Updated June 28, 2023

Introduction to Pandas Interpolate
Pandas interpolate work is essentially used to fill NA esteems in the dataframe or arrangement. Yet, this is an amazing capacity to fill the missing qualities. It utilizes different interjection procedures to fill the missing qualities instead of hard-coding the worth. Python is an extraordinary language for doing information examination, fundamentally in view of the awesome environment of information-driven Python bundles. Pandas is one of those bundles and makes bringing in and examining information a lot simpler.
Syntax and Parameters:
Pandas.interpolate(axis=0, method='linear', inplace=False, limit=None, limit_area=None, limit_direction='forward', downcast=None, **kwargs)Where,
- Axis represents the rows and columns; if it is 0, then it is for columns, and if it is assigned to 1, it represents rows.
- Limit represents the most extreme number of successive NaNs to fill. Must be more noteworthy than 0.
- Limit direction defines whether the limit is in a forward or backward direction, and by default, it is assigned to the forward value.
- Limit area represents None (default) no fill limitation. inside Only fill, NaNs encompassed by legitimate qualities (add). outside Only fill NaNs outside substantial qualities (extrapolate). On the off chance that cutoff is determined, sequential NaNs will be filled toward this path.
- Inplace means to brief the ndarray or the nd dataframe.
- Downcast means to assign all the data types.
How does Interpolate Function work in Pandas?
Now we see various examples of how the interpolate function works in Pandas.
Example #1: Using in Linear Method
Code:
import pandas as pd
df = pd.DataFrame({"S":[11, 3, 6, None, 2],
"P":[None, 5, 67, 4, None],
"A":[25, 17, None, 1, 9],
"N":[13, 7, None, None, 8]})
df.interpolate(method ='linear', limit_direction ='forward')
print(df.interpolate(method ='linear', limit_direction ='forward') )Output:
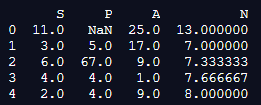
In the above program, we first import the panda’s library as pd and then create the dataframe. After creating the dataframe, we assign values to the dataframe and use the interpolate function to define the linear values in the forward direction. The program is implemented, and the output is as shown in the above snapshot.
Example #2: Using in Backward Direction
Code:
import pandas as pd
df = pd.DataFrame({"S":[11, 3, 6, None, 2],
"P":[None, 5, 67, 4, None],
"A":[25, 17, None, 1, 9],
"N":[13, 7, None, None, 8]})
df.interpolate(method ='linear', limit_direction ='backward', limit = 1)
print(df.interpolate(method ='linear', limit_direction ='backward', limit = 1) )Output:
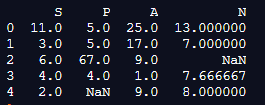
In the above program, we first import the panda’s library as before and then create the dataframe. After creating the dataframe and assigning values, we use the interpolate() function in the backward direction, and it shows all the linear values in the backward direction, as shown in the above snapshot.
In the first place, we create a pandas information outline df0 with some test information. We make a counterfeit informational index containing two houses and utilize a transgression, and a cos capacity to create some sensor read information for many dates. To create the missing qualities, we haphazardly drop half of the sections. A transgression and a cos work, both with a lot of missing information focus. Recall that it is critical to pick a sufficient introduction technique for each errand. For instance, on the off chance that you have to add information to figure out the climate, at that point, you cannot introduce the climate of today utilizing the climate of tomorrow since it is as yet obscure.
To insert the information, we can utilize the group by()- work followed by resample(). In any case, first, we have to change over the read dates to DateTime organization and set them as the file of our data frame. Since we must introduce each house independently, we must gather our information by ‘house’ before utilizing the resample() work with the alternative ‘D’ to resample the information to a day-by-day recurrence. In the event that we need to mean interject the missing qualities, we have to do this in two stages. To start with, we produce the basic information lattice by utilizing mean(). This produces the lattice with NaNs as qualities. A while later, we fill the NaNs with introduced esteems by calling the add() strategy on the read esteem segment.
Conclusion
Hence, I conclude by stating that anybody working with information realizes that genuine information is frequently sketchy, and tidying it takes up a lot of your time. One of the highlights I have learned how to acknowledge especially is the straightforward method of adding (or in-occupying) time arrangement information, which Pandas gives.
Recommended Articles
We hope that this EDUCBA information on “Pandas Interpolate” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

