Updated February 18, 2023
Definition of NLTK Sentiment Analysis
NLTK sentiment analysis can assist us in figuring out how much positive and negative involvement there is on a given issue. Likewise, we may get insights from our audience by analyzing bodies of text like product reviews, comments, and tweets. The NLTK library offers several tools for manipulating and analyzing linguistic data. Text classifiers are among its advanced characteristics, which can be used for various classifications, including sentiment analysis.
Introduction to NLTK Sentiment Analysis
- Sentiment analysis is the process of categorizing numerous samples of linked text into various categories using algorithms. We may use these techniques to extract insights from linguistic data with NLTK’s sophisticated built-in machine learning operations.
- Unstructured data makes up a major portion of today’s data, necessitating processing to extract insights. For example, newspaper articles, social media posts, and search histories are all instances of unstructured data.
- NLP is the process of studying natural language and making sense of it. Sentiment analysis is a frequent NLP task that entails categorizing texts or sections of texts into one of several pre-defined sentiments.
How to Use NLTK Sentiment Analysis?
- Sentiment analysis is a sort of data mining that uses NLP, computational linguistics, and text analysis to extract and evaluate subjective data from the Web, primarily social media and other related sources.
- To study the public’s feelings or emotions toward specific things, individuals, or ideas and reveal the information’s contextual polarity.
- We will utilize Python’s NLTK, a popular NLP module, to analyze textual data. When it comes to sentiment analysis, there are primarily two methods.
- Lexicon-based – It will count the amount of negative and positive terms in a given text; the greater the count, the more positive the text’s attitude.
- Develop a classification model trained using a machine learning approach using a pre-labeled negative and neutral data dataset.
- One of the most crucial jobs in text mining is text classification. It’s a method that’s been carefully monitored.
- Identifying a text’s category or class, such as a blog, a book, a web page, news stories, or tweets.
- Spam detection, task categorization in CRM systems, categorizing website content for a search engine, sentiments of consumer feedback, and so on are some of the applications it has in today’s computer world.
- To use NLTK sentiment analysis, we must import our code’s numpy, pandas, matplotlib, and seaborn modules.
- The below example shows we need to import the below modules into our code.
Code:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
NLTK Sentiment Analysis Classifiers
- Sentiment analysis is the process of determining an author’s attitude toward a topic being written about.
- We will need to construct a training data set to train a model. It’s a supervised machine learning procedure that asks us to assign a “sentiment” to each dataset for training.
- Our model uses “positive” and “negative” attitudes in this course. Text may be classified into a range of sentiments using sentiment analysis.
- A model is a set of rules and equations that describe a system. It might be as basic as an algorithm that estimates a person’s weight based on height.
- We will create a sentiment analysis model that associates tweets with positive or negative sentiment. We will need to divide our data into two sections.
- The first part’s goal is to develop the model, while the second is to test the model’s performance.
- The modeling exercise will be completed using NLTK’s Naive Bayes classifier. The model requires a Python dictionary with words as keys and values.
- The below example shows the Naive Bayes classifiers as follows.
Code:
def get_tweets_for_model (list_token):
for py_token in list_token:
yield dict ([token, True] for token in py_token)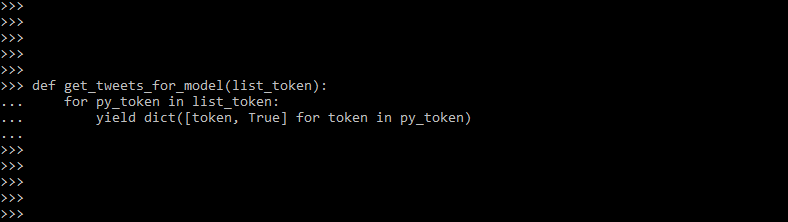
- In the above example, we first defined the get tweets model; in the get tweets model, we defined the list_token. Then we have used objects of py_token and list_token.
NLTK Sentiment Analysis Idea Approach
The below steps shows the NLTK sentiment idea analysis approach as follows.
1. Import the module
In this step, we import the module of pandas, NumPy, matplotlib, and seaborn by using the import keyword. The NumPy module is used for linear algebra equations. Panda module is used for document processing. Matplotlib module is used for better visualization. Seaborn module is also used for better visualization. The below example shows the import of the module as follows.
Code:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
2. Importing the data set
We can utilize the dataset “Sentiment Analysis of Movies, Reviews. A tab-separated file contains the data. We have used four columns that make up the data set. The below example shows loading data through the tsv file as follows.
py_sentiment = pd.read_csv ('train.tsv', sep='\t')
py_sentiment.head()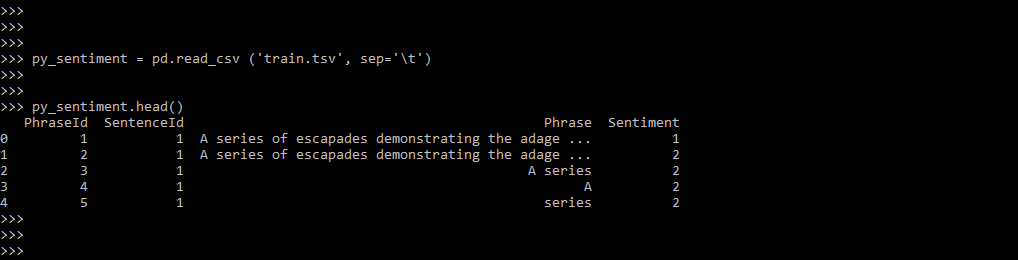
- In the above example, we can see that we have uploaded the data through the train.tsv file. We have used the object of the panda’s module to read the tsv file. We have created the alias of the pandas’ module as pd; we have used this alias name when loading data through the tsv file. Also, we are using the read_csv method to read the data from the tsv file. We have also used the separator to separate the value using a tab. The above example uses the four-column to define NLTK sentiment analysis.
