Updated June 20, 2023
Introduction to Linux Split Command
In the Linux operating system, the split command is used to divide or split the large files into small file sizes. We can provide or define the number of lines available in the split file per the requirement. But by default, there are 1000 lines available in the split file. When we are creating any split file, the prefix will be PREFIXaa, PREFIXab, PREFIXac, and further on. The initial prefix will start with the letter “x.” Generally, the split command is used for the huge log or archival data.
Torbjorn Granlund and Richard M. Stallman wrote the split utility.
Syntax:
split [ OPTION ]... [ INPUT [ PREFIX ] ]- split: We can use the “split” keyword in the syntax or command. It will take different arguments like options and input files (like a log or archive). As per the provided arguments, it will split the large file into small files.
- OPTIONS: We can provide the different flags as the option that is compatible with the “split” command.
- INPUT: We can provide the file or file path to the split command per the condition or requirement.
- PREFIX: If we do not need the default prefix format and we need our own prefix format, then we can use the same option.
How Linux Split command works?
Linux is a multi-user support operating system. It will support multiple servers or applications. While running these servers or applications, they generate huge size logs. It is very difficult to access the log and read the same log files. In the Linux environment, we have multiple tools and utilities for resizing large files into small files. The split command is one of them. The spilled command is used to divide large files into small files. The default split size will be 1000 lines. As per the requirement, we can change the default size as well.
Below are the lists of options that are compatible with the split command.
| Sr No | Option | Description |
| 1 | -a, –suffix-length=N | It will help to generate the suffix of “N” length. The default size is “2”. |
| 2 | –additional-suffix=SUFFIX | It will help to append the additional SUFFIX to the file names. |
| 3 | -b, –bytes=SIZE | It will help to keep the SIZE bytes per output file |
| 4 | -C, –line-bytes=SIZE | It will help to put at most SIZE bytes of lines per output file |
| 5 | -d, –numeric-suffixes[=FROM] | It will help to use the numeric suffix instead of the alphabetic suffix. The changes from the start value are “0” (default value). |
| 6 | -e, –elide-empty-files | it will help not to generate empty output files with ‘-n’ |
| 7 | –filter=COMMAND | It will help to write the shell COMMAND. But the file name will be “$FILE” |
| 8 | -l, –lines=NUMBER | It will help to put the NUMBER lines per output file |
| 9 | -n, –number=CHUNKS | It will help to generate the CHUNKS output files |
| 10 | -u, –unbuffered | It will help to copy input to output with the immediately ‘-n r/…’. |
| 11 | –verbose | It will display the command operation and diagnostic just before each output file is opened |
| 12 | –help | It will print the split command help and exit automatically. |
| 13 | –version | It will print the split command version information and exit automatically. |
Examples to Implement Linux Split Command
In the Linux environment, we can split the large file into small files.
Example #1 – Linux Split Command
Command :
split spreadsheet.csv
llExplanation :
As per the above command, we are splitting the “spreadsheet.csv” file. Once we have split the file, it will split the files into 5 different files. The individual split files contain 1000 rows.
Output :

Example #2 – With Custom Line Numbers
In the split command, we have the functionality to split the large file into a number of custom output lines.
Command:
split -2100 spreadsheet.csv --verboseExplanation:
As per the above command, we are splitting the files into 2100 rows each. Here, we are providing custom inputs. We have used the “–verbose” option to display the current running outputs.
Output:

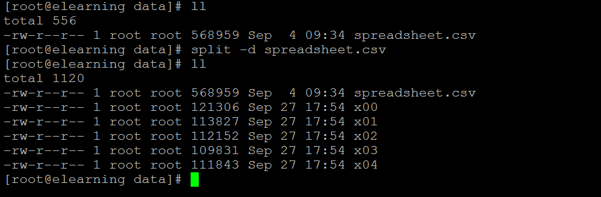
Example #3 – Create Numeric Suffix Split Files
While working with the Linux Split Command, we can change the split suffix from the alphabet to numeric.
Command:
split -d spreadsheet.csvExplanation:
While splitting the large files, the split files will be in alphabetical order. But we have used the “-d” with the split command and changed the suffix with a numeric value.
Output:
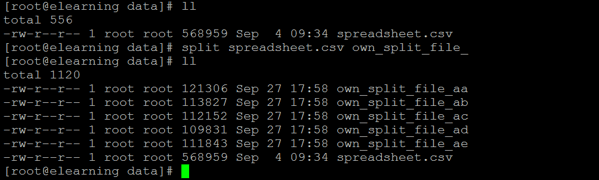
Example #4 – Custom Suffix Name
In Linux, we have the functionality to give the own or custom suffix name to the split command.
Command:
split spreadsheet.csv own_split_file_
llExplanation:
As per the above command, we are splitting the large file “spreadsheet.csv” into small files. We have split the output files into our own custom files. For custom files, we have started with “own_split_file_”.
Output:
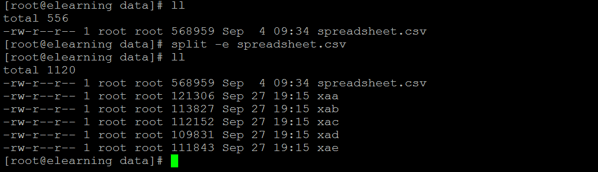
Example #5 – Avoid Zero Size Split Output Files
In the split command, while splitting the large file, it might be at the end the small or zero sizes will create. To avoid this event, we can use the “-e” option with the split command.
Command:
split -e spreadsheet.csvExplanation:
While splitting the large files into small files, it may happen that at the end zero size file will create. To avoid this condition, we can use the “-e” option with the split command. It will avoid the zero-size file creation.
Output:
Conclusion
We have seen the uncut concept of “Linux Split Command” with the proper example, explanation, and command with different outputs. As per the requirement, we can split the large file into small file sizes (or the number of rows). With the help of a split command option, we can read or access a huge size file.
Recommended Articles
We hope that this EDUCBA information on “Linux Split Command” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

