What is a Machine Learning Pipeline?
A machine learning pipeline is a systematic approach that automates the workflow of complete machine learning tasks. It consists of interconnected steps for building, training, deploying, and maintaining machine learning models.
Typical machine-learning pipelines provide:
- A structured framework for managing and maintaining a complete life cycle of machine-learning projects.
- They were helping data scientists and machine-learning engineers from data collection and pre-processing to model deployment and monitoring while maintaining efficiency.
- Reproducibility and Scalability for a wide range of applications.
In pipelines, each step is designed as an independent module and tied together to produce a scalable solution. These stages include data pre-processing, feature engineering, model training, model evaluation, and model deployment. The output of one stage serves as input for the next stage.
ML pipelines consist of a series of interconnected tasks, tools, and technologies to streamline different processes of machine learning models. This process involves experimentation with algorithms, model configurations, and feature engineering techniques to iterate and optimize model performance.
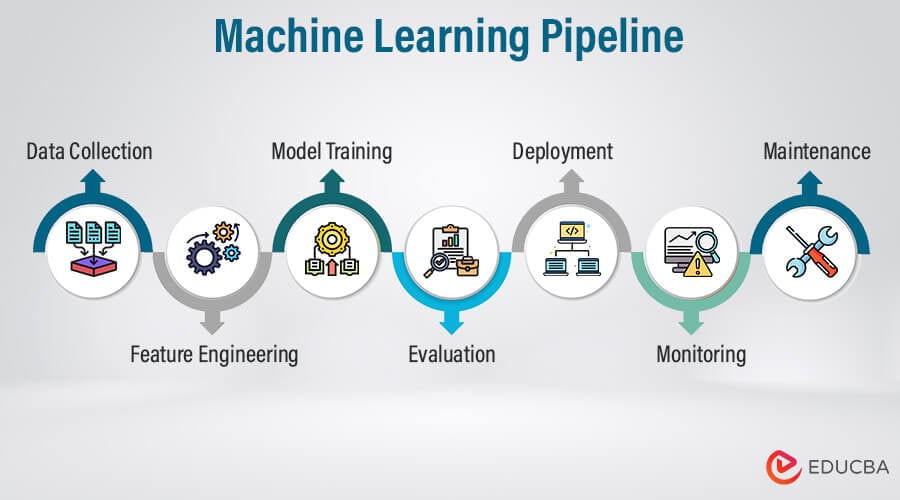
Table of Contents
Key takeaways
- Organize tasks into sequential stages to scale data size and model complexity.
- Flexibly incorporate required tools and technologies for project development.
- Easy collaboration among team members for development purposes by providing a shared framework.
- It aids in faster development, easier management, improved performance, better resource utilization, and reduced time-to-market of machine learning projects.
Spark ML workflow:
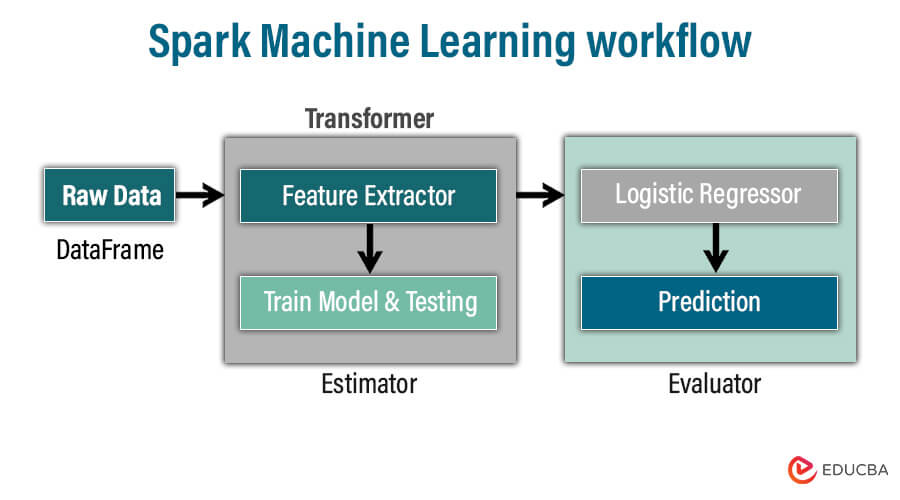
Spark ML or MLlib is a machine learning library provided by Apache Spark. It provides various tools and algorithms for effectively creating, honing, and implementing machine learning models on sizable datasets. The pipelines in spark ML chain different stages of machine learning as a single entity. This pipeline comprises a sequence of transformers and estimators that define the entire workflow of the ML models.
