Updated April 10, 2023
Introduction to Pandas DataFrame.sample()
In Pandas DataFrame.sample(). Sampling is one of the key processes in any operation. There is always a need to sample a small set of elements from the actual list and apply the expected operation over this small set which ensures that the process involved in the operation works fine. In the pandas library, this sampling process is attained by the sample() method. The sampling method is responsible for selecting a random set of values from the given data entity over which the intended process can be sample tested.
Syntax
DataFrame.sample(self:
~FrameOrSeries, n=None, frac=None, replace=False, weights=None, random_s
tate=None, axis=None)| Parameter | Description |
| n | This argument is an int parameter that is used to mention the total number of items to be returned as a part of this sampling process. This parameter cannot be combined and used with the frac parameter. The default value for the n parameter is 1, so when this is on default value the frac parameter needs to be None. |
| frac | Different to the n parameter the frac parameter is used for mentioning the fraction of data to be handled, It is used to mention the fraction of data to be considered for sampling. This parameter cannot be combined and used with the n parameter. |
| weights | This is an optional parameter, Here equal weighting probability can be achieved when the value is None. The targeted object can be aligned on the index if the values are passed as a series. Weights of index values not established in the sampled objects will be unobserved and index values in the sampled object don’t have any assigned weights to zero. when the axis is zero for a dataframe this will accept the column. Unless weights are a Series, weights must be the same length as axis being sampled. When the sum of all weights does not make as 1, then a normalization process will be applied to sum it up o 1. Zero will be considered when no values are specified in the weights. |
| axis | This argument represents the column or the axis upon which the sample() function needs to be applied. The value specified in this argument represents either a column, position, or location in a dataframe. to achieve this capability to flexibly travel over a dataframe the axis value is framed on below means, {index (0), columns (1)}. |
| random_state | This is the base for the random number generator |
Examples to Implement Pandas DataFrame.sample()
Below are the examples mentioned:
Example #1
Code:
import pandas as pd
Core_Series = pd.Series([ 1, 6, 11, 15, 21, 26])
print(" THE CORE SERIES ")
print(Core_Series)
sample_Series = Core_Series.sample(n=2)
print("")
print(" THE SAMPLE SERIES ")
print(sample_Series)Output:
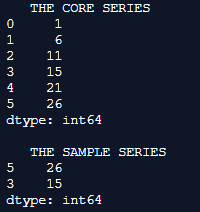
Explanation: Here the panda’s library is initially imported and the imported library is used for creating a series. The values in the series are formulated in such a way that they are a series of 1 to n. The apply() method is placed over this series with a lambda function. The sample() method on this series with a sampling set of 2 returns the sample records alone on to the console.
Example #2
Code:
import pandas as pd
Core_Dataframe = pd.DataFrame({'A' : [ 1, 6, 11, 15, 21, 26],
'B' : [2, 7, 12, 17, 22, 27],
'C' : [3, 8, 13, 18, 23, 28],
'D' : [4, 9, 14, 19, 24, 29],
'E' : [5, 10, 15, 20, 25, 30]})
print(" THE CORE DATAFRAME ")
print(Core_Dataframe)
sample_Dataframe = Core_Dataframe.sample(n=3)
print("")
print(" THE SAMPLE DATAFRAME ")
print(sample_Dataframe)Output:
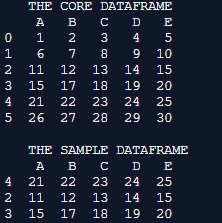
Explanation: Here the panda’s library is initially imported and the imported library is used for creating the dataframe which is a shape(6,6). all of the columns in the dataframe are assigned with headers that are alphabetic. the values in the dataframe are formulated in such a way that they are a series of 1 to n. this dataframe is programmatically named here as a core dataframe. The sample() method with n as 3 returns a sampled set of three records to the console.
Example #3
Code:
import pandas as pd
Core_Dataframe = pd.DataFrame({'Column1' : [ 'A', 'B', 'C', 'D', 'E', 'F'],
'Column2' : [ 'G', 'H', 'I', 'J', 'K', 'L'],
'Column3' : [ 'M', 'N', 'O', 'P', 'Q', 'R'],
'Column4' : [ 'S', 'T', 'U', 'V', 'W', 'X'],
'Column5' : [ 'Y', 'Z', None, None, None, None]})
print(" THE CORE DATAFRAME ")
print(Core_Dataframe)
print("")
sample_Dataframe = Core_Dataframe.sample(frac=0.5)
print(" THE SAMPLE DATAFRAME ")
print(sample_Dataframe)Output:
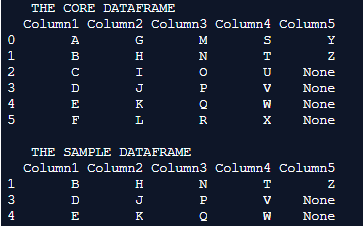
Explanation: In this example, the core dataframe is first formulated. pd.dataframe() is used for formulating the dataframe. Every row of the dataframe is inserted along with their column names. Once the dataframe is completely formulated it is printed on to the console. We can notice in this example the dataframe is associated with the values of alphabets in the English dictionary. Every column in the dictionary is tagged with suitable column names. The sample() method is used to sample 50% of the records from the core dataframe and this is mentioned using the frac parameter in the dataframe arguments. To notify as 50% the frac parameter is set to 0.5.
Example #4
Code:
import pandas as pd
Core_Dataframe = pd.DataFrame({'A' : [ 1.23, 6.66, 11.55, 15.44, 21.44, 26.4 ],
'B' : [ 2.345, 745.5, 12.4, 17.34, 22.35, 27.44 ],
'C' : [ 3.67, 8, 13.4, 18, 23, 28.44 ],
'D' : [ 4.6788, 923.3, 14.5, 19, 24, 29.44 ],
'E' : [ 5.3, 10.344, 15.556, 20.6775, 25.4455, 30.3 ]})
print(" THE CORE DATAFRAME ")
print(Core_Dataframe)
print("")
sample_Dataframe = Core_Dataframe.sample(frac=30 , replace = True , random_state=1)
print(" THE SAMPLE DATAFRAME ")
print(sample_Dataframe)Output:
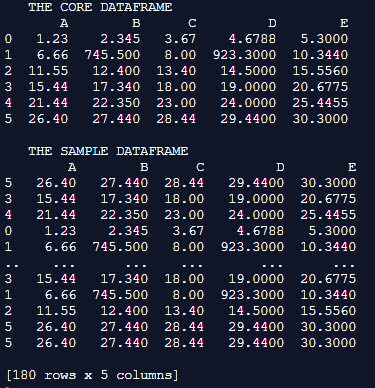
Explanation: In this example, the core dataframe is first formulated. pd.dataframe() is used for formulating the dataframe. Every row of the dataframe is inserted along with their column names. Once the dataframe is completely formulated it is printed on to the console. A typical float dataset is used in this instance. the sample() method is used here again to sample several records from the core dataframe.
Conclusion
The sample() method in pandas allows the flexibility of performing an optimized sampling process over the panda’s data structures in a very simple manner.
Recommended Articles
We hope that this EDUCBA information on “Pandas DataFrame.sample()” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