- In this step, we check the info of the tsv file by using the info method. With the info method, we are using the object of py_sentiment. The below example shows the display info of the tsv file.
py_sentiment.info ()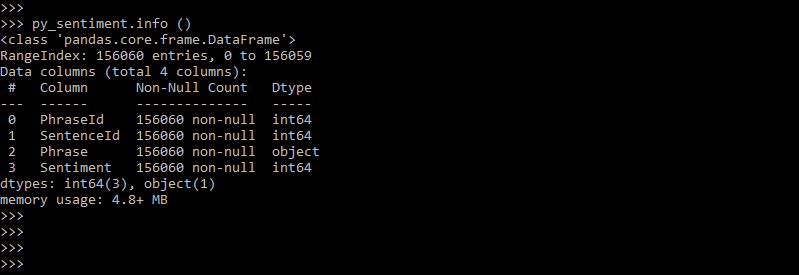
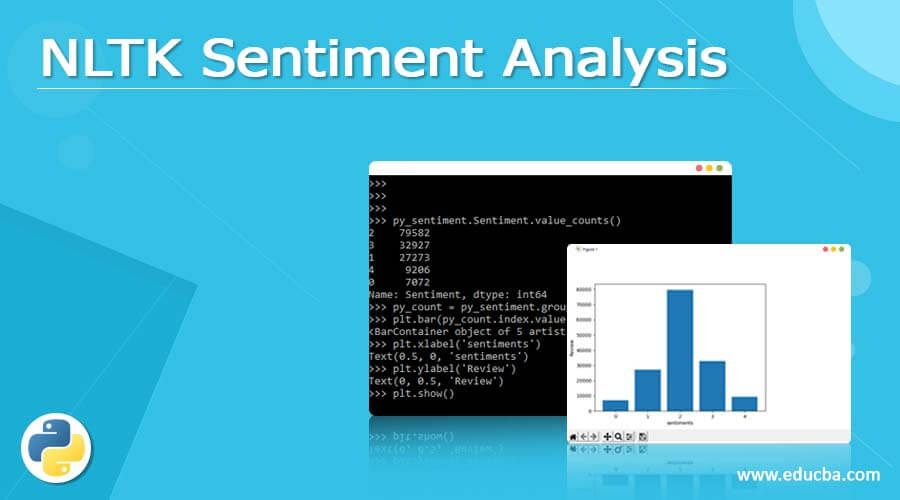
- Below examples shown to display the sentiment analysis are as follows. We are using the below code to check the analysis.
Code:
py_sentiment.Sentiment.value_counts()
py_count = py_sentiment.groupby('Sentiment').count()
plt.bar (py_count.index.values, py_count['Phrase'])
plt.xlabel('sentiments')
plt.ylabel('Review')
plt.show()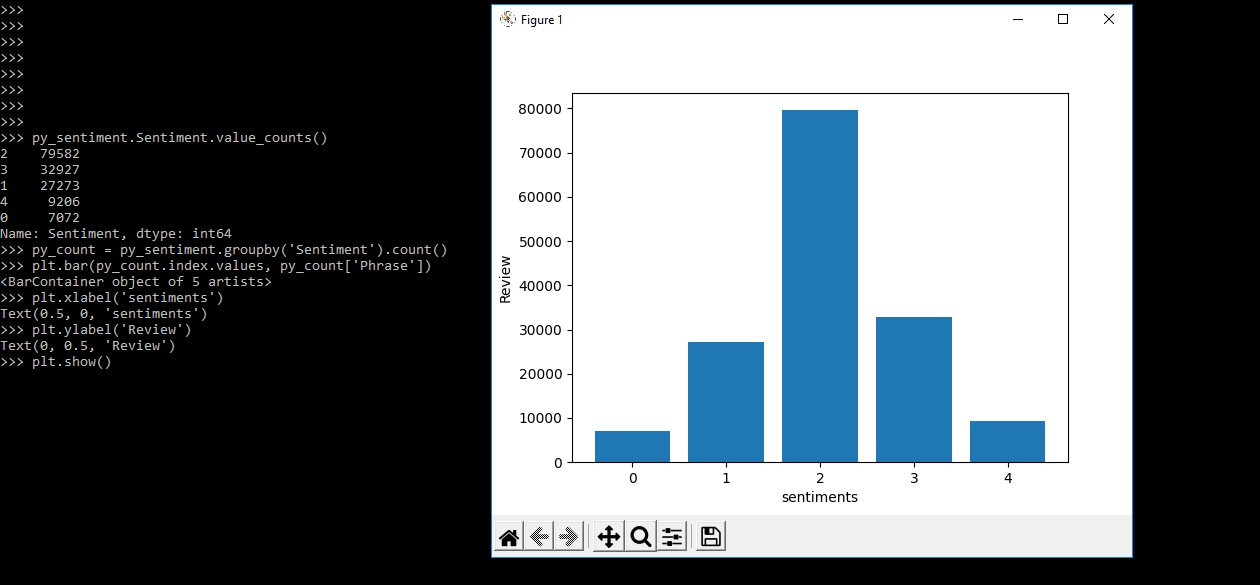
Conclusion
Sentiment analysis is the process of categorizing numerous samples of linked text into various categories using algorithms. These techniques extract insights from linguistic data with NLTK’s sophisticated built-in machine learning operations. For example, NLTK sentiment analysis can assist us in figuring out how much positive and negative involvement there is on a given issue.
Recommended Articles
This is a guide to NLTK Sentiment Analysis. Here we also discuss the definition and how to use NLTK Sentiment Analysis, classifiers, and idea approaches. You may also have a look at the following articles to learn more –