Transformer:
The transformer stage in spark ML takes the dataset as input and generates augmented datasets as output. It is a process of transforming input data into the required format for further analysis or processing. Transformer is vital in preparing data for modeling by transforming it into the format needed for machine learning algorithms to work efficiently. Spark ML transformer is used for text processing, feature encoding, normalization, and scaling.
For example, a tokenizer operates as a transformer that takes a text dataset as input and transforms it to tokenize words for analysis, where each word becomes an individual token. This transformation is essential for feature extraction or modeling.
Estimator:
Estimators learn from the data to produce a predictive model. The estimator algorithm fits the input dataset to generate a model, and the algorithm learns from the input data to develop a predictive model for predicting new data. The estimator works as a machine learning workflow training phase to understand relationships and patterns from the input data. Spark ML estimators have many machine learning algorithms comprising linear regression, support vector machines, neural networks, and decision trees.
For example, consider a logistic regression as an estimator which takes a dataset with labels and features to produce a logistic regression model.
In summary, the transformer pre-processes the data in the required format, and the estimator learns from these data to produce predictive models, resulting in efficient and scalable machine learning models.
Components of ML Pipelines
- Data Collection and Pre-processing:
The initial step of the machine learning pipeline is to gather data from various sources and pre-process data to prepare for analysis by correcting and handling inconsistencies. The initial steps involve:
- Data Collection: The first stage of a machine learning pipeline is data collection, which involves gathering raw data from different sources like databases, files, APIs, or external repositories.
- Data cleaning: The collected data is processed to clean by handling missing values and correcting errors and inconsistencies. Different techniques, such as imputation, deduplication, and outlier detection, are employed to ensure data quality for analysis.
- Data transformation: After cleaning, the data is transformed into a relevant format for analysis. Data transformation involves encoding categorical variables into numerical features, scaling numerical features to a similar range, and pre-processing tasks.
- Exploratory Data Analysis (EDA)
Exploratory Data Analysis provides insight into data for a better understanding of data characteristics, distribution, and relationships before model training various methods such as
- Data Visualization: Visualize data using graphs, histograms, charts, and scatter plots to understand patterns, relationships, and distribution inside data.
- Statistical Analysis: Analysis of the statistical measures to summarize data characteristics and properties such as mean, median, standard deviation, and correlation coefficient to gain insight into data central tendency and relationships and detect discrepancies.
- Correlation Analysis: The strength and direction of a linear relationship are examined through an analysis of the correlation between the various variables.
- Feature Engineering:
By using domain expertise to create new features or choose the most pertinent one from the data, feature engineering turns unstructured data into meaningful features that improve the predictive and generalization capabilities of the model.
- Feature Creation: Upgrades model performance by generating new features from the existing feature through interaction, transformations, or domain knowledge.
- Feature selection: Identify and select the relevant feature to improve the model’s predictive power while reducing dimensional and computational complexity. Techniques like feature importance ranking, univariate feature selection, or model-based selection are employed for identification.
- Feature scaling and normalization: Numerical features are scaled to an analogous range to enhance the stability and convergence of these machine learning algorithms.
- Model Selection:
Model selection involves choosing a suitable machine learning algorithm or technique according to the problem type, performance requirement, and data characteristics while considering different factors like complexity, interpretability, and scalability.
For prediction tasks, supervised learning algorithms like K-nearest neighbors, decision trees, logistic regression, and linear regression are chosen.
Data scientists select unsupervised learning algorithms like k-means clustering, hierarchical clustering, or principle component analysis for clustering or anomaly detection tasks.
- Model Training:
Train the selected model on the training dataset with the selected algorithm and refine parameters to optimize the performance. The model can discover patterns and relationships in the training data by dividing the dataset into training and validation sets.
- Model Fitting: Use training data to train a selected model with an optimization algorithm to maximize the observed data likelihood or minimize the loss function
- Model Evaluation and Validation
After training, data scientists evaluate the model using suitable performance metrics and validation techniques. It maintains robustness and aids in model selection and iteration.
- Model Evaluation: Different evaluation metrics such as accuracy, precision, F1-score, recall, and mean squared error are employed to quantify model performance according to the machine learning task.
- Cross-Validation: Validate the model’s performance and assess its generalization ability by implementing techniques such as k-fold cross-validation using different subsets of data for evaluation. These also mitigate overfitting.
- Hyperparameter Tuning:
Hyperparameters are the parameters set to optimize the model performance; different techniques, such as random search, grid search, and Bayesian optimization, are used to find optimal hyperparameters.
- Random Search: Randomly sampling Hyperparameter values to explore Hyperparameter space efficiently.
- Grid Search: Improve model performance by searching optimal combinations through a predefined grid of hyperparameters.
- Bayesian Optimization: Select hyperparameters based on past evaluations using probabilistic models to improve performance and convergence.
