Updated March 13, 2023
Introduction to Logstash Pipeline
The logstash is an open-source data processing pipeline in which it can able to consume one or more inputs from the event and it can able to modify, and after that, it can convey with every event from a single output to the added outputs. Some execution of logstash can have many lines of code and that can exercise events from various input sources. In which the pipeline of it has three stages such as, inputs, outputs, and, filters, in which inputs can create the events, filters can modify the events, and outputs can craft them.
What is Logstash Pipeline?
In the logstash, there is a processing of data that will happen in a pipeline in which it can take in events from various inputs that can be converted through the mediator of pipeline and then that can be sent to each event up to different events. For the implementation of it we need to take lines of code and it executes the event by taking different inputs, it can allow us to check whether it has been installed or not by taking some steps once we have installed the components of the logstash pipeline then we can able to see nodes of it in the running pipeline which we can get in the monitoring tab, it has pipeline in which its processing has the three stages which are inputs, filters, and, outputs. The input can work for creating the events, and filters are the mediator to pass the components through the pipeline, and output is the destination in which the components which get passed that can be stored at the outputs, and the pipeline may be a single pipeline or multiple pipelines in which the single pipeline contain multiple inputs, multiple filters, and multiple outputs, and the multiple pipelines may contain the single inputs, filters, and a single output destination.
How to Create logstash pipeline?
We need to perform some steps let us see them,
- In the first step we need to install and configure apache web server, the access log is available in the web server that can give out the input to the pipeline of logstash. For this, we need to have one Linux system with internet access, and that can be installed and started by performing the commands,
sudo yum install -y httpd
sudo systemctl start httpd
sudo systemctl enable httpd
- After that we have to generate the pipeline configuration file, for that, we need to execute some code,
input
{
file {
path => "/var/log/httpd/access_log"
start_position => "initiating"
}
}
filter
{
grok {
match => {"sms" => "%{COMBINEDAPACHELOG}"}
}
date {
match => ["timespace" , "dd/MM/yyyy:HH:mm:ss Z"]
}
}
- After that, we need to access the Stash apache server with the help of the logstash pipeline,
“sudo /user/share/logstash -f /etc/logstash/conf.d/ourpipeline.conf”
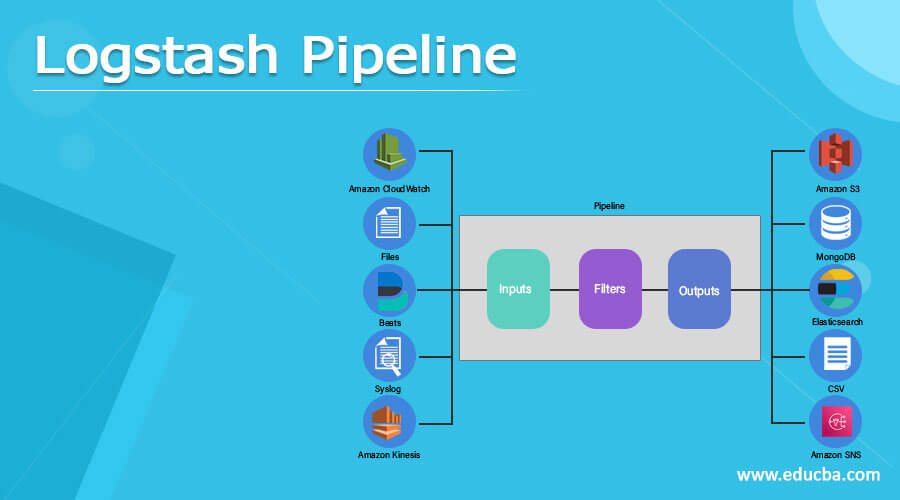
Logstash pipeline three stages (inputs, filters, outputs):
In the logstash it has events in which the pipeline of the event processing has three stages that are, inputs, filters, and, outputs, in short, the input can take part in the creating of the events. In such a way that filters can take part in modifying the events, and in the output section that two stages can come together as it will be the destination for the pipeline.
- Inputs:
The inputs are the first stage in the logstash pipeline in which it can be used to acquire data inside the logstash, it can manage various inputs as our data source, and that data source can be the plain file, syslogs, beats, cloud watch, kinesis, s3, etc.
- Filters:
Filters are works as a mediator while processing the devices in the pipeline of logstash, we can able to unite filters with the conditionals for executing an action on an event for fulfilling the required criteria, the logstash can assist various types of filters for processing the data such as gork, mutate, CSV, JSON, mutate, aggregate, etc.
- Outputs:
This is the last stage in the processing of the logstash pipeline, any event can move through various types of outputs but there is one condition that first have to complete the processing for all outputs and after that, the event will get finish the execution, the outputs stage in the logstash can have various types of outputs such as elasticsearch, cloud watch, CSV, sns, file, s3, MongoDB, etc, for storing and sending the data for final processing.
Example:
input
{
beats {
port => 5033
type => "beats"
}
tcp {
port => 5011
type => "syslog"
}
udp {
port => 5011
type => "syslog"
}
stdin {
type => "stdin"
}
}
filter
{
if [type] == "syslog"
{
grok
{
match => { "msg" => "%{SYSLOGTIMESTAMP:syslog_timespan} %{DATA:syslog_hname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_msg}" }
}
date
{
match => [ "timespan", "MMM dd HH:mm:ss", "MMM d HH:mm:ss" ]
}
} else if [type] == "beats"
{
json {
add_tag => ["beats"]
}
} else {
prune {
add_tag => ["stdin"]
}
}
}
{
if [type] == "syslog" or [type] == "beats"
{
elasticsearch
{
hosts => ["http://e2e-l3-0680-230:8200", "http://e2e-l3-0680-230:8200", "http://e2e-l3-0680-230:8200"]
}
} else {
stdout { codec => json }
}
}
Above is the example in which the single pipeline has been described, as we know the logstash can support the multiple pipelines also and that can be used for sectioning it into input, output, and, filters, in the above example we have defined the single pipeline which consisting of multiple input resources and we have also defined the multiple filters for each input resource in it, we have also defined the output which is the destination and that can make the decision on the basis of conditions.
Conclusion
In this article we conclude that the logstash has a pipeline which is the way that is provided by the logstash for configuring a file that may contain three stages which we have seen in this article, we have also discussed how to create the pipeline in the processing of the logstash.
Recommended Articles
This is a guide to Logstash Pipeline. Here we discuss the introduction, What is logstash pipeline, How to create a logstash pipeline? Example and applications. You may also have a look at the following articles to learn more –
