Updated April 3, 2023
Introduction to Pandas Column
Pandas column is part of a two-dimensional data structure commonly called a data-frame in python and comprises the data arranged in a tabular format. Data present in the tabular format is either aligned with column or row in a dict like series of the object in a container. It is a data structure which makes use of Date Frame’s column as an attribute and returns the label with name from the Data frame. Pandas column extensively supports any kind of arithmetic operations and the data structure present is heterogeneous in nature.
Syntax
The syntax flow for the Pandas column in Data Frame is described as follows :
DataFrame.columnswhere the Data Frame points to the column as an attribute in the entire data structure returning the column names with column labels of the given table used for the elicitation of the entire data structure.
- There is no need to pass any argument or parameter explicitly to the function.
- The return type for the Pandas column is the column name with the column label.
How does the column work in Pandas?
As mentioned, the Pandas column is part of a two-dimensional data structure in which one of the attributes is a column, so the Pandas column revolves around all the functionality related to the column. Working flow is in a way where the Pandas column will involve operations like Selecting, deleting, adding, and renaming. Let’s check each scenario :
- In case the user wants to select a column, then the columns will get accessible by calling the column name with the column label.
- In case the user wants to add a column in the table, then that operation can easily be attained using the Pandas column by declaring a new list of the column and then add that newly created list of columns to the existing Data Frame.
- In case a scenario arises where the user easily wants to delete a column from the table being created using the Pandas column, then in that case, it is very much needed to delete a column.
- Drop() method present in the Pandas Data Frame is used with columns’ cooperation to delete the column by dropping it with a column name or column label.
- Similarly, a column name can also be renamed if the user wants to rename a particular column in the table defined.
- Renaming a column name in the Pandas column also uses the dataframe column, which comprises homogenous data throughout any specific column, whichever is needed.
- One alternative way of renaming a single column is using the rename() function, possible for multiple columns, or by assigning a list of column names externally.
- Since the Pandas column is a part of the DataFrame column, which is considered a two-dimensional array, thus the dataframe is labeled with their respective axes, which signifies the actual demand and usage.
- There is no need to explicitly define any argument in the data frame data structure, especially for the Pandas column.
- The return type for using the Pandas column is column names with the label.
- The default range index for the Pandas column lies in the range of (0,1,2,….n) if, by default, no column is available.
Examples
Different examples are mentioned below:
Example #1
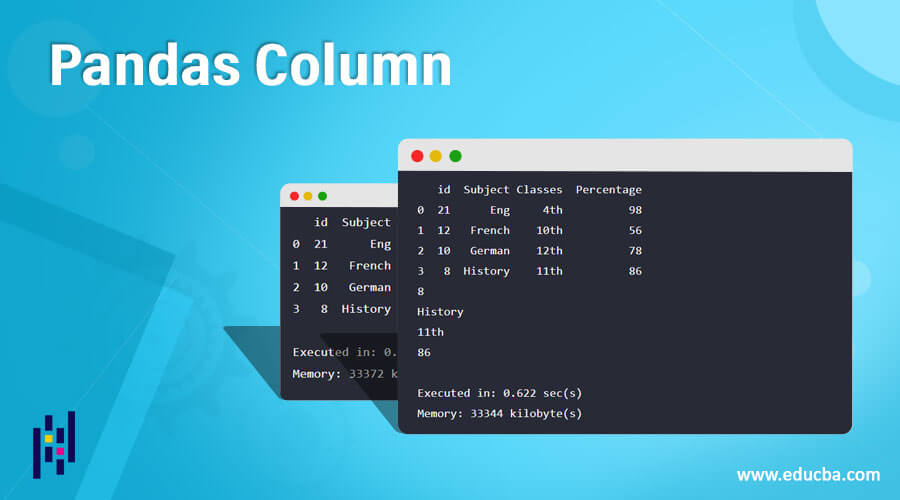
This program demonstrates the selection of columns in a table and access to the table column, whichever is required by calling the column name as shown in the output.
Code:
import pandas as pd
data_1 = {'id':[21, 12, 10, 8],
'Subject':['Eng', 'French', 'German', 'History'],
'Classes':['4th', '10th', '12th', '11th'],
'Percentage':[98, 56, 78, 86]}
d_frm = pd.DataFrame(data_1)
print(d_frm[['id', 'Subject', 'Classes', 'Percentage']])Output:
Example #2
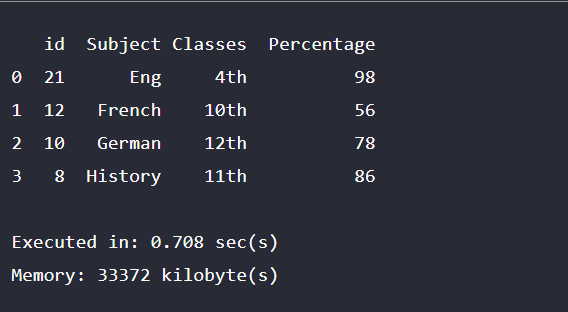
This program demonstrates the usage of the column by iterating over the required columns present in the table as shown in the output.
