Updated April 14, 2023
Introduction to Pandas DataFrame.merge()
According to the business necessities, there may be a need to conjoin two dataframes together by several conditions. This process can be achieved in pandas dataframe by two ways one is through join() method and the other is by means of merge() method. Hence for attaining all the join techniques related to the database the merge() method can be used. Apart from the merge method these join techniques could also be achieved by means of join() method in pandas.
Syntax and Parameter
Syntax of pandas dataframe.merge() are given below:
DataFrame.merge(self, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None) Parameter
Parameter of pandas dataframe.merge() are given below:
| Parameter | Description |
| left | This represents the dataframe which is expected to be placed on the left, So the dataframe which needs to be placed in the left side of the relation is assigned here. |
| right | This represents the dataframe which is expected to be placed on the right, So the dataframe which needs to be placed in the right side of the relation is assigned here. |
| how | The type of join carried on is mentioned here, So assigning a value to this argument decides the type of join to take place. The most predominantly used join techniques are outer join, inner join, right join, or left join. |
| left_on | This represents the keys which is expected to be placed from the left dataframe, So during the join process which columns from the left are considered for the join are mentioned here. |
| right_on | This represents the keys which is expected to be placed from the right dataframe, So during the join process which columns from the right are considered for the join are mentioned here. |
| left_index | Index to be placed in the join process for the left dataframe. |
| right_index | Index to be placed in the join process for the right dataframe. |
| sort | Sort the output, When the received output is considered to be sorted then this argument is used. This argument is of the boolean type which holds the default value as false. |
| suffixes | For the overlapping column names, the suffixes to be applied are mentioned here. An exception on the overlapping columns are raised using ( False, False ) |
| copy | This another argument in boolean type which is used to confirm whether a copy of the data needs to be carried on or not. If the copy process needs to be avoided then this argument needs to be set as false. So setting the argument with the default value will keep the copy operation inplace. |
| indicator | The indicator argument is also of boolean type and additional it can also take in string values. When the indicator column is set to true then it adds an additional column to the output dataframe namely “_merge” which holds information about the source of each and every row. When the argument holds a string value A addition will be made to the output dataframe and the addition will be a column that holds information about the source of each and every row. Information column is Categorical-type and receives “left_only” inorder for the observations were the merge key of it only come into view in ‘left’ DataFrame, “right_only” for observations whose were the merge key of it only come into view in in ‘right’ DataFrame, and “both” when the observations are been merged. |
| validate | “one_to_one” or “1:1”: This helps to validate whether the keys in both the left and right dataframes are unique.
“one_to_many” or “1:m”: check This helps to validate whether the keys in left dataframes is unique. “many_to_one” or “m:1”: check This helps to validate whether the keys in right dataframes is unique. “many_to_many” or “m:m”: No checks are made. |
Examples of Pandas DataFrame.merge()
Following are the examples of Pandas DataFrame.merge() are:
Example #1 – Inner Join
Code:
import pandas as pd
left_dataframe = pd.DataFrame({'key':['Key_0','Key_1','Key_4','Key_7'],
'B':[145,2373,415,2946]})
right_dataframe = pd.DataFrame({'key': ['Key_0', 'Key_1', 'Key_2', 'Key_3', 'Key_4', 'Key_5'],
'A': ['113', '2342', '4567', '2563', '2234', '71218'],
'B': ['991.03', '993.13', '983.12', '936.45', '995.44', '999.99']})
print(" THE LEFT DATAFRAME ")
print(left_dataframe )
print("")
print(" THE RIGHT DATAFRAME ")
print(right_dataframe )
print("")
print(" THE INNER JOIN ")
print(pd.merge(left_dataframe ,right_dataframe ,on=['key','key']))Output:
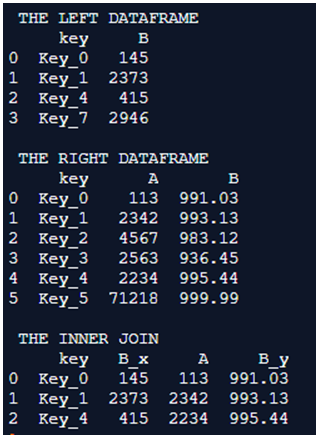
Code Explanation: Two different dataframes are declared here, One will be representing the left dataframe and the other dataframe is used for representing the right. These dataframes are formulated with values during their declaration itself. The inner join is accomplished with these dataframes using the merge() method and the resulting dataframe is printed onto the console.
Example #2 – Left Join
Code:
import pandas as pd
left_dataframe = pd.DataFrame({'key':['Key_0','Key_1','Key_4','Key_7'],
'B':[145,2373,415,2946]})
right_dataframe = pd.DataFrame({'key': ['Key_0', 'Key_1', 'Key_2', 'Key_3', 'Key_4', 'Key_5'],
'A': ['113', '2342', '4567', '2563', '2234', '71218'],
'B': ['991.03', '993.13', '983.12', '936.45', '995.44', '999.99']})
print(" THE LEFT DATAFRAME ")
print(left_dataframe )
print("")
print(" THE RIGHT DATAFRAME ")
print(right_dataframe )
print("")
print(" LEFT JOIN ")
print(pd.merge(left_dataframe ,right_dataframe ,on=['key','key'],how='left'))Output:

