Updated March 29, 2023

Definition of NLTK Stemming
Nltk stemming is the process of morphologically varying a root/base word is known as stemming. Algorithms of stemmers and stemming are two terms used to describe stemming programs. Tokens, tokened, and tokening are all reduced to the base word token using a stemming algorithm. The stemming algorithm PorterStemmer is included in the Natural Language Tool Kit. Martin Porter, a linguist, is responsible for the NLTK’s PorterStemmer.
What is NLTK Stemming?
Words were stripped of their morphological affixes, leaving simply the word stem. Due to irregular words’ complex morphological rules, part-of-speech, and sense ambiguity, this is a challenging topic to solve.
- In the discipline of NLP, stemming is Text Normalization or sometimes termed Word Normalization procedures. When two words with distinct stems are stemmed to the same root, overstemming occurs.
- With NLTK, stemming generates a word’s original root form. In linguistic stemming is an aspect of the process. The morphological root and the stemmed word’s root must be equal. The term “stemmer” refers to stemming algorithms and technologies.
NLTK Stemming Applications
- Stemming is an NLP approach that reduces which allowing text, words, and documents to be preprocessed for text normalization.
- Inflection, according to Wikipedia, is the modification of a word to transmit a variety of grammatical characteristics.
- As a result, we use stemming to break down words into their simplest form or valid word in the language.
- Stemming is used in a variety of applications, including information retrieval and word analysis. A Google searches for the terms’ prediction and predicted, for instance, yields similar results.
- As previously stated, a single term in the English language contains multiple variations. When creating NLP or machine learning models, the presence of these deviations is data redundancy.
- It is critical to normalize text by reducing duplication and stemming words to their basic form in order to develop a viable model.
- Information retrieval systems, such as search engines, use stemming. The below steps shows the application of stemming are as follows.
1) Install nltk by using pip command – The first step is to install nltk by using the pip command. Below examples shown to install nltk by using the pip command are as follows.
pip install nltk
2) After installing the pip command, we are login into the python shell by using the python command to execute the code are as follows.
python
3) After login into the python shell in this step we are importing the word_tokenize and PorterStemmer module by using nltk. tokenize and nltk.stem library. The below example shows import the word_tokenize and PorterStemmer modules are as follows.
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
4) Below example shows stemming word implementation by using nltk are as follows. To implement this example first we are importing the porterstemmer module by using nltk. stem package and also importing the word_tokenize module by using nltk.tokenize package. After importing the package we are creating the object of porterstemmer function. Then we have to define the word, after defining the word in the next line we have printed the same by using for loop.
Code:
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
py_stem = PorterStemmer()
py_words = ["token", "tokens", "tokener", "tokening"]
for word in py_words :
print (word, " : ", py_stem.stem (word))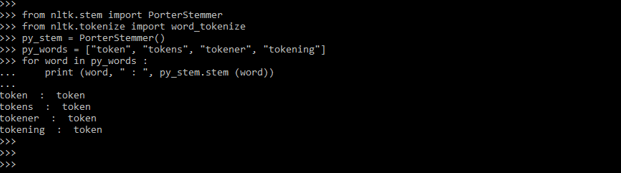
5) Below example shows stemming the word by using sentences are as follows. To implement this example first we are importing the porterstemmer module by using nltk.stem package and also importing the word_tokenize module by using nltk.tokenize package. We are using sentences for stemming the words. Same as word implementation we are creating the object of PorterStemmer function.
Code:
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
py_stem = PorterStemmer()
py_sen = "Tokeners token with tokening lang."
py_word = word_tokenize (py_sen)
for word in py_word:
print (word, " : ", py_stem.stem(word))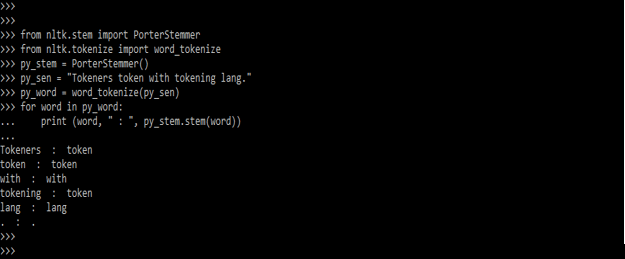
NLTK Stemming Errors
- In NLP, stemming is a technique for normalizing words. It is a method of converting a group of sentence words into a sequence in order to reduce the time it takes to look up the information.
