Updated March 28, 2023

Introduction to Nutch Apache
Nutch Apache is a popular web crawler software that is used to segregate information from the web. It is used in the incorporation with other Apache tools like Hadoop to work on better data analysis. It is an open-source product that has a license from Apache Software. So the developer community has the license for a wide variety of tools in Apache to sort the data and analyze it. Along with other tools, Apache Hadoop also has the same features for storing, analyzing, collecting files from the web by using algorithms on web crawling. The brief installation, operating system, and features of Apache Nutch are explained in this article.
What is Nutch Apache?
Nutch Apache is used to segregate data from the web by using web crawling algorithms. It is an open-source tool and works on Apache Solr framework, which behaves as a repository for the information collected in Apache Nutch. Nutch is best for batch processing of higher-dimensional data, which can be integrated into smaller jobs. The Nutch also provides powerful plugins, with parsing to Apache Tika, Elasticsearch, and Apache Solr. Apache Nutch offers an intuitive, extensible, and stable interface for prevalent functions like Scoring, Indexing, HTML filtering, and parsing to make some customized implementations. The users can gain advantages by running simple commands in Apache Nutch to fetch data under URLs.
How to Installing Nutch apache?
The initial step is to build and download the plugin software and Nutch Apache.
- Using GitHub, clone the repository of the index plugin.
- Choose the preferred version from the index plugin
- Build the index plugin using the $ mvn package
- Then it executes multiple tests after downloading index plugins. So skip the tests, choose the mvn package – Dskip tests.
Install the Apache Nutch 1.15 versions and follow the given installation steps in the Apache Nutch manual.
Then extract the target file to the folder where the plugins are copied
Then work on the plugin index
- First, to configure the index plugin, build a file named plugin. Config.properties
- The config file should show the parameters which are mandatory to work on the data source of Google cloud search.
- The config file can comprise other parameters to manage the index plugin so that the plugin knows to push the information into the cloud search. The user can also config the index plugins by using API, batch *, and default ACL* to populate the metadata and structured data.
Apache Nutch configuration
Add the parameters in the conf/nutch.xml file. The plugin should include the text file, which should contain index-basic, index-google cloud search, and index-more. But the conf/nutch.xml provides standard value to this property, but it is up to the user to add manually the index- google – cloud search into it. Metatag names can also be given in the form of text. A comma separates the list, and its properties are mapped to the data source, which has a corresponding schema.
Then to configure the web crawl, add the following properties into the XML file conf\index-writers.XML.
Before starting the web crawl configuration, it should hold the data where the business wants to display the available criteria as a result of the search window.
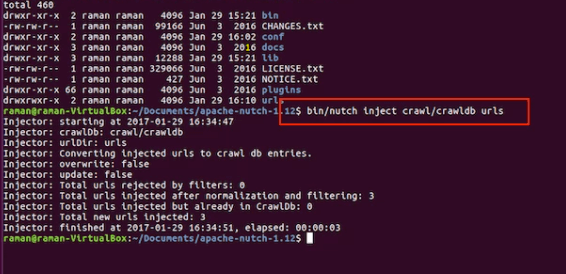
Initiate a URL where the Apache Nutch begins to crawl the content. This URL is defined as the start URL where the web crawling process reaches all the contents that need to be included in the crawl links. The start URL is mandatory for directory installation.
- To change the Nutch install directory from the working directory, give $cd ~/Nutch/apache-Nutch-x/
- Then build a directory to URL: $mkdir URL
- Create a seed file and list URL. Then go on with rules of URL to manage the crawl, which is fed in the index of Google Cloud Search. Only the URL mentioned here will follow the rules to crawl and index. If the URL doesn’t follow the crawl pattern, then the web crawler stops functioning.
- Then change to nutch directory from the current working directory.
- Then edit the config file to change the file to follow the rules of web crawl.
- $nano.conf/urlfilter
Provide the regular expression with – or + to follow the crawl patterns by URL, and sometimes the open end expressions are enabled by editing the crawl script. If the GCS.upload parameter is set to raw, the binary content is added to pass the command of the nutch index. The argument should pass the Nutch index to include binary content when the plugin is invoked. The .bin script of crawl doesn’t have any default arguments.
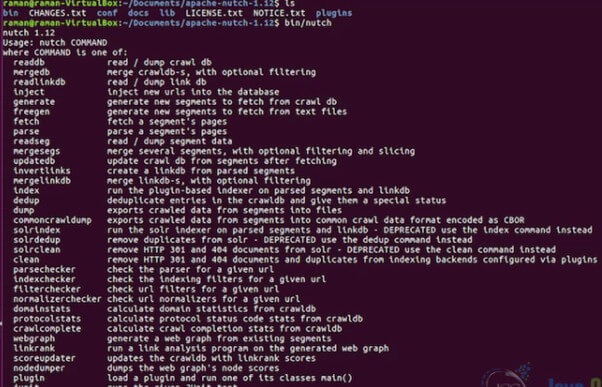
Nutch apache Operating System
The Nutch Apache has a flexible and effective operating system that is versatile. So after the installation of plugins, the index can be executed into the local mode from scripts to run the crawl job in the individual nutch commands. The required components are placed in the local directory to execute the Nutch, which is executed with a directory of apache-Nutch-1.15. The verbose logging files and output logs are saved in edit/log4j. Properties. It is highly scalable and has rich crawling options. It obeys the robots.txt rules provided in the configuration XML file. The executed Nutch holds 100 machines in the cluster, which is scalable and robust. The bias option is set to crawl on the important content first.
Examples of Nutch Apache
The crawl information knows the URL to fetch the data from the crawl database.
In the link database, the known links to URL is comprised of source link and anchor link to work on the web crawling content.
It works in an array of segments. The segment is composed of a finite URL which is calculated as a unit. The segments can be defined with subdirectories.
- The set of URL that needs to be fetched are given in crawl_generate
- The fetching status is given in crawl_fetch
- The retrieved raw content from every URL is placed in the content folder
- The URL with parsed text is located in parse_text
- The parsed metadata and out link is located in parse_data
Conclusion
Hence the working, installation, and properties of Nutch Apache are understood, and the user can configure the web crawling properties according to his content requirement and business preference.
Recommended Articles
This is a guide to Nutch Apache. Here we discuss the working, installation, and properties of Nutch Apache are understood, and the user can configure the web crawling properties. You may also have a look at the following articles to learn more –

