Updated April 15, 2023

Introduction to Pandas Dataframe.join()
Pandas Dataframe.join() is an inbuilt function that is utilized to join or link distinctive DataFrames. In more straightforward words, Pandas Dataframe.join() can be characterized as a method of joining standard fields of various DataFrames. The columns which consist of basic qualities and are utilized for joining are called join key.
join() function goes about as a basic property when one DataFrame is a query table, that is, it contains the greater part of the information, and extra information of that DataFrame is available in some other DataFrame. Joining DataFrames is the central procedure to begin with information examination and AI undertakings. It is one of the toolboxes which each data Analyst or Data Scientist should ace on the grounds that in practically all the cases information originates from various source and records.
We may need to get all the information one spot by a type of join rationale and afterward start your examination. Individuals who work with SQL like inquiry dialects may know the significance of this errand. Regardless of whether you need to construct some AI models on certain information, you may need to consolidate numerous CSV records in a solitary DataFrame.
Syntax and Parameters
Syntax and parameters of pandas dataframe.join() is given below:
DataFrame.join(other, on=None, how='left', lsuffix='', rsuffix='', sort=False)Where,
Sort represents an organization of values in a chronological fashion. This is always a Boolean value and it is by default present as false because otherwise, it does not help in organizing the result. Lsuffix means the left suffix and it alludes to the string object that has default esteem and utilizes the addition from the left edge’s covering columns. Rsuffix means right suffix and it alludes to an object of a string that has default esteem and utilizes the addition from the right edge’s covering columns.
How handles both the left and right suffix operations. Left means it utilizes the index column on the left and right represents the rest of the indices of the dataframe. Outer represents the other indices which are present outside the specified dataframe. Inner represents all the inner indices which are a union with the specified dataframe in order to sort the values.
Onrepresents the discretionary boundary that alludes to cluster like or string values. It alludes to the section or the file level name in the guest DataFrame to join on the list. Else, it joins the list on a record. One significant factor is that on the off chance that various qualities are available, at that point the other DataFrame ought to likewise be multi filed. Others represents the DataFrame or list or the arrangement we are passing. The record ought to be equivalent to one of the sections. On the off chance that an arrangement is passed, its name must be set, which will be utilized in the section name in the subsequent DataFrame.
How Dataframe.join() Function Works in Pandas?
Now we see examples and explain how this join() function works in Pandas.
Example #1 – Usage of Join() Function
Code:
import pandas as pd
info1 = pd.DataFrame({'Reg_no': ['11', '12', '13', '14', '15', '16'],
'Result1': ['77', '79', '96', '38', '54', '69']})
print(info1)
info2 = pd.DataFrame({'Reg_no': ['11', '12', '13'],
'Result2': ['72', '82', '92']})
print(info2)
final_info = info1.join(info2.set_index('Reg_no'), on="Reg_no")
print(final_info)Output:
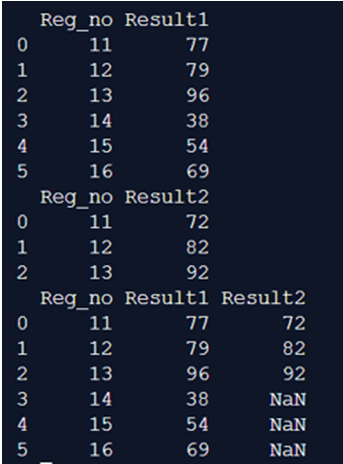
In the above program, we first import pandas as pd, and then we create two separate dataframes of marks of students according to their registration numbers. Here, we see that we want to join the two dataframes using the join() function. Hence, we use the Dataframe.join() in order to display the results in the above program, and finally, the command takes this and prints the final result as the output.
Differences between Merge() Function and Join() Function
Now we see the differences between merge() function and join() function.
| Join() Function | Merge() Function |
| Join() function is used as needed to consolidate two dataframes dependent on their separate lists. On the off chance that there are covering sections, the join will need you to add an addition to the covering segment name from the left dataframe. | Merge() function is utilized for adjusting and consolidating of columns. As a matter of course, consolidation will search for covering sections in which to converge on. Merge() function gives better authority over union keys by permitting the client to determine a subset of the covering segments to use with boundary on, or to independently permit the determination of which segments on the left and which segments on the option to converge by. |
Conclusion
Finally, we conclude by saying that Pandas has full-highlighted, superior in-memory join activities colloquially fundamentally the same as social databases like SQL. The Dataframe.join() strategy get segments together with other DataFrame either on a file or on a key section. Effectively join numerous DataFrame objects by file on the double by passing a rundown. We can either join the DataFrames vertically or next to each other. By vertically, we mean joining the DataFrames segment savvy, and one next to the other identifies with ordering. Thus, it goes about as an exceptionally helpful way joining the sections of two diversely filed DataFrames into a solitary DataFrame dependent on regular properties. We can likewise join information by passing a rundown to it.
Recommended Articles
We hope that this EDUCBA information on “Pandas Dataframe.join()” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

