Updated April 10, 2023

What is Pandas DataFrame to excel?
The following article provides an outline for Pandas DataFrame to excel. The process of flexibly exporting all data handled in the pandas dataframe is a critical necessity. This necessity is accomplished in pandas using the to_excel() method. The to_excel() method allows to export all the contents of the dataframe into a excel sheet, on top of performing the export process it allows to make the export process with classified set of capabilities.
Syntax:
DataFrame.to_excel(self, excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None)| Parameter | Description |
| excel-writer | The excel_writer argument is of string type which is used to hold the path of the excel sheet which is targeted for a write operation. The complete path of the excel needs to be mentioned here. If a excel_writerobject is been used then the excel_writerobject must be associated to this argument. This is the most important argument which is by default expected by the excel write process to be available. Not specifying this argument may lead to unsuccessful execution of the excel store process. |
| sheet_name | An excel workbook is a combination of multiple sheets, were a single sheet in the workbook is more specifically mentioned as worksheet. This worksheet is one specific page in the workbook which contains its own collection of cells which are intended to organized store the data. So when we need to write the data from the dataframe to one specific sheet in the workbook then the sheet name must be assigned in this argument. So this makes the data to get stored in that specific sheet alone. |
| na_rep | The na_rep is an argument of string format, which is used to offer the data representation at the missing instances. So each and every missing data representation in the dataframe can be mentioned as string format in this argument. |
| float_format | The format representation for the float values in the dataframe can be handled here. The value specified in this argument can be used to control the format in which the float values in the dataframe need to be represented when they are written to the excel sheet.
Ex: float_format=”%.2f” will format 0.756353228 as 0.75. |
| columns | As a spreadsheet is a combination of multiple rows and columns, there may be a need to print only some specific columns in the dataframe to the console. So to mention the columns which are expected to be printed on to the excel sheet they can be mentioned here. This argument has the capability to accept inputs in the form of list, string or sequence. |
| header | This argument can accept inputs in the format of string or boolean. Here a list of column names can be keyed in, these keyed in names will be assumed to be the aliases for the column names. |
| index | This is another boolean argument which is used to determine whether the index names for each of the rows needs to be printed to the excel workbook or not. So if this argument is set to true then it prints all the index values onto the excel workbook. |
| index_label | The label for the index columns are mentioned here. If not mentioned then the index names are used. |
