Updated April 20, 2023

Introduction to Pandas left join
Pandas left join keep each column in the left dataframe. Where there are missing estimations of the on factor in the privilege dataframe, it includes void/NaN esteems in the outcome. The Pandas combine activity acts with an inward consolidation. An inward consolidation or internal join keeps just the regular qualities in both the left and right dataframes for the outcome. In our model above, just the lines that contain user id values that are regular among user usage and user device stay in the outcome dataset. We can approve this by taking a gander at what number of qualities are normal. In the yield/result, lines from the left and right dataframes are coordinated up where there are basic estimations of the joined section indicated by on.
Syntax and Parameters
Pandas.join(right,left,on=None,how='inner',right_on=None,left_on=None,right_index=False, left_index=False, sort=True)Where,
- left and right indicate both the dataframe objects that has to be returned.
- on represents the segments or names to join on. Must be found in both the left and right DataFrame objects.
- left_on and right_on indicates the sections from the left and right DataFrame to use as keys. Can either be segment names or exhibits with length equivalent to the length of the DataFrame.
- left_index and right_index represents assuming True, utilize the record (column marks) from the left and right DataFrame as its join key. If there should arise an occurrence of a DataFrame with a MultiIndex (various levelled), the quantity of levels must match the quantity of join keys from the privilege DataFrame.
- sort indicates the outcome DataFrame by the join keys in lexicographical request. Defaults to True, setting to False will improve the exhibition significantly by and large.
How left join work in Pandas?
Given below shows how left join works in pandas:
Example #1
Code:
import pandas as pd
left = pd.DataFrame({
'id':[6,7,8,9,3],
'Name': ['Span', 'Vetts', 'Sucu', 'Appu', 'Sri'],
'subjects':['Mat','Sci','Soc','En','Kan']})
print (left)Output:
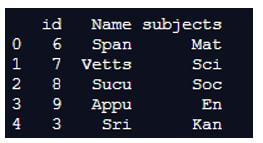
In the above program, we first import the pandas library as pd and then define the dataframe. From the above dataframe, we use the left join function to print all the parameters of the dataframe and print the output.
Example #2
Code:
import pandas as pd
left = pd.DataFrame({
'Sr':[6,7,8,9,2],
'Name': ['Span', 'Suchu', 'Vetts', 'Appu', 'Sri'],
'subjects':['Math','Sci','Soc','Eng','Kan']})
right = pd.DataFrame({
'Sr':[6,7,8,9,2],
'Name': ['fil', 'mil', 'sil', 'pil', 'gil'],
'subjects':['Sans','Hin','Eng','Kan','Beng']})
print(pd.merge(left, right, on='Sr', how='left'))Output:
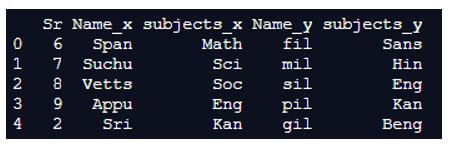
In the above program, we first import pandas as pd and then we define the dataframe. After defining the dataframe, we use the merge function and pandas left join function to define only the left parameter and thus the output is as shown in the above snapshot.
We anticipate that the outcome should have indistinguishable number of lines from the left dataframe on the grounds that each use_id in user usage shows up just a single time in user device. A coordinated planning isn’t generally the situation. In blend activities where a solitary line in the left dataframe is coordinated by numerous columns in the privilege dataframe, different outcome lines will be produced. For example, on the off chance that a use_id esteem in user usage shows up twice in the user device dataframe, there will be two columns for that use_id in the join result.
You can change the converge to one side converge with the “how” boundary to your consolidation order. The head of the outcome dataframe contains the effectively coordinated things, and at the base contains the lines in user usage that didn’t have a comparing use_id in user device.
You could compose for circles for this errand. The first would circle through the use_id in the user_usage dataset, and afterward locate the correct component in user_devices. The second for circle will rehash this procedure for the gadgets. Be that as it may, utilizing for circles will be much increasingly slow verbose than utilizing Pandas consolidate usefulness. Thus, on the off chance that you go over this circumstance we do not use for circles.
There are connecting qualities between the example datasets that are essential to note – “use_id” is shared between the user usage and user device, and the “gadget” segment of user device and “Model” segment of the gadgets dataset contain basic codes.
Conclusion
Thus, we would like to conclude by stating that the join order is the key learning goal of this post. The combining activity at its least complex takes a left dataframe (the principal contention), a privilege dataframe which is the subsequent contention, and afterward a union segment name, or a segment to converge on. With this outcome, we would now be able to proceed onward to get the producer and model number from the “gadgets” dataset. Be that as it may, first we have to comprehend somewhat more about union kinds and the extents of the yield dataframe. The words “merge” and “join” are utilized generally conversely in Pandas and different dialects, to be specific SQL and R. In Pandas, there are discrete “union” and “join” capacities, the two of which do comparable things.
Recommended Articles
We hope that this EDUCBA information on “Pandas left join” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

