Updated March 14, 2023

Introduction to Logstash Codec
The logstash codec plugin will modify the events with specific data representation and the stream filters that can be used for either input or output the CSV data will be validated and parsed on the Codecs it has single and multiline codec plugin the messages are merged to the single event supported with the multiple hosts for handling the multiline events resulted with the data stream mixing and corrupted event data.
What is Logstash Codec?
The codec plugin is mainly used to encode or decode incoming or outgoing events from the Logstash that can be used with both input and output data as well. The input codecs data are rendered with the convenient way for decoding the data before entering the input and output codecs provide the way for the logstash plugins. It provides the infrastructure for automatically generating the documentation for the plugin using the ascii doc format for writing the documentation in the source code to the HTML format.
Logstash Codec Plugins
The codec is the logstash name that can be used to represent the data for utilizing both inputs and outputs the byte field is one of the string type fields that represents the valid input bytes. It is a more convenient way to declare the specific sizes of the plugin options in addition to the input plugin the logstash events will share the common configurations option such as the filter events types down the pipeline. Logstash input plugins will perform the events into the shared common configurations with arbitrary tags for representing the datas. Plugins may be of any type that can be represented as the utility in the bin folder of the Logstash installation directory. All the plugins with specific settings help to specify the important fields like Path, Ports, etc. Delimiter codec plain will be used to decode the data before entering the Logstash pipeline the new line specified the delimiter and the input time interval calculate it as seconds discovering new files in the specified path. Using path keyword the file path will contain the file patterns plugin have satisfied all the settings Logstash requires mainly Java 8 or Java 11 and more versions by using the config file we can utilize and specified the plugins want to use and settings with meet criteria. Main plugins contain the collection of the inputs, filter, codec, and output settings as self-contained packages that are hosted on the domains.
It has n number of plugins and it has been validated using the Github repository, some of the plugins like below,
- Avro,
- Cef,
- Cloudfront,
- Cloudtrail,
- Csv,
- Edn,
- Dots,
- plain
These plugins provides a separate infrastructure to generate the documentation for the Logstash projects.
We can install dependencies like the below command,
bundle install
bundle exec rspec
By using the below command we can clone the plugins
gem "logstash-filter-awesome", :path => "/your/local/logstash-filter-awesome"
Following commands helps to install the plugins
logstash path-plugin install –no-verify
We can run the below command for executing the Logstash in the customized plugins.
logstash path -e ‘filter {values {}}
Logstash codec Configuration
It is mainly ELK based data pipeline but it is still considered as the main point of the stack with a piece of software that contains a lot of nooks and crannies mastered for logging the data more confidently. By using Logstash configuration the data pipeline will be flowed and configured to the logstash.yml like .conf file. We can represent the reference event fields with the additional configuration and use the conditionals for the process events that meet certain criteria. When we can run the logstash with the specific config file parameter command as the -f to execute the logstash config file for the specified operations.
The first step is to create the config file and use it to run the Logstash. Logstash-name. conf is the file name extension to save the file with the same or different directories.
input {
stdin {
}
}
output
{
elasticsearch { hosts => [“localhost:9200”] }
stdout {codec => java}
}
The above code is the basic readable format for the specified configuration file and we get the output results in both elasticsearch and stdout. We can also see the readable message like Elasticsearch Unreachable during the installation and up the port like 9200. Then we run the logstash on the specified config file for decoding the data before entering the inputs and it won’t be needed for the separate filter in Logstash pipeline output codecs are the basic convenient way and method for entering the data before leaving the output and Logstash pipeline. Output codecs are the user’s convenient and customized method for encoding the data before leaving the output of the separate filter using the Logstash pipeline. The TCP port for the JSON lines from the transaction analysis workbench for more concise for the log type records types on the workbench.
Logstash codec class
The logstash codec class is mainly called when the java is plugged into the machine java inputs API and the package is installed because the utility plugin will be installed with specified steps. If we used plugin API the logstash codebase will be called through the help of the git command. The branch_name should correspond to the Logstash version which contains the preferred revision of the java plugin API. So that java codecs are supported only java input and output plugins the design of the code is less mature and it is not been implemented through the logstash machine first copy and initi9alized the codec plugin using the below command like,
git clone –branch <branch_name> --branch type –branch version URL <target folder>
The branch_name, branch_type should mainly correspond to the Logstash version which contains the preferred revision of the java plugin API. Beta version of the java plugin API is available in all the versions of the logstash codebase that do not specify with the target_folder type the logstash is available on the current folder type and settings. If the codec plugin will decode the messages separated by using the comma and delimiter configuration encoded messages with string or other data type representation will always be separated by the delimiter. The special character like “/” as the delimiter of the input strings like value1/value2 would be decoded into the separate events and the fields respectively like value1 and value2 edge cases.
The Multiline codec plugin will be configured mainly in the Changelog and the multiline codec will collapse the multiline message and merge to a single type of event.
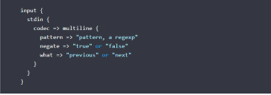
When we use Multiline codec in the logstash we used the above type codes as mentioned in the above screenshot. The Java stack traces are also configured through the multiline messages with the subsequent filters and line indented.
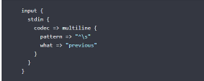
Some settings like below,
auto_flush_interval,
charset,
max_bytes
max_lines
multiline_tag
The above settings are configured to the Input type of Logstash user data and based on the requirement we can set it as Yes or NO in the Required attribute.
Conclusion
The Logstash codec is a plugin that is similar to other technology plugins that by using this plugin the user data is sent to the destination or target endpoint. Data are sent to the elasticsearch server with the help of the kibana intermediate or UI tool which helps to identify the data.
Recommended Articles
This is a guide to Logstash Codec. Here we discuss the Introduction, What is Logstash Codec, configuration, class, and Examples with code implementation. You may also have a look at the following articles to learn more –