| startrow | This is an integer argument, the default value of this argument is true. Here the value mentioned will be used to denote the uppermost left cell row in the dataframe. So the excel dump process will be starting here. |
| startcol | This is an integer argument, the default value of this argument is true. Here the value mentioned will be used to denote the uppermost left cell column in the dataframe. So the excel dump process will be starting here. |
| engine | This represents a specific write engine used, because at instances a specific engine could have been used for the excel write process like the ope npyxl engine or the xlx writer engine. So on such cases those specific engines need to be mentioned here. |
| merge_cells | Write MultiIndex and Hierarchical Rows as merged cells. |
| encoding | Used only for xlwt, this is used for encoding the resulting excel file. |
| inf_rep | It’s a string type argument which is used for representing the infinity. |
| verbose | The default value of the verbose argument is true, this argument is used to produce additional information in the error logs. |
| freeze_panes | The freeze panes argument is used to mention the rows which are expected to be frozen. |
Examples of Pandas DataFrame to excel
Given below are the examples mentioned:
Example #1
Code:
import pandas as pd
Core_Dataframe = pd.DataFrame( {
'name': ['Alan Xavier', 'Annabella', 'Janawong', 'Yistien', 'Robin sheperd', 'Amalapaul', 'Nori'],
'city': ['california', 'Toronto', 'ontario', 'Shanghai',
'Manchester', 'Cairo', 'Osaka'],
'age': [51, 38, 23, 64, 18, 57, 47],
'py_score': [82.0, 73.0, 81.0, 30.0, 48.0, 92.0, 84.0] })
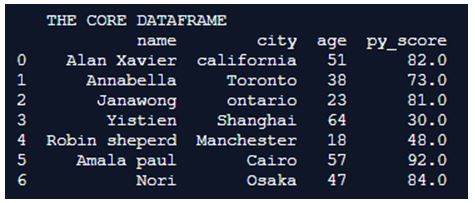
print(" THE CORE DATAFRAME ")
print(Core_Dataframe)
print("")
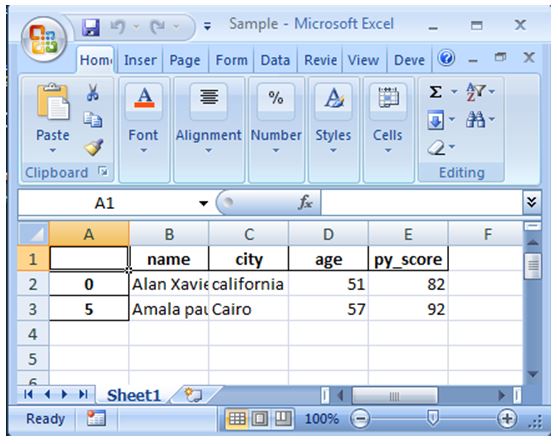
Queried_Dataframe = Core_Dataframe.query(' age > 50 and py_score> 80 ')
Queried_Dataframe.to_excel(r"C:\Users\Dell\Desktop\sample.xlsx")Output:
Explanation:
Here the dataframe is formulated with details like name, city, age and py_score. From the formulated details all rows age is greater than 50 and py_score is greater than 80 is derived as a separate dataframe and this derived dataframe is printed to the excel sheet through the to_excel() function.
Example #2
Code:
import pandas as pd
Core_Dataframe = pd.DataFrame({'A' : [ 1, 6, 11, 15, 21, 26],
'B' : [2, 7, 12, 17.2334, 22, 27],
'C' : [3, 8, 13, 18, 23.4523, 28],
'D' : [4, 9, 14, 19, 24, 29],
'E' : [5, 10, 15, 20, 25, 30]})
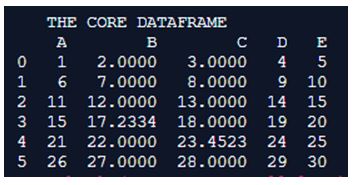
print(" THE CORE DATAFRAME ")
print(Core_Dataframe)
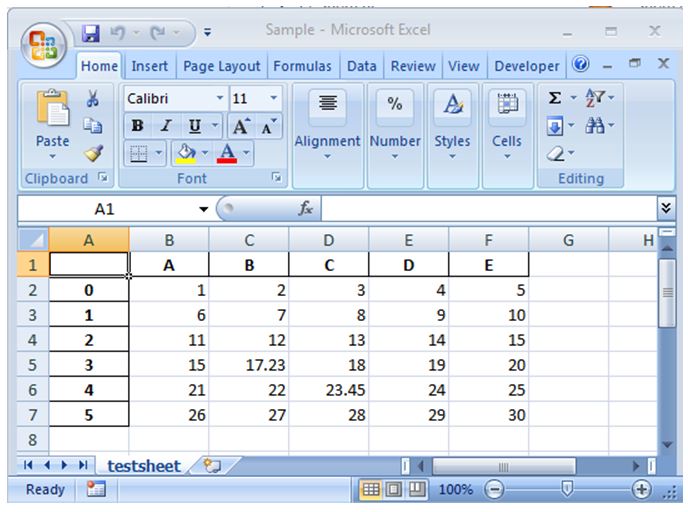
Core_Dataframe.to_excel(r"C:\Users\Dell\Desktop\sample.xlsx", sheet_name = 'testsheet',float_format =" %.2f " )Output:
Explanation:
Here the pandas library is initially imported and the imported library is used for creating the dataframe which is a shape(6,6). All of the columns in the dataframe are assigned with headers which are alphabetic. The values in the dataframe are formulated in such way that they are a series of 1 to n. This dataframe is programmatically named here as core dataframe. The values of the dataframe are printed on to the excel and a snap of the excel is all placed above.
Recommended Articles
We hope that this EDUCBA information on “Pandas DataFrame to excel” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

