
Output:
Example #5
Regular Expression with Separating Words.
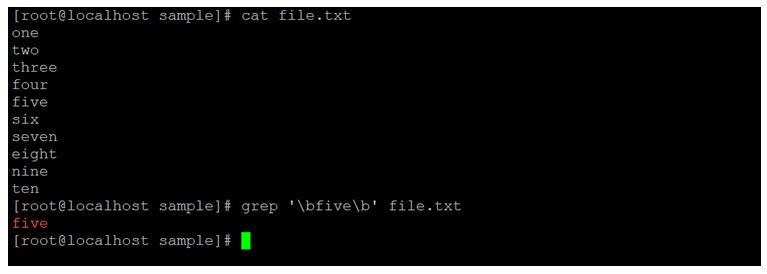
In the Linux Regular Expression, we are able to find the exact matching string from the input file. We need to use the “\b<string name>\b” option with any text/string editor or searching algorithm.
Code:
grep '\bfive\b' file.txtExplanation:
In Linux regular expression, we are able to find a specific string or character from the input file/data. As per the above command, we specific regular expression to find the exact string. We are using “\b\b” option into which we need to keep the search string.
Output:
Example #6
Regular Expression with “*” symbol.
In Linux regular expression, we are able to find or search the zero matches or more times in the preceding character. We need to use the “*” option with any text/string editor or searching algorithm.
Code:
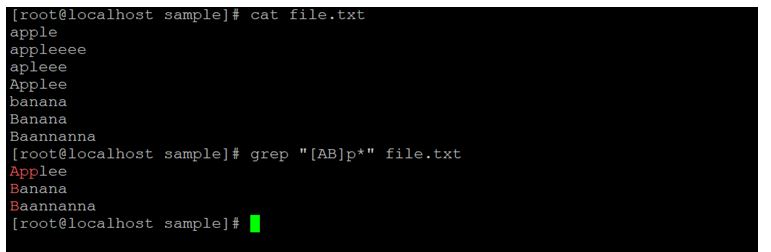
grep "[AB]p*" file.txtExplanation:
As per the above command, we are identifying the only “A” & “B” upper cases character and all character or string from the lowercase letter “p”. Accordingly, the given input we are able to get the relevant string from the input file.
Output:
Example #7
Expression with “\?” symbol.
In the regular expression, we want to filter out the matches zero or more occurrences of the previous character from the input file.
Code:
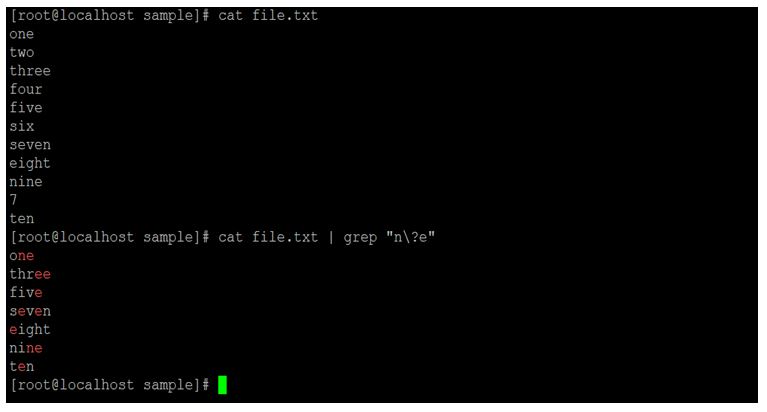
cat file.txt | grep "n\?e"Explanation:
We are using the input file as “file.txt”. We need to search the string from starting character as “n” and adjutant character as “e”. As per the above command, we are searching a specific combination of characteristics from the input file and it will search all the character come under the input file.
Output:
Conclusion
We have seen the uncut concept of “Linux Regular Expression Command” with the proper example, explanation and command with different outputs. The regular expression is a very powerful command tool to process any type of data. It is widely used in shell/bash jobs, searching tools, etc.
Recommended Articles
We hope that this EDUCBA information on “Linux Regular Expression” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