- The words that have the same meaning but differ due to context or sentence are normalized using this method.
- In other words, there is a single root term with several variations. Overstemming and understemming are the two most common stemming mistakes. When two words with the same root but distinct stems are stemmed to the same root, under-stemming occurs.
- The below example shows nltk stemming errors are as follows. In the following words, we are stemming the same word three times.
Code:
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
py_stem = PorterStemmer ()
py_words = ["token", "token", "token", "tokening"]
for word in py_words :
print (word, " : ", py_stem.stem (word))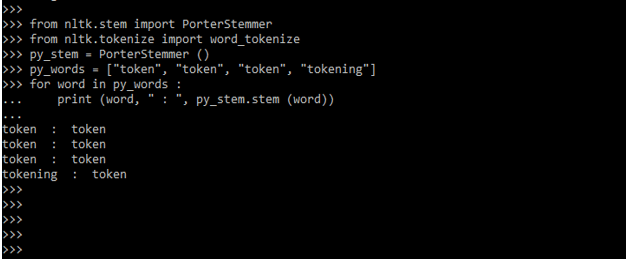
NLTK Stemming Grab
- Stemming is a standardization technique. Aside from when tense is involved, many varieties of words will contain the same meaning. The purpose of stemming is to make the lookup process faster and to standardize sentences.
- Let’s consider the two-sentence i.e. I am taking the ride of horse and I am riding the horse. The situation is identical in the horse. I used to be like that. In both cases, the ing suggests a definite past-tense, so is it really important to distinguish between ride and riding when attempting to understand this past-tense activity.
- Below examples shown to grab stemmer are as follows.
Code:
from nltk.stem import PorterStemmer
from nltk.tokenize import sent_tokenize, word_tokenize
py_stem = PorterStemmer()
py_word = ["token", "tokener", "tokening", "tokened", "tokenly"]
for word in py_word:
print(py_stem.stem(word))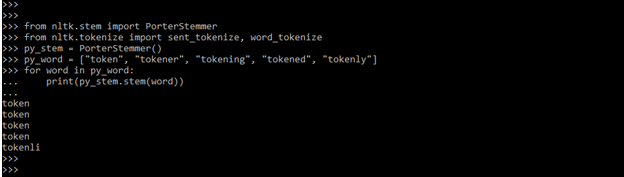
- In the below example, we are using difficult sentences instead of words.
Code:
from nltk.stem import PorterStemmer
from nltk.tokenize import sent_tokenize, word_tokenize
py_stem = PorterStemmer()
py_text = "Nltk stemming in python"
py_words = word_tokenize(py_text)
for word in py_words:
print(py_stem.stem(word))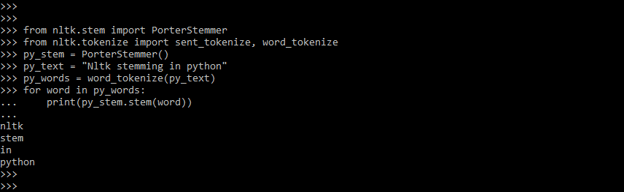
Conclusion
Stemming is an NLP approach that reduces which allowing text, words, and documents to be preprocessed for text normalization. Nltk stemming is the process of morphologically varying a root/base word is known as stemming. Algorithms of stemmers and stemming are two terms used to describe stemming programs.
Recommended Articles
This is a guide to NLTK Stemming. Here we discuss the Definition, What is NLTK Stemming, applications, NLTK Stemming Grab, examples with implementation. You may also have a look at the following articles to learn more –