Code Explanation: Two different dataframes are declared here, One will be representing the left dataframe and the other dataframe is used for representing the right. These dataframes are formulated with values during their declaration itself. The left join is accomplished with these dataframes using the merge() method and the resulting dataframe is printed onto the console.
Example #3 – Right Join
Code:
import pandas as pd
left_dataframe = pd.DataFrame({'key':['Key_0','Key_1','Key_4','Key_7'],
'B':[145,2373,415,2946]})
right_dataframe = pd.DataFrame({'key': ['Key_0', 'Key_1', 'Key_2', 'Key_3', 'Key_4', 'Key_5'],
'A': ['113', '2342', '4567', '2563', '2234', '71218'],
'B': ['991.03', '993.13', '983.12', '936.45', '995.44', '999.99']})
print(" THE LEFT DATAFRAME ")
print(left_dataframe )
print("")
print(" THE RIGHT DATAFRAME ")
print(right_dataframe )
print("")
print(" RIGHT JOIN ")
print(pd.merge(left_dataframe ,right_dataframe ,on=['key','key'],how='right'))Output:

Code Explanation: Two different dataframes are declared here, One will be representing the left dataframe and the other dataframe is used for representing the right. These dataframes are formulated with values during their declaration itself. The right join is accomplished with these dataframes using the merge() method and the resulting dataframe is printed onto the console.
Example #4 – Outer Join
Code:
import pandas as pd
left_dataframe = pd.DataFrame({'key':['Key_0','Key_1','Key_4','Key_7'],
'B':[145,2373,415,2946]})
right_dataframe = pd.DataFrame({'key': ['Key_0', 'Key_1', 'Key_2', 'Key_3', 'Key_4', 'Key_5'],
'A': ['113', '2342', '4567', '2563', '2234', '71218'],
'B': ['991.03', '993.13', '983.12', '936.45', '995.44', '999.99']})
print(" THE LEFT DATAFRAME ")
print(left_dataframe )
print("")
print(" THE RIGHT DATAFRAME ")
print(right_dataframe )
print("")
print(" OUTER JOIN ")
print(pd.merge(left_dataframe ,right_dataframe ,on=['key','key'],how='outer'))Output:

Code Explanation: Two different dataframes are declared here, One will be representing the left dataframe and the other dataframe is used for representing the right. These dataframes are formulated with values during their declaration itself. The outer join is accomplished with these dataframes using the merge() method and the resulting dataframe is printed onto the console.
Recommended Articles
We hope that this EDUCBA information on “Pandas DataFrame.merge()” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

