Updated March 29, 2023

Introduction to NLTK word_tokenize
Nltk word_tokenize is used to extract tokens from a string of characters using the word tokenize method. It actually returns a single word’s syllables. Single or double syllables can be found in a single word. Return a tokenized version of the text using NLTK’s suggested wording. It is the process of breaking down a big amount of text into smaller pieces called tokens. Word_tokenize function is important in NLTK.
What is NLTK word_tokenize?
- Nltk word_ tokenize is extremely important for pattern recognition and is used as a starting point for stemming and lemmatization. Tokenization can also be used to replace sensitive data pieces with non-sensitive ones.
- Text classification, intelligent chatbots, and other applications require natural language processing. To attain the above-mentioned goal, it is critical to comprehend the text’s pattern.
- To separate statements into words, we utilize the method word tokenize. For better text interpretation in machine learning applications, the result of word tokenization can be translated to Data Frame. It can also be used as starting point for text cleaning processes such as stemming.
How to use NLTK word_tokenize?
- To be trained and provide a prediction, machine learning models require numerical data. The conversion of text to numeric data requires word tokenization.
- The NLTK library’s word tokenize module is included. Two sentences are used to start the variable “text.”
- The output is printed after passing the text variable into the word tokenize module. The result shows how the module breaks the word by using punctuation.
- Sent tokenize is a sub-module for this. To determine the ratio, we will need both the NLTK sentence and word tokenizers.
- Tokenization is the process of breaking down a big amount of text into smaller pieces known as tokens in natural language processing.
- Text classification, intelligent chatbots, and other applications require natural language processing.
- The NLTK tokenize sentence module, which is made up of sub-modules, is an important part of the Natural Language Toolkit.
- To separate a statement into words, we utilize the word tokenize method. For enhanced text interpretation in machine learning applications, the output of the word tokenizer in NLTK can be transformed into a Data Frame.
- Sent tokenize is a sub-module that can be used for the aforementioned. The Python NLTK sentence tokenizer is a key component for machine learning.
- To use words nltk word_tokenize we need to follow the below steps are as follows.
1) Install nltk by using pip command – The first step is to install nltk by using the pip command. Below examples shown to install nltk by using the pip command are as follows. In the below image, we can see that we have already installed nltk so it will show requirements already satisfied.
pip install nltk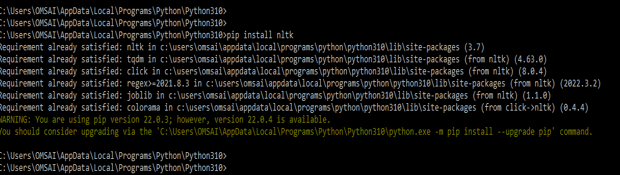
2) After installing the pip command, we are login into the python shell by using the python command to execute the code are as follows.
python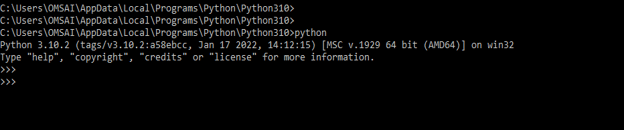
3) After login into the python shell in this step we are importing the word_tokenize module by using nltk library. The below example shows the import of the word_tokenize module is as follows.
from nltk import word_tokenize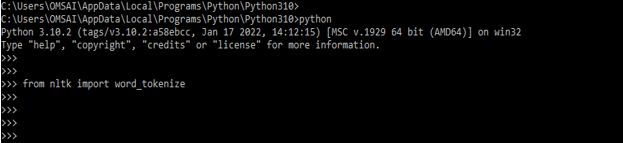
4) After importing the word_tokenize module in this step we are creating the reference variable of word_tokenize class and providing the user input. In the below example we are creating the word_tokenize class of reference variable and providing input variable are as follows.
py_word = "nltk word_tokenize"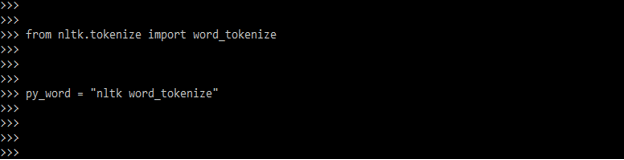
5) After providing input from the user in this step we are using the word_tokenize module to print the output we are using the print method. The below example shows the user word_tokenize module to print the output.
print (word_tokenize (py_word))
NLTK word_tokenize function
• In the word_tokenize function sent tokenize is a sub-module of tokenize nltk. Word tokenization function is most important in the nltk tokenize module.
• To determine the ratio, we will need the function of word tokenization. Output is useful for machine learning. Tokens refer to each component.
• To tokenize a word, we are using use the word tokenize function. It makes use of the nltk module instance.
• Word_tokenize function separates a text into a list of tokens in NLP. Tokens are useful for identifying valuable patterns and replacing sensitive data components.
• The advantages of word tokenization with NLTK are White Space Tokenization and Dictionary Based Tokenization. The text normalization procedure includes all types of word tokenization. The accuracy of the language comprehension algorithms is improved by normalizing lemmatization.
• Word_tokenize function will easily remove stop words from the corpora prior to tokenization. Words are broken down into sub-words to help us grasp the content better.
• With NLTK word_tokenize function is quicker and needs less coding. Dictionary-based and Rule-based Tokenization, in addition to White Space Tokenization, are simple to implement.
• For tokenizing compound words like “in spite of,” NLTK offers a Multi-Word Expression Tokenizer. RegexpTokenizer in NLTK tokenizes phrases using regular expressions.
• Below example that shows the function of nltk word_tokenize is as follows. In the below example, we are first importing the module of word_tokenize by using nltk.tokenize package. Then we are providing the input from the user. After providing input in the next line we are calling the word_tokenize function to print the output using word_tokenize function.
Code:
from nltk.tokenize import word_tokenize
py_word1 = "python nltk word_tokenize function"
print (word_tokenize(py_word1))
Example
- The below example shows the nltk word_tokenize function are as follows. In the word_tokenize function, special characters like commas are also treated as tokens. In the below example first line we are importing the word_tokenize module. We have used “,” in input, so we can see that it will be treated as a separate token.
Code:
from nltk.tokenize import word_tokenize
py_wordtoken = "python nltk, word_tokenize, function"
print (word_tokenize(py_wordtoken))
- In the below example we are tokenizing the single word. We are using a single word to tokenize the same by using the word_tokenize function. In the below example, we have separated a single word by using commas, so the word_tokenize function will treat it as a separate token. It will separate a single word into multiple tokens because we have used commands in a single word.
Code:
from nltk.tokenize import word_tokenize
py_wordtoken = "python,nltk,word_tokenize,function"
print (word_tokenize(py_wordtoken))
Conclusion
Nltk word_ tokenize is extremely important for pattern recognition and are used as a starting point for stemming and lemmatization. Nltk word_tokenize is used to extract tokens from a string of characters using the word tokenize method. It actually returns a single word’s syllables.
Recommended Articles
This is a guide to NLTK word_tokenize. Here we discuss the Definition, What is NLTK word_tokenize, How to use NLTK word_tokenize, examples with implementation. You may also have a look at the following articles to learn more –