Code:
import pandas as pd
data_1 = {'id':[21, 12, 10, 8],
'Subject':['Eng', 'French', 'German', 'History'],
'Classes':['4th', '10th', '12th', '11th'],
'Percentage':[98, 56, 78, 86]}
d_frm = pd.DataFrame(data_1)
print(d_frm[['id', 'Subject', 'Classes', 'Percentage']])
columns = list(d_frm)
for l in columns:
print (d_frm[l][3])Output:
Example #3
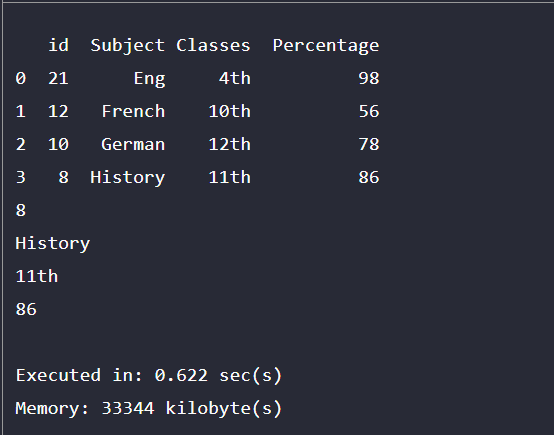
This program demonstrates the renaming function of a single column of a table using the dataframe of the Company hierarchy, which maintains the company hierarchy as shown in the output.
Code:
import pandas as pd
Company_Hierarchy = {
'CEO': ['Mark', 'Hency', 'lucigy',
'Zenny', 'Austin'],
'CTO': ['Henry', 'Tom', 'Jerry',
'Marie', 'Harry'],
'Director': ['Zaikh', 'Madona', 'Zuke',
'Molly', 'Jolly']
}
Cmp_hier = pd.DataFrame(Company_Hierarchy)
print(Cmp_hier)
Cmp_hier.rename(columns = {'CEO':'ceo'}, inplace = True)
print("\nModification of 1st_column:\n", Cmp_hier.columns)
print(Cmp_hier) Output:
Example #4
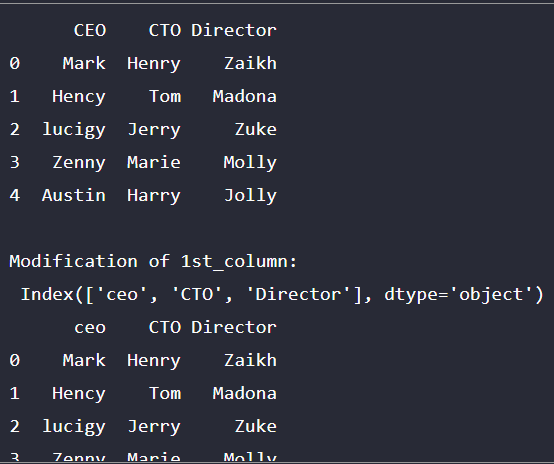
This program demonstrates the Panda column functionality with respect to renaming multiple columns using the data frame as shown in the output.
Code:
import pandas as pd
Company_Hierarchy = {
'CEO': ['Mark', 'Hency', 'lucigy',
'Zenny', 'Austin'],
'CTO': ['Henry', 'Tom', 'Jerry',
'Marie', 'Harry'],
'Director': ['Zaikh', 'Madona', 'Zuke',
'Molly', 'Jolly']
}
Cmp_hier = pd.DataFrame(Company_Hierarchy)
print(Cmp_hier.columns)
Cmp_hier.rename(columns = {'CEO':'ceo', 'CTO':'cto', 'Director':'director'}, inplace = True)
print(Cmp_hier.columns)
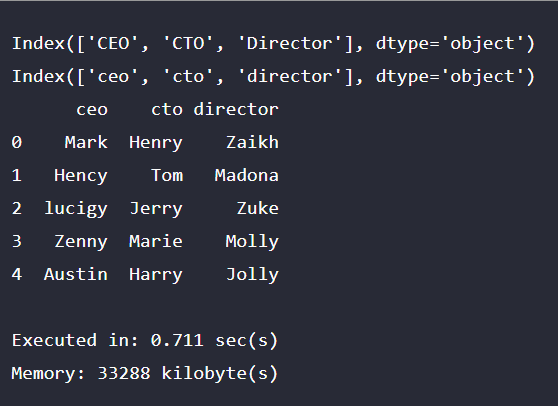
print(Cmp_hier) Output:
Example #5
This program demonstrates the modification and manipulation of the column name by adding a new column in the existing table by assigning a list of new column names instead of changing or modifying the column by renaming it again.
Code:
import pandas as pd
Company_Hierarchy = {
'CEO': ['Mark', 'Hency', 'lucigy',
'Zenny', 'Austin'],
'CTO': ['Henry', 'Tom', 'Jerry',
'Marie', 'Harry'],
'Director': ['Zaikh', 'Madona', 'Zuke',
'Molly', 'Jolly']
}
Cmp_hier = pd.DataFrame(Company_Hierarchy)
print(Cmp_hier.columns)
Cmp_hier.columns = ['ceo', 'cto', 'director']
print(Cmp_hier)Output:

Example #6
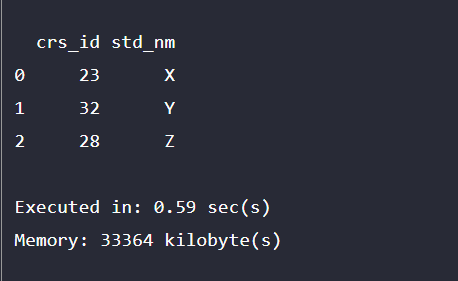
This program illustrates the selection of the column where the column which is not required is selected and dropped as shown in the output.
Code:
import pandas as pd
dt_u = pd.DataFrame({
'crs_id': ['23', '32',
'28'],
'std_nm': ['X', 'Y',
'Z'],
'std_city': ['Mumbai', 'Bangalore',
'Noida']})
dta_fm = dt_u.drop('std_city',
axis = 1)
print(dta_fm)Output:
Conclusion
The dataframe plays a pivotal role in terms of data related to rows and columns. It also helps in creating data which can be accessed anytime with the help of Pandas library and Provides aid with all the standard libraries to revolve and play around with the columns and various operations.
Recommended Articles
We hope that this EDUCBA information on “Pandas Column” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

