What is MapReduce Algorithm?
MapReduce Algorithm is mainly inspired by the Functional Programming model. It is used for processing and generating big data. These data sets can be run simultaneously and distributed in a cluster. A MapReduce program mainly consists of map procedure and a reduce method to perform the summary operation like counting or yielding some results. The MapReduce system works on distributed servers that run in parallel and manage all communications between different systems. The model is a special strategy of split-apply-combine strategy which helps in data analysis. Mapping is done by the Mapper class and reduces the task is done by Reducer class.
Understanding
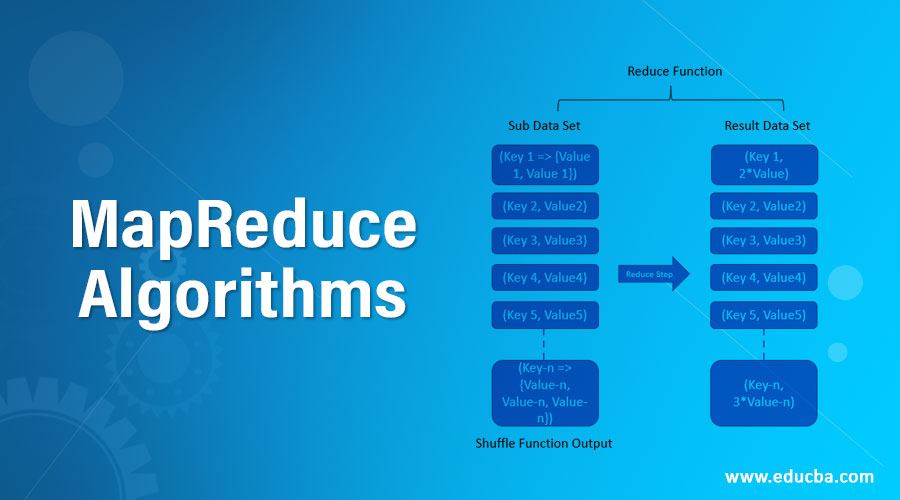
MapReduce Algorithm mainly works in three steps:
- Map Function
- Shuffle Function
- Reduce Function
Let us discuss each function and its responsibilities.
1. Map Function
This is the first step of the MapReduce Algorithm. It takes the data sets and distributes it into smaller sub-tasks. This is further done in two steps, splitting, and mapping. Splitting takes the input dataset and divides the data set while mapping takes those subsets of data and performs the required action. The output of this function is a key-value pair.
2. Shuffle Function
This is also known as combine function and includes merging and sorting. Merging combines all key-value pairs. All of these will have the same keys. Sorting takes the input from the merging step and sorts all the key-value pairs by making use of the keys. This step will also return to key-value pairs. The output will be sorted.
3. Reduce Function
This is the last step of this algorithm. It takes the key-value pairs from the shuffle and reduces the operation.
How Does MapReduce Algorithms Make Working Easy?
The relational database systems have a centralized server which helps in storing and processing the data. These were usually centralized systems. When multiple files come into the picture the processing is tedious and creates a bottleneck while processing multiple files. MapReduce maps the set of data and converts the data set where all data is divided into tuples and the reduce task will take the output from this step and combine these data tuples into the smaller sets. It works in different phases and creates key-value pairs that can be distributed over different systems.
What Can You Do With MapReduce Algorithms?
MapReduce can be used with a variety of applications. It can be used for distributed pattern-based searching, distributed sorting, weblink graph reversal, web access log stats. It can also help in creating and working on multiple clusters, desktop grids, volunteer computing environments. One can also create dynamic cloud environments, mobile environments and also high-performance computing environments. Google made use of MapReduce which regenerates Google Index of the World Wide Web. By using it the old ad hoc programs are updated and they have run different kinds of analysis. It also integrated the live search results without rebuilding the complete index. All the inputs and outputs are stored in the distributed file system. The transient data is stored on a local disk.
Working with MapReduce Algorithm
To work with MapReduce Algorithm, you must know the complete process of how it works. The data which is ingested goes through the following steps:
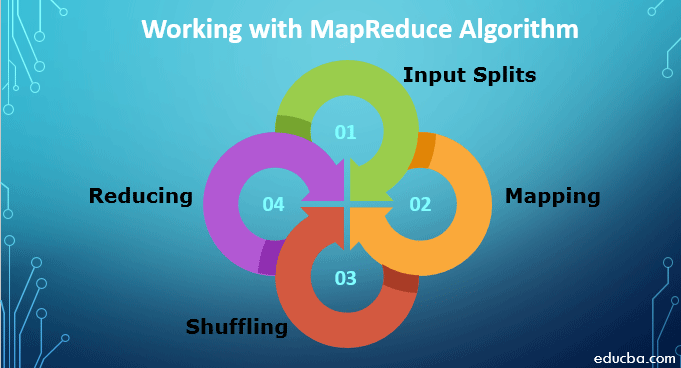
1. Input Splits: Any input data which comes to MapReduce job is divided into equal pieces known as input splits. It is a chunk of input which can be consumed by any of the mappers.
2. Mapping: Once the data is split into chunks it goes through the phase of mapping in the map-reduce program. This split data is passed to mapping function which produces different output values.
3. Shuffling: Once the mapping is done, the data is sent to this phase. Its job is to amalgamate the required records from the previous phase.
4. Reducing: In this phase, the output from the shuffling phase is aggregated. In this phase, all values are shuffled and brought together by aggregation so that it returns a single output value. It creates a summary of the complete data set.
Advantages
The applications that use MapReduce have the below advantages:
- They have been provided with convergence and good generalization performance.
- Data can be handled by making use of data-intensive applications.
- It provides high scalability.
- Counting any occurrences of every word is easy and has a massive document collection.
- A generic tool can be used to search tool in many data analysis.
- It offers load balancing time in large clusters.
- It also helps in the process of extracting contexts of user location, situations, etc.
- It can access large samples of respondents quickly.
Why Should We Use MapReduce Algorithm?
MapReduce is an application that is used for the processing of huge datasets. These datasets can be processed in parallel. MapReduce can potentially create large data sets and a large number of nodes. These large data sets are stored on HDFS which makes the analysis of data easier. It can process any kind of data like structured, unstructured or semi-structured.
Why Do We Need the MapReduce Algorithm?
MapReduce is growing rapidly and helps in parallel computing. It helps in determining the price for products and helps in yielding the highest profits. It also helps in predicting and recommending analysis. It allows programmers to run models over different data sets and uses advanced statistical techniques and machine learning techniques that help in predicting data. It filters and sends out the data to different nodes within the cluster and functions as per the mapper and reducer function.
How this Technology will Help you in Career Growth?
Hadoop is among the most wanted jobs these days. It is accelerating the rate and the opportunity which is growing very fast in this field. There is going to be a boom in this area even more. The IT professionals who are working in Java have a plus point as they are the most sought-after people. Also, developers, data architects, data warehouse and BI professionals can take away huge amounts of salary by learning this technology.
Conclusion
MapReduce is the basic of the Hadoop framework. By learning this you will surely get to enter the data analytics market. You can learn it thoroughly and get to know how large sets of data are being processed and how this technology is bringing a change with processing and storing of data.
Recommended Articles
This is a guide to MapReduce Algorithms. Here we discuss the basic concept, understanding, working along with advantages and career growth. You can also go through our other Suggested Articles to learn more –

