Updated April 20, 2023

Introduction to Pandas DataFrame.filter()
Pandas DataFrame.filter() function is used in Pandas tying activity, to get to a particular dataframe section and to choose lines. Pandas binding makes it simple to consolidate one Pandas order with another Pandas order or client characterized capacities. Pandas DataFrame.filter() work is utilized to Subset lines or segments of dataframe as indicated by names in the predetermined file. This routine does not channel a data frame on its substance. The channel is applied to the marks of the list.
Syntax and Parameters:
DataFrame.filter(items=None, self, like=None, regex= None, axis=None)Where,
- Items represent lists that keep marks from the hub which are in things.
- Like represents string values which should be equal to true so that the axis values are unchanged.
- Regex represents a string value where the labels of this regex parameter is true and it lies in and around the axis.
- Axis here basically represents the row and column values which are represented as 0 and 1. The pivot to channel on, communicated either as a list (integer) or hub name (string). As a matter of course this is the information pivot, ‘file’ for Series, ‘sections’ for DataFrame.
How filter() Function works in Pandas DataFrame?
Given below are the examples on how filter() function works in Pandas DataFrame:
Example #1
Code:
import numpy as np
import pandas as pd
info = {'name': ['Span', 'Vetts', 'Sucu', 'Appu', 'Sri'],
'year': [2010, 2011, 2012, 2013, 2014],
'sal': [10500, 12345, 11460, 13987, 15634]}
df = pd.DataFrame(info, index = ['Span', 'Span', 'Vetts', 'Vetts', 'Vetts'])
df_filtered = df.query('sal>11000')
print(df_filtered)Output:
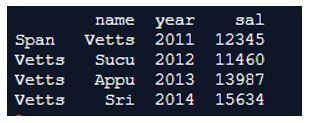
In the above program, we see that first we need to import pandas library as pd and also import numpy library as np. After importing both the libraries we create the pandas dataframe and add all the index values inside the pandas dataframe. Then, we use the filter() function to filter all the salaries of the people which is less tan 11000. Hence in the output, only the people salaries of more than 11000 is produced as shown in the above snapshot.
Example #2
Code:
import numpy as np
import pandas as pd
info = {'name': ['Span', 'Vetts', 'Sucu', 'Appu', 'Sri'],
'year': [2010, 2011, 2012, 2013, 2014],
'sal': [11345, 12345, 11460, 13987, 15634]}
df = pd.DataFrame(info, index = ['Span', 'Span', 'Vetts', 'Vetts', 'Vetts'])
df_filtered = df[(df.sal >= 11000) & (df.year == 2012)]
print(df_filtered)Output:
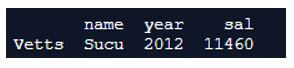
In the above program, we as before import numpy and pandas libraries and then define the dataframe. After the dataframe is created with suitable index values, we use the filter() function to filter all the salaries which are less than 11000 and also show the salary of the year 2012 only. Hence, the program is implemented and the above output is produced.
Information Filtering is one of the most regular information control activity. It is like where provision in SQL or you probably utilized channel in MS Excel for choosing explicit lines dependent on certain conditions. Regarding speed, python has a proficient method to perform separating and accumulation. It has an incredible bundle called pandas for information fighting assignments. Pandas has been based on head of numpy bundle which was written in C language which is a low level language. Subsequently information control utilizing pandas bundle is quick and savvy approach to deal with enormous measured datasets. df.index is a function which returns list names. df.index[0:5] is required rather than 0:5 (without df.index) on the grounds that file marks do not generally in succession and start from 0. It can begin from any number or even can have letter set letters.
Pandas is a broad Python library utilized by Data Scientists in a differed number of fields. In the event that you have worked in Microsoft Excel or MySQL, you are now acquainted with social information structures. You should be alright with the information organized in lines and sections. Here came to think about the library while learning AI in Python. Pandas not just offer you devises to complete broad information examination and measurable derivations but since it is based upon NumPy (another significant Python library) it ends up being a stage to manufacture exceptionally complex AI and fake neural system calculations. Pandas is outfitted with a tremendous number of capacities and classes that give you enough capacity to manage any information investigation issue.
Conclusion – Pandas DataFrame.filter()
Thus, we conclude by stating that Python is an extraordinary language for doing information investigation, basically as a result of the awesome environment of information-driven python bundles. Pandas is one of those bundles and makes bringing in and breaking down information a lot simpler. We can likewise utilize Pandas’ anchoring activity, to get to a dataframe segment and to choose lines like past model. Pandas tying makes it simple to consolidate one Pandas order with another Pandas order or client characterized capacities.
Recommended Articles
We hope that this EDUCBA information on “Pandas DataFrame.filter()” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

