Updated July 1, 2023

Introduction to Pandas DataFrame.append()
Pandas Dataframe.append() function adds rows of other dataframe to the furthest limit of the given dataframe, restoring another dataframe object. The columns in the first dataframe are not included as new columns, and the new cells are represented with NaN esteem. Python Pandas dataframe append() work includes a single arrangement, word reference, dataframe as a column in the dataframe. We can include different lines also.
Syntax
Below is the syntax with an explanation:
DataFrame.append(verify_integrity=False, sort=None, index=False, other)Explanation: Where, Verify_integrity is always considered as false as default values because if it is true, it raises a ValueError, which in turn creates duplicates for all values. Sort checks if the columns of the dataframe are organized properly. The default arranging is deplored and will change to not-arranging in a future rendition of pandas. Unequivocally pass sort=True to quiet the notice and sort. Expressly pass sort=False to quiet the notice and not sort. Index means if we want to ignore the index, it does not produce labels for all the indices. Other represents anything other than the dataframe and also can be used in the append() function like a dictionary or series.
Examples to Implement Pandas DataFrame.append()
Now we see various examples mentioned:
Example #1
Appending the second dataframe to the first dataframe by creating two dataframes:
Code:
import pandas as pd
dfs = df = pd.DataFrame({"n":[2, 3, 5, 1],
"a":[4, 6, 8, 9]})
dfp = pd.DataFrame({"m":[4, 5, 6],
"d":[7, 8, 9]})
print(dfs, "\n")
print(dfp, "\n")Output:
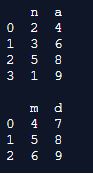
Explanation: In the above program, we first import the panda’s library and create 2 dataframes. The first dataframe and the second dataframe are termed dfp and up.
Example #2
Appending different shapes of dataframe:
Code:
import pandas as pd
dfs = pd.DataFrame({"d":[2, 3, 4, 5],
"e":[6, 7, 8, 9]})
dfp = pd.DataFrame({"x":[5, 4, 3],
"y":[1, 2, 6],
"z":[8, 7, 9]})
dfs.append(dfp, ignore_index = True)
print(dfs.append(dfp, ignore_index = True) )Output:
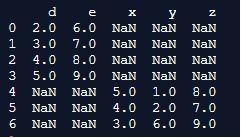
Example #3
Using append() function to append the second dataframe at the end of the first dataframe:
Code:
import pandas as pd
dfs = df = pd.DataFrame({"n":[2, 3, 5, 1],
"a":[4, 6, 8, 9]})
dfp = pd.DataFrame({"m":[4, 5, 6],
"d":[7, 8, 9]})
dfs.append(dfp)
dfs.append(dfp, ignore_index = True)
print(dfs.append(dfp))
print(dfs.append(dfp, ignore_index = True) )Output:
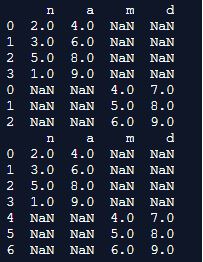
Explanation: In the above program, we first import the Pandas library and create two dataframes. Since we have to use the append() function to append the second dataframe at the end of the first dataframe, we use the command dfs=dfs.append(df). Once we print this, it produces the first set of dataframe, as shown in the above snapshot. The second command which we will be giving is the append command to assign ignore index parameter to true. This means to say that it produces NaN values in the output in the second dataframe, as shown in the above snapshot. Hence, we can use the append() function to manipulate the dataframes in Pandas.
Conclusion
A superior arrangement is to annex those lines to a rundown and afterward connect the rundown with the first DataFrame at the same time. Pandas DataFrame append() work consolidates columns from another DataFrame object. This capacity restores another DataFrame object and does not change the source objects.
Recommended Articles
We hope that this EDUCBA information on “Pandas DataFrame.append()” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

