Updated March 10, 2023
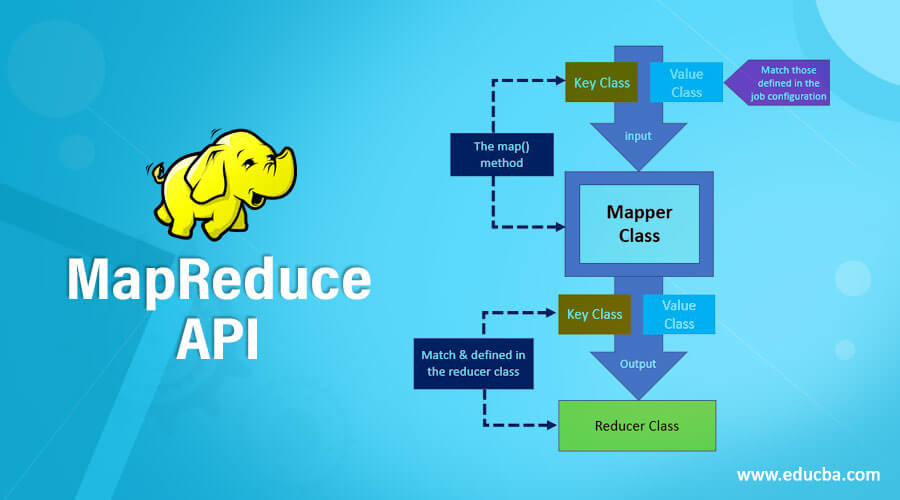
Introduction to MapReduce API
Hadoop can be developed in programming languages like Python and C++. MapReduce Hadoop is a software framework for ease in writing applications of software processing huge amounts of data. MapReduce is a framework which splits the chunk of data, sorts the map outputs and input to reduce tasks. A File-system stores the output and input of jobs. Re-execution of failed tasks, scheduling them, and monitoring them is the task of the framework. We will learn how to write a code in Hadoop in MapReduce and not involve Jython to translate code into Java. In this topic, we are going to learn about the MapReduce API.
MapReduce Class
Here are the following MapReduce Class
1. Map Phase
The map phase splits the input data into two parts. They are Keys and Values. Writable and comparable is the key in the processing stage where only in the processing stage, Value is writable. For example, let’s say a client gives input data to a Hadoop system; the task tracker is assigned tasks by the job tracker.
Mini reducer, which is commonly called a combiner, the reducer code places input as the combiner. Network bandwidth is high when a huge amount of data is required. Hash is the default partition used. The partition module plays a key role in Hadoop. More performance is given by reducing the pressure of the petitioner on the reducer.
2. Processing in Intermediate
In the intermediate phase, the map input gets into the sort and shuffle phase. Hadoop nodes do not have replications where all the intermediate data is getting stored in a local file system. Instead, Round-robin data is used by Hadoop to write to local disk, the intermediate data. There are other shuffles and sort factors to be considered to reach the condition of writing the data to local disks.
3. Reducer Phase
The reducer takes in the data input that is sorted and shuffled. All the input data is going to be combined, and similar key-value pairs are to be written to the hdfs system. For searching and mapping purposes, a reducer is not always necessary. Setting some properties for enabling to set the number of reducers for each task. During job processing, speculative execution plays a prominent role.
Types of methods in MapReduce API
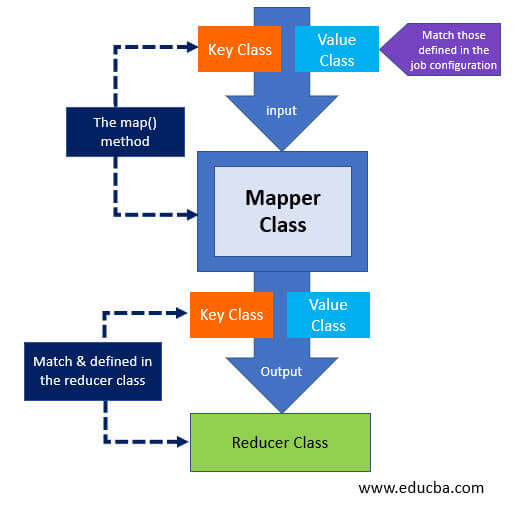
Let us see all the classes and methods are provided for MapReduce programming.
1. Mapper Class of MapReduce
Methods:
| void map
(VALUEIN value, KEYIN key, Context context) void cleanup void setup void run |
This method is called for every key-value pair in the input split and only at once.
This method is called at the end of the task and only at once. This method is called at the beginning of the task and only at once. This method overrides to control the Mapper execution. |
2. Reducer Class of MapReduce
Methods:
| void map
(Iterable <VALUEIN> values, KEYIN key, Context context) void cleanup void setup void run |
This method is called for each key and only once.
This method is called at the end of the task and only once. This method is called only at the beginning of the task and only at once. This method is used to control all the Reducer tasks. |
3. Job Class of MpReduce
Methods:
| void seReducerClass (Class<extends Reducer > class)void setNumReduceTasks (int tasks)void setMapperClass(Class< extends Mapper > class)void setMapOutputValueClass (Class < ? > class)void setMapKeyClass (Class < ? > class)void setJobName (name of String)void setJarByClass (Class < ? > class)JobPriority getPriority()String getJobName() String getJobFile() Job getInstance Job getInstance Job getInstance() long getFinishTime() Counters getCounters() |
This method is used for setting the Reducer for jobs.
This method is used for setting the number of Reducers for jobs. This method is used to set the job of the Mapper. This method is used for mapper output data to set the value class. This method is used for mapper output data to set the key class. The user-specified job name is to be set by using this method. Providing the class name with the extension .class, this method is used to set the jar. This method is used to get the job function with a schedule. The user-specified job name is obtained by using this method. The path of the submitted configuration of the job is obtained by using this method. Generates a new Job without a cluster and with provided job name and configuration. Generates a new Job without a cluster and with provided job name and configuration. New Job with no cluster. Finish time of Job. Counters of the job. |
Understanding how to submit a job with an example:

Conclusion
Imagine you have lots of documents, which is huge data. And you need to count the number of occurrences of each word throughout the documents. It might seem like an arbitrary task, but the basic idea is that let’s say you have a lot of web pages, and you want to make them available for search queries. Aggregation of data is done by the reducer, and it consists of all the keys and combines them all for similar key-value pairs, which is basically the Hadoop shuffling process.
Recommended Articles
This is a guide to MapReduce API. Here we discuss the MapReduce Class along with the Types of methods in MapReduce API. You may also have a look at the following articles to learn more –

