Updated February 14, 2023
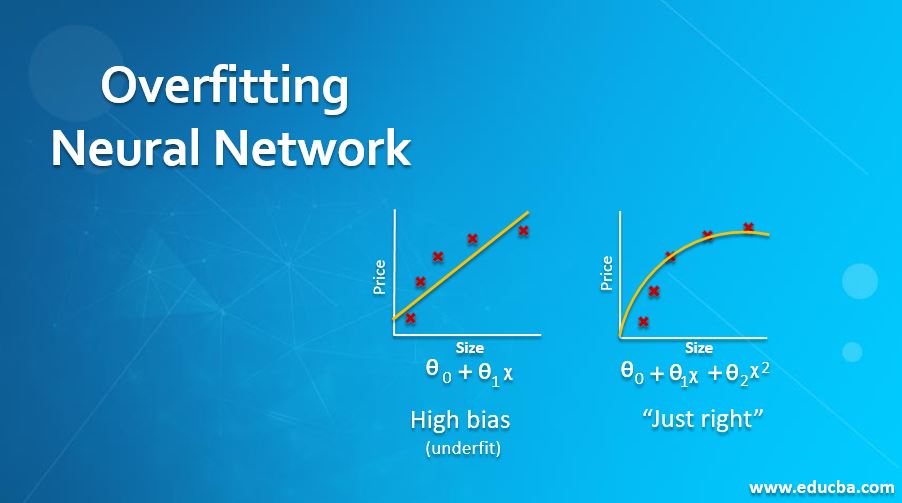
Introduction to Overfitting Neural Network
A neural network is a process of unfolding the user inputs into neurons in a structured neural network. It is achieved by training these neural nets to align their weights and biases according to the problem. Deep Neural nets consist of hidden layers of nodes between the input and output layers interconnected to each other. Training data is passed to successive layers and transformed as an output layer at the end. That output layer is considered as a resultant for the problem. So far deep neural nets generalize better to provide solutions for a vast variety of problems.
What is Overfitting in Deep Neural Network?
In mathematics and statistics, every problem has a functional form. Deep neural networks are basically trained with training dataset to fit the neural networks in alliance with the problem’s function form. Slowly after each epoch, the deep neural net generalizes over the problem. When it is finally ready, we test its accuracy using the test data set. An ideal deep neural net should produce similar results in both training and test datasets. If a deep neural net does not perform well with both training and test datasets, it’s underfitting whereas if the deep neural net performs very well with training dataset but fails with test dataset; it is called overfitting. While the former requires more training, the latter requires more attention as overfitting is a very common problem with deep neural nets.
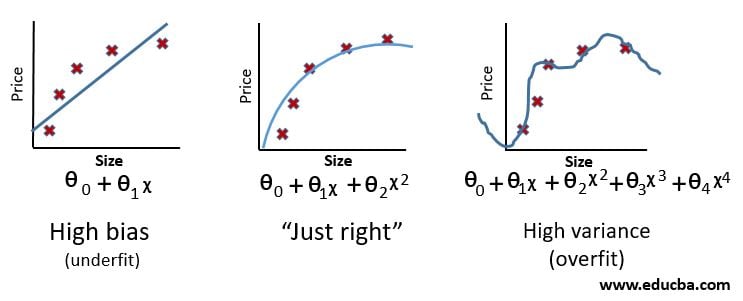
Overfitting occurs due to excessive training resulting in the model fitting exactly to the training set instead of generalizing over the problem. It is evident by now that overfitting degrades the accuracy of the deep neural networks, and we need to take every precaution to prevent it while training the nets. Extensive research over the past few years has helped us with the following techniques to prevent overfitting.
Techniques to avoid Overfitting Neural Network
Following are the precautionary measures carried out to prevent overfitting,
1. Data Management
In addition to training and test datasets, we should also segregate the part of the training dataset into the validation dataset. Validation datasets are primarily used to choose a better model for the problem and also acts as a pre-test dataset. This allows the deep neural network to generalize better.
2. Data Augmentation
Another common process is to add more training data to the model. Given limited datasets, overfitting can be prevented by Data augmentation. It is a process of creating more versions of the existing dataset by adding pan, zoom, vertical flip, horizontal flip, padding, rotating, etc. This very effective way has become an industry-standard while feeding the training dataset to the neural network model. The percentage of augmentation can be determined before training the model with a small subset of data.
Using batch normalization with backpropagation – Scale the data by normalizing -> Improves the learning rate & reduces the dependencies on data.
3. Batch Normalization
Normalization is the process of introducing mean and standard deviation of data in order to enable better generalization. Batch normalization adds a layer on top of the regular input layer to apply normalization to every node of the neural network. Batch normalization has additional benefits like improved gradient flow, higher learning rates, etc. Also, the batch normalization can be ignored during backpropagation, making it faster to train the model.
4. Dropouts
Dropouts are another recent but fast adapting technique to tackle overfitting. It was introduced by the Father of modern neural networks, Geoffrey Hinton, himself. It is a process of randomly dropping the activations from the last layer of every level, before passing the activation function to the next layer. It was proven to reduce overfitting and helping the model to generalize better and faster.
5. Weight Decay
Although weight decay is similar to dropouts, they are totally different in implementation. The primary constructs of neural networks are weights and biases between different neurons. Weight decay engages selective weights that reduce while moving towards the output layers. As the weight decays, overfitting reduces enabling generalization.
6. Early Stopping
Early stopping prevents overfitting by preventing the model training for the entire set whenever validation loss rises, which is a clear indication of overfitting. Although it is a small tweak, it helps a lot while training with large datasets.
7. L1/L2 Regularization
L1 is a Lasso Regression, whereas L2 is Ridge regression. These techniques introduce a penalty system within the model to help keep features in check. These are very helpful in training large models with a huge number of features. There are lots of research happening to the date in regularization that is custom made for CNN, RNN, LSTM, etc.
8. Recursive Feature Elimination
It is another helpful method while training a feature-rich model. We develop a system to calculate the importance of every feature after training the dataset, and the least important feature gets eliminated from passing on to the next layer. One can assume recursive feature elimination as a sophisticated dropout method for large models.
9. Test Time Augmentation
Test time augmentation is like data augmentation but happens at the end of the training. The mean of final activations obtained by training the model with different versions of the training data is the output of the model. Although TTA provides just 1 or 2 per cent improvement inaccuracy, it’s as important as other techniques to prevent overfitting.
Conclusion
Each of the techniques discussed above is under active research in addition to lots of other sophisticated techniques. These practices provide cutting-edge results with the deep learning models. We need to remember that overfitting is just one of the many issues that a deep neural network may run in to. Hence while selecting one or many of the measures provided here, we need to make sure it complies with other hyperparameters and features of the network providing a collective advantage while training the deep neural networks. Most of these techniques have already been implemented in leading deep learning/machine learning libraries so that developers can quickly make use of them instead of implementing from scratch.
Recommended Articles
This is a guide to Overfitting Neural Network. Here we discuss the Introduction to Overfitting Neural Network and its Techniques like Data Management, Data Augmentation, Batch Normalization, etc. You can also go through our suggested articles to learn more –