- Deployment and Monitoring:
- Model Deployment: Once the satisfactory model is trained and developed, it is deployed into production environments like APIs, web applications, or embedded systems to make predictions and decisions on new data.
- Monitoring: After deployment, monitoring the model’s performance continuously and addressing any issues is essential. Monitoring is vital to adapt to the changing data pattern and ensure model accuracy and reliability.
Machine Learning Pipeline Steps
Depending upon the application scenario and business requirement, each Machine learning pipeline may vary. However, the generalized process of each pipeline is the same. Here are the crucial steps of the Machine learning pipeline:
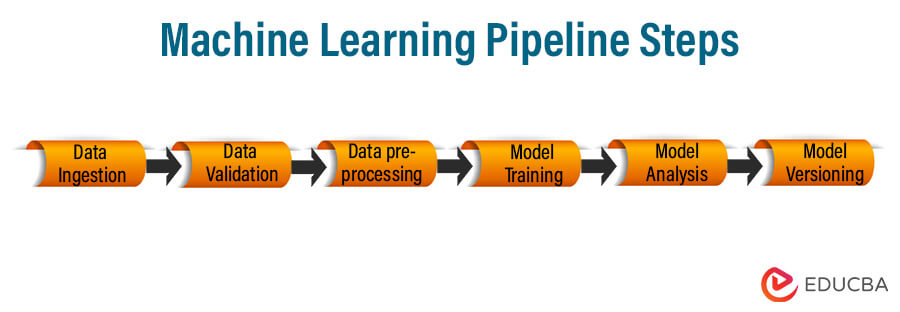
1) Data ingestion:
Data is gathered and transformed into a well-defined structure, which could be appropriate for future processes. This method excludes any feature engineering; instead, it executes versioning of incoming information.
2) Data Validation:
Before training a model, it is very much crucial to check the quality, reliability, and consistency of the data. In this step, the goal is to check the parameters of the new data, such as the number of categories, their range, and distribution, to detect any deviation. This validation can be easily handled using various tools to detect flaws.
3) Data pre-processing:
This is the most essential step of the machine learning pipeline as it cleans, transforms, and normalizes the raw data. Sub-steps in pre-processing may include data cleaning, feature scaling, handling missing values, and encoding the categorical variable. After this step, data is finally ready for training and testing purposes.
4) Model training and tuning:
In this step, we train the model to accept pre-processed data (from step 3) and generate accurate predictions. However, challenges arise when working with large datasets and complex models. To address this, we can distribute training or tuning tasks efficiently. Pipelines address this by being scalable, enabling concurrent processing of numerous models, thus mitigating issues encountered during the model training stage.
5) Model analysis:
This step doesn’t just involve enhancing parameters using accuracy metrics but also incorporates a thorough assessment of the model’s performance.
This assessment includes parameters like AUC (area under the curve), recall, and precision. By computing these metrics, we gain insights into the nature of the model and its effectiveness. It is also valuable to understand the model’s dependence on its features and how its predictions can be influenced by altering those features.
6) Model versioning:
The model versioning step server sustains a track of the selected model, datasets, and set of hyper-parameters. This stage is essential because, in altering scenarios, significant fluctuations in model performance can emerge only by enhancing the training model without even changing any of its parameters. Therefore, documenting and diligently tracking all inputs in creating a new model version becomes paramount.
7) Model deployment:
After concluding training and analyzing the model, the next stage is deployment. Three popular deploying methods are using a model server, in a browser, and on an edge device.
The most popular one is using a model server. The model server enables you to host multiple model versions simultaneously.
You can conduct A/B tests on different versions and compare the results. Moreover, model servers ensure scalability and administration of deployed models, making it convenient to handle updates and improvements.
8) Feedback Loop:
The feedback loop is a closed-loop environment that allows data scientists to assess the efficiency and performance of developed models. This loop ensures uninterrupted progression by extracting insights from real-world applications and applying them to development. It can be executed manually or automatically, depending upon necessity.
Tools and Technologies for Building ML Pipelines
| Sr. No. | Steps | Corresponding Tools |
| 1. | Obtaining data | Managing data relies on various tools, which vary depending on the volume. The primary segments include database management and distributed storage.
1. Managing database: Managing a database involves choosing and selecting a database management system that fits the specific needs of the data. Popular database software for managing databases is:
2. Distributed storage: When a single site cannot handle the storage needs for a large amount of data, administrators utilize various storage solutions to manage it effectively, like
|
| 2. | Cleaning Data | The cleaning data process enhances the quality of the data to make it precise, uniform, reliable, and error-free. This incorporates three major steps scripting the language, processing in a distributed manner, and data wrangling. The popular tools for these three steps are
1. Scripting language:
2. processing in a distributed manner:
3. Data wrangling Tools –
|
| 3. | Data Exploration and Data Visualization to identify the trends and patterns. | It is a technique where data is studied to find its characteristics and patterns for further predictions. The tools used to execute such activity are
|
| 4. | Modeling the data to deliver predictions. | To effectively model the data, one can make use of machine learning algorithms and programming languages like Python and R.
|
| 5. | Interpreting Outcome | For interpreting results, a few popular tools are
|
What to Consider When Building a Machine Learning Pipeline?
