Updated April 6, 2023

Introduction to Pandas Index
Pandas Index is a permanent array executing an orchestrated, sliceable set. It is the fundamental thing that stores the center names for all pandas objects. The syntax is index.values. It returns an array which substitutes the index object of the array.
Example:
import pandas as pd
idx = pd.Index([value 1, value 2, value 3, …value n])
print(idx)
output = idx.values
print(output)Here, we first import pandas as pd, and then we create an index called “idx” and type the string values and later print the index idx. Now, we use the idx.values to return the array back to the index object and finally print out the result.
- Pandas index is also termed as pandas dataframe indexing, where the data structure is two-dimensional, meaning the data is arranged in rows and columns.
- For the rows, the indexing that has to be used is the user’s choice, and there will be a Default np.arrange(n) if no index has been used.
How to Create and Work Index in Pandas?
There is a structured template to create an index in Pandas Dataframe, and that is,
import pandas as pd
data = {
column one : ['value one', 'value two', 'value three',……],
column two : ['value one', 'value two', 'value three',……],
column three : ['value one', 'value two', 'value three',……],
…….
}
df = pd.Dataframe (data, columns = ['column one', 'column two', 'column three',…], index = ['A1', 'A2', 'A3', …])We should always remember that quotes should be used only for string values and not for integers or other numeric values.
Example:
import pandas as pd
lux = {'Brand': ['Armani','Valentino','Prada','Gucci'],
'Price': [15000,16000,17000,18000]
}
df = pd.DataFrame(lux, columns = ['Brand','Price'], index=['p_1','p_2','p_3','p_4'])
print (df)Output:
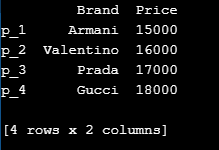
From the above example, we have data about luxury brands called “lux”. We want to print the name and prices of these brands using Pandas indexing in Python Dataframe. Firstly, we import Pandas as pd, and then we start adding values to the index; that is, we create a variable called lux and then add the brands and their prices which we want to be represented in the rows and columns format. Later, we define the dataframe as df and access the data of the luxury brands and add the index values of the products, which are represented by p_1,p_2,p_3,p_4. Thus, the system numbers these index values starting from 0 and identify the rows and the columns and finally prints out the output.
How to Multiple Index in Pandas?
Multiple Indexes or multiline indexes are nothing but the tabulation of rows and columns in multiple lines. Here the indexes can be added, removed, and replaced.
Example:
import pandas as pd
df = pd.DataFrame ({'Brand': ['Armani', 'Valentino', 'Prada', 'Gucci', 'Dolce Gabbana'],
'Price': [15000, 16000, 17000, 18000, 19000]})
df = df.set_index(['Brand', 'Price'])
print(df)Output:
In the above program, we add the same rows and columns in multiple lines and finally invoke the set index function, which thus gives the output.

How to Set and Reset Index in Pandas?
Set and reset index in pandas as follows:
1. Set_index()
Pandas set_index() is an inbuilt pandas work that is used to set the List, Series or DataFrame as a record of a Data Frame. It sets the index in the DataFrame with the available columns. This command can basically replace or expand the existing index columns.
Example:
import pandas as pd
df = pd.DataFrame ({'Brand': ['Armani', 'Valentino', 'Prada', 'Gucci', 'Dolce Gabbana'],
'Price': [15000, 16000, 17000, 18000, 19000]})
df = df.set_index('Brand')
print(df)Output:
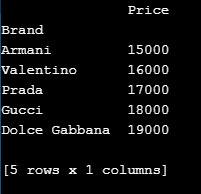
Here, we import pandas and add the values to the indices. Later, we define the set_index function and make the brand name a separate column and finally assign it to the DataFrame. Hence, in the output, as we can see, there is a separate column for ‘Brand’.
2. Reset_index():
We can use the reset command by using the syntax,
df.reset_index(drop=True)Example:
import pandas as pd
lux = {'Brand': ['Armani', 'Valentino', 'Prada', 'Gucci', 'Dolce Gabbana'],
'Price': [15000, 16000, 17000, 18000, 19000]
}
df = pd.DataFrame(lux, columns= ['Brand', 'Price'])
df = df.drop([0, 2])
df = df.reset_index(drop=True)
print(df)Output:

The first stage is to collect the data of various luxury brands and their prices.
| Brand | Price |
| Armani | 15000 |
| Valentino | 16000 |
| Prada | 17000 |
| Gucci | 18000 |
| Dolce Gabbana | 19000 |
- The next step is to create a DataFrame using the Python code. Hence we get an output of all the index numbers that are assigned to all the values in a sequential format from 0 to 4.
- The next stage is to create the drop function because without this function, it would be difficult for us to input a reset_index() command. Once we implement this drop function with the respective index numbers, the indexes will not be sequential anymore, and this command drops the 0th index value, which is “Armani”, and also the 2nd index value, which is “Prada”, and prints the rest of the output with its respective index numbers.
- Finally, we add the reset_index command and the indexes become sequential and printed in the output.
Conclusion
Pandas in Python makes it extremely easy to work and play with data analysis concepts. Having the option to gaze upward and use works quick permits us to accomplish a specific stream when composing code. Pandas DataFrame rows and columns traits are useful when we need to process just explicit rows or columns. It is additionally valuable to get the mark data and print it for future investigating purposes.
Recommended Articles
We hope that this EDUCBA information on “Pandas Index” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

