Updated April 3, 2023
Definition of Pandas find
Pandas find the technique is utilized to look through a substring in each string present in an arrangement. In the event that the string is discovered, it restores the least file of its event. On the off chance that string is not discovered, it will return – 1.
Start and end focuses can likewise be passed to scan a particular piece of string for the past character or substring. Python is an incredible language for doing information examination, essentially as a result of the fabulous environment of information-driven python bundles. Pandas is one of those bundles and makes bringing in and examining information a lot simpler.
Syntax of Pandas find
Below is the syntax of Pandas find:
Pandas.find(start=0, end=None, substring)Where,
- Substring is nothing but the offspring of the main string. Therefore, it is also referred to as sub.
- Start and end parameters help us to figure out where and how to start and end the substrings in the given string.
In the event that the substring exists inside the string, it restores the list of the first occurrence of the substring. On the off chance that the substring doesn’t exist inside the string, it returns – 1.
How find() function works in Pandas?
Now we see various examples of how the find() function works in Pandas.
Example #1
Using find() function in pandas without start and end parameters.
Code:
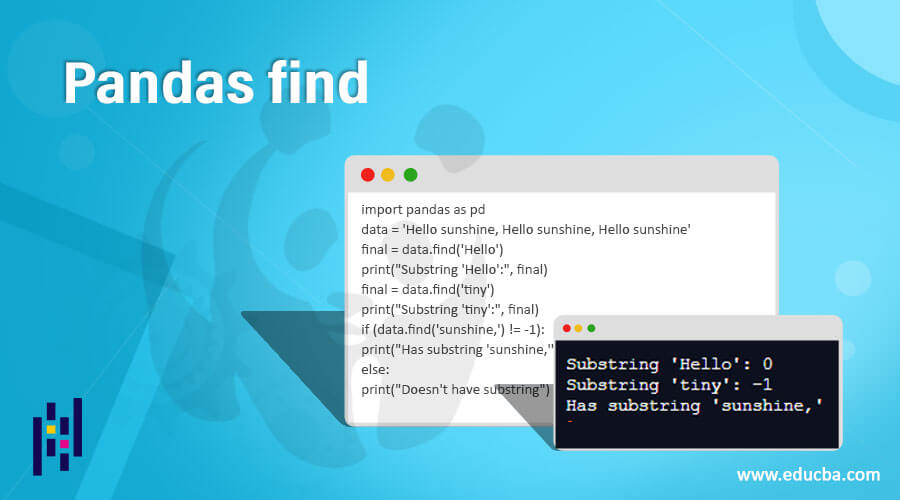
import pandas as pd
data = 'Hello sunshine, Hello sunshine, Hello sunshine'
final = data.find('Hello')
print("Substring 'Hello':", final)
final = data.find('tiny')
print("Substring 'tiny':", final)
if (data.find('sunshine,') != -1):
print("Has substring 'sunshine,'")
else:
print("Doesn't have substring")Output:
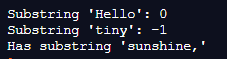
In the above program, we first import the panda’s library as pd and then create a series of strings ‘Hello sunshine’ as shown in the above code. Then we print the resulting string and use the find() function to find the substring and differentiate between the main string and the substring use the if and else statements; and thus, the program is implemented, and the result is as shown in the above snapshot.
Example #2
Using the find() function in pandas to implement the strings with start and end parameters.
Code:
import pandas as pd
data = 'Help ever hurt never'
print(data.find('Help ever', 2))
print(data.find('Help ever', 3))
print(data.find('p ever ', 2, -1))
print(data.find('never ', 5, 3))Output:
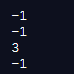
As shown previously, in the above program, we import pandas as pd and then define the string and add the statement to it. After that, we define the start and end parameters and accordingly, the program is implemented, and the output is as shown in the above snapshot. The values are also returned according to the string and substring values.
To make recognizing missing qualities simpler (and across various cluster data types), Pandas gives the isnull() and notnull() capacities. While adding information, NA will be treated as Zero. In the event that the information is all NA, at that point, the outcome will be NA.
Pandas give different strategies to cleaning the missing qualities. The fillna capacity can “fill in” NA esteems with non-invalid information in two or three different ways, which we have represented in the accompanying areas. On the off chance that you need to just prohibit the missing qualities, at that point, utilize the dropna work alongside the hub contention. As a matter of course, axis=0, i.e., along the column, which implies that on the off chance that any incentive inside a line is NA, at that point, the entire line is prohibited.
Name section utilizing str.find() technique. Start and end boundaries are kept default. The returned arrangement is put away in another section so that the records can be thought about by looking legitimately. Before applying this technique, invalid lines are dropped utilizing dropna() to stay away from blunders.
The find() strategy finds the main event of the predetermined worth. The find() technique returns – 1 if the worth isn’t found. Thus, the find() technique is nearly equivalent to the file() strategy; the main distinction is that the list() technique raises a special case if the worth isn’t found.
Conclusion
Hence, we would like to conclude by stating that Missing information is consistently an issue, in actuality, situation. Territories like AI and information mining face serious issues in the exactness of their model forecasts on account of the low quality of information brought about by missing qualities. In these regions, missing worth treatment is a significant purpose of the centre to make their models more precise and legitimate. Numerous multiple times, individuals do not share all the data identified with them. However, hardly any individuals share their experience, however, not how long they are utilizing the item; scarcely any individuals share how long they are utilizing the item, their experience, yet not their contact data. Accordingly, in a few or the other way, some portion of the information is continually absent, and this is regular continuously, which is done by pandas find().
Recommended Articles
We hope that this EDUCBA information on “Pandas find” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