While crafting a Machine Learning Pipeline, various technical aspects must be considered to sustain its efficiency, scalability, reusability, and reliability.
1) Create reusable components:
In the Machine learning workflow, it is important to bifurcate the processes into reusable and self-governing components. Initialize the development process focusing on data gathering and processing. It is preferable to narrow down the scope of each element so that it is convenient for the data scientist to comprehend and loop through it.
2) Testing:
Testing is the second half of any coding project. After development, schedule automated coding to check input data quality, compare ML model predictions to actual values, track model execution metrics, and identify any divergence.
3) Integration of all Steps:
We integrate all the steps into a well-defined structure and hierarchy. It’s essential to define the execution order for pipeline components, including dependencies between them and the flow of input and output through the pipeline.
4) Automated as needed:
As the machine learning pipeline is developed, it manages an automated workflow and handles different process steps without manual interference. You can also schedule automation for routine tasks, such as daily retraining or model updates, based on your organization’s needs and the changing nature of data. Implementing automation optimizes the ability and agility of the ML pipeline, ensuring proactive maintenance and adaptation to evolving data patterns.
Importance of ML Pipeline/Benefits of a Machine Learning Pipeline
The Machine Learning pipeline offers various benefits in optimizing the workflow of data modeling and preparation.
1) Unattended runs:
The machine learning pipeline ensures the administration of different tasks simultaneously with complete reliability and self-governance. This parallelism confirms enhanced utilization of resources and facilitates data scientists to concentrate on other tasks while the pipeline works on data processing and modeling steps concurrently.
2) Easy Debugging:
By bifurcating the machine learning workflow into various functions and components within the pipeline, it becomes convenient to manage the debugging process. Each task has its functions, which ensures narrowing and addressing the issues.
3) Easy tracking and versioning:
The Machine Learning pipeline gives a formatted approach for tracking and versioning inputs, outputs, and data sources. Data scientists can sustain a clean record of data manipulation and model looping by naming and versioning pipeline components.
4) Fast execution:
The component-oriented nature of the machine learning pipeline ensures simultaneous execution of pipeline stages, resulting in a speedy process accomplishment.
5) Collaboration:
Since the machine learning pipeline has a formatted and documented process, it is convenient for the entire team to quickly comprehend and participate in the project.
6) Reusability:
By crafting a scalable and reusable template for similar Machine learning scenarios, data scientists can preserve time, designing endeavors and deployment efforts. It is possible because Machine learning has adapted to standardized workflows across different projects and tasks.
7) Heterogeneous compute:
Due to the heterogeneous environment and numerous storage sites, multiple pipelines can work together in coordination. It ensures optimized resource utilization by executing separate pipeline processes on different computing resources like Virtual machines, GPUs, etc.
Conclusion
Machine learning pipelines streamline the workflow of different processes of machine learning models. ML pipelines orchestrate the flow of raw data through each stage of pre-processing, feature engineering, training, evaluation, and deployment. In pipelines, each stage output is input for the next stage, ensuring a streamlined development process while improving the model performance and reducing development time.
Frequently Asked Questions (FAQs)
Q1. What are some common obstacles encountered while deploying a Machine learning pipeline in a production environment?
Answer: The obstacles encountered while deploying the machine learning pipeline in a production environment are
- Sustaining uniformity and consistency between development and production environment.
- Ensuring expandability to administer big chunks of data and user requests.
- Collaborating with the existing system
- Ensuring model versioning and upgradation.
- Surveillance for efficiency deterioration over a while.
Q2. How are data privacy and security issues managed within the machine learning pipeline?
Answer: Managing data privacy and security concerns in the machine learning pipeline incorporates measures such as
- De-identification and data encryption.
- Adapting standard protocols like GDPR and HIPAA.
- Authentication and access control mechanism.
- A well-designed data security assignment for data scientists and engineers.
- Regular upgradation of data safeguarding mechanism.
Q3. Explain the term interpretability in the machine learning pipeline.
Answer: Interpretability is understanding how models execute predictions, derive perceptions, and ensure model transparency and responsibility. To optimize interpretability, one can utilize linear models derived from decision trees, conduct feature importance analysis, employ model-agnostic methods, and utilize LIME and SHAP to explain individual predictions.
