Updated March 6, 2023

Definition of MongoDB Aggregation
MongoDB Aggregation uses an aggregate() method to perform the aggregation operations. Basically, this aggregation operation practices data records and provides calculated results. The aggregation operations assemble values from various documents together and are able to execute a range of operations, such as average, sum, maximum, minimum, etc., on the assembled data to provide only a result. A corresponding of MongoDB Aggregation in SQL is count(*) and with the group by. MongoDB Aggregation is identical to the aggregate function provided in SQL.
MongoDB supports three techniques to execute aggregation operations:
✔ Single-purpose aggregation
✔ Aggregation pipeline
✔ Map-reduce function
Hence, aggregations are applied to a structure of query operations to the documents in a collection, decreasing and changing them as well.
Syntax:
Let us view the general syntax of the MongoDB aggregate() method written as follows:
Db.NAME_OF_COLLECTION.aggregate(AGGREGATE_OPERATION);
As MongoDB Aggregation consists of three ways so:
Aggregation Pipeline
Since MongoDB’s aggregation framework has been modeled on the idea of data processing pipelines, the documents insert a multi-stage pipeline that changes the documents into an aggregated outcome.
This can be illustrated using an example as follows:
Db.products.aggregate([
{$match: {status: “X”}},
{$group: {_id: “$pro_id”, total: {$sum: “$amount”}}}
])
Let us explain the above example in detail:
First Stage: In this stage, the $match stage will filter the documents by the field status and then will pass it to the succeeding stage those documents which hold status field equal to “X.”
Second Stage: In this stage, the $group stage will group the documents by the field pro_id for computing the totality of the amount for every distinct pro_id.
The simplest pipeline stages support filters that execute queries and document transformations that alter the form of the resultant document. While other pipeline operations support tools to group and sort documents by particular field or many, as well as other tools to aggregate the contents of arrays consisting of arrays of documents. In total, the pipeline stages may use operators for some tasks, such as concatenating a string or calculate the average.
Thus, the pipeline delivers resourceful data aggregation by means of built-in operations inside MongoDB and can be considered as a preferred technique for data aggregation applied in MongoDB. This aggregation pipeline can also execute on a sharded collection. It has an inner optimization phase.
Single Purpose Aggregation Operations
For aggregation, MongoDB also offers:
db.collection.distinct(), db.collection.estimatedDocumentCount() and db.collection.count().
These all operations will aggregate documents from an individual collection. However, these operations deliver basic access to communal aggregation processes, but there is the absence of flexibility and abilities of an aggregation pipeline.
Map-Reduce
Basically, an aggregation pipeline offers better usability and performance than a map-reduce operation in MongoDB.
This map-reduce operation may be rewritten by means of aggregation pipeline operators like $merge, $group, and so on. It needs custom functionality so MongoDB supports the $function and $accumulator aggregation operators in JavaScript beginning in version 4.4.
To view examples of aggregation pipeline alternatives for map-reduce operations, we need to learn advanced Map-Reduce aggregation pipeline and its examples further.
How does Aggregation work in MongoDB?
There is no better method than MongoDB Aggregations when we need to collect the metrics from MongoDB for any graphical illustration or maybe other operations. Aggregation in MongoDB is responsible for processing the data, which results in the calculated outputs, generally by assembling the data from several documents and then executes in various ways on those assembled data in order to yield one collective result. It practices documents and then yield computed outputs and thus execute a range of operations on the assembled data to return only one result.
Aggregation in MongoDB was progressed when limitations were viewed because of having millions of embedded documents, taking much time in processing, and server’s random memory which may terminate the operations.
This MongoDB Aggregation uses the Pipeline concept in the UNIX command, where the pipeline defines the possibility to perform an operation on few inputs and apply the output resulted as the input for the succeeding command, and it follows the same. MongoDB supports this idea in the aggregation framework.
Here, the operators come in three ranges such as stages, expressions, and accumulators.
There is a group of possible stages and every of those is considered as a group of documents as an input and generates a resulting group of documents (otherwise, the last JSON document at the completion of the pipeline. This will then, in turn, be implemented for the succeeding stage and likewise. Some possible stages determined in the aggregation framework are as follows:
1. $match: It is a filtering operation and therefore this can decrease the number of documents that are given as input to the succeeding stage.
2. $project: It is applied to choose few particular fields from a collection.
3. $group: It performs the concrete aggregation that we are discussing overhead.
4. $sort: It helps to sort the documents.
5. $limit: It limits the sum of documents to look at, provided by the specific number beginning from the existing positions.
6. $skip: It helps to make skipping possible forwardly in the list of documents for a provided sum of documents.
7. $unwind: It is operated to unwind documents which are using arrays. While applying an array, the data element is a form of pre-joined and then this operation will be uncompleted with this to include distinct documents another time. Hence, with the help of this stage, we can increase the sum of documents for the succeeding stage.
Example
Suppose we have data in the collection as follows where we have used ‘test’ database and related collection name is ‘books’:
show dbs
use test
show collections
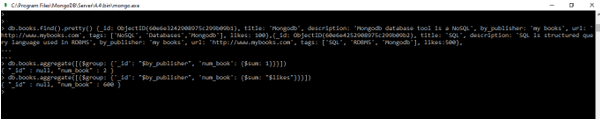
Db.books.find().pretty()
{
_id: ObjectID(60e6e3242908975c299b09b1),
title: ‘Overview of MongoDB’,
description: ‘MongoDB database tool is a No SQL database.’,
by_publisher: ‘my books’,
url: ‘http://www.mybooks.com’,
tags: [‘NoSQL’, ‘Databases’, ‘MongoDB’],
likes: 100
},
{
_id: ObjectID("60e6e4252908975c299b09b2),
title: ‘SQL’,
description: ‘SQL is structured query language used in RDBMS.’,
by_publisher: ‘my books’,
url: ‘http://www.mybooks.com’,
tags: [‘SQL’, ‘RDBMS’, ‘MongoDB’],
likes: 500
},
Output:

The _id: ObjectID(), is distinct for every data we insert into the collection using db.collection_name.insert({writeConcern: <doc>, ordered: <boolean>}) syntax. After we execute this command, it will return WriteResult object hence, we will get the ObjectID by MongoDB _id field creation and verified for further operations.
Using the collection details, to view the list defining how many books are written by every publisher and also the sum of all likes for both books, we will apply the syntax of the aggregate() method as follows:

Conclusion
MongoDB Aggregations function as a pipeline or, say, as a list of filters/operators implemented to the data. Here, we may pipe a collection into the top and change it by a sequence of operations, ultimately popping an outcome out the bottom.
Aggregation framework is introduced, which practices assembling of documents to enhance the process of scan that manipulates documents in various stages, processing accordingly with the given criteria or operations to perform the equivalent results.
Recommended Articles
This is a guide to MongoDB Triggers. Here we discuss the definition, syntax, How triggers work in Mongodb? Examples and code implementation. You may also have a look at the following articles to learn more –
