Updated April 15, 2023

Introduction to Pandas merge on multiple columns
Pandas merge on multiple columns is the centre cycle to begin out with information investigation and artificial intelligence assignments. It is one of the toolboxes that every Data Analyst or Data Scientist should ace because, much of the time, information originates from various sources and documents. The most generally utilized activity identified with DataFrames is the combining activity. Two DataFrames may hold various types of data about a similar element, and they may have some equivalent segments, so we have to join the two information outlines in pandas for better dependability code.
Syntax and Parameters:
pd.merge(dataframe1, dataframe2, left_on=['column1','column2'], right_on = ['column1','column2'])Where,
left and right indicate the left and right merging of the two dataframes.
How to merge on multiple columns in Pandas?
Now we will see various examples on how to merge multiple columns and dataframes in Pandas.
Example #1
Merging multiple columns in Pandas with different values.
Code:
import pandas as pd
df1 = pd.DataFrame({'a1': [1, 1, 2, 2, 3],
'b': [1, 1, 2, 2, 2],
'c': [13, 9, 12, 5, 5]})
df2 = pd.DataFrame({'a2': [1, 2, 2, 2, 3],
'c': [1, 1, 1, 2, 2],
'd': [15, 16, 17, 18, 13]})
pd.merge(df1, df2, how='left', left_on=['a1', 'c'], right_on = ['a2','c'])
print(pd.merge(df1, df2, how='left', left_on=['a1', 'c'], right_on = ['a2','c']))Output:
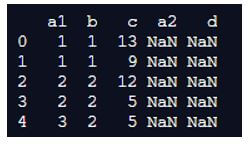
In the above program, we first import the panda’s library as pd and then create two dataframes df1 and df2. After creating the dataframes, we assign the values in rows and columns and finally use the merge function to merge these two dataframes and merge the columns of different values. Thus, the program is implemented, and the output is as shown in the above snapshot.
Example #2
Merging multiple columns of similar values.
Code:
import pandas as pd
df1 = pd.DataFrame({'s': [1, 1, 2, 2, 3],
'p': [1, 1, 2, 2, 2],
'a': [13, 9, 12, 5, 5]})
df2 = pd.DataFrame({'s': [1, 2, 2, 2, 3],
'p': [1, 1, 1, 2, 2],
'n': [15, 16, 17, 18, 13]})
pd.merge(df1, df2, how='left', on=['s', 'p'])
print(pd.merge(df1, df2, how='left', on=['s', 'p']))Output:
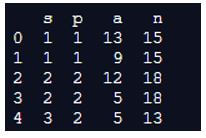
In the above program, we first import pandas as pd and then create the two dataframes like the previous program. After creating the two dataframes, we assign values in the dataframe. Now, we use the merge function to merge the values, and the program is implemented, and the output is as shown in the above snapshot.
You can accomplish both many-to-one and many-to-numerous gets together with blend(). In a many-to-one go along with, one of your datasets will have numerous lines in the union segment that recurrent similar qualities (for example, 1, 1, 3, 5, 5), while the union segment in the other dataset won’t have a rehash esteems, (for example, 1, 3, 5). As you would have speculated, in a many-to-many join, both of your union sections will have rehash esteems. These consolidations are more mind-boggling and bring about the Cartesian result of the joined columns. This implies, after the union, you’ll have each mix of lines that share a similar incentive in the key section.
What makes merge() function so adaptable is the sheer number of choices for characterizing the conduct of your union. While the rundown can appear to be overwhelming, with the training, you will have the option to expertly blend datasets of different types. ‘How’ characterizes what sort of converge to make. It defaults to ‘inward’; however other potential choices incorporate ‘external’, ‘left’, and ‘right’. ‘Left_on’ and ‘right_on’ use both of these to determine a segment or record that is available just in the left or right items that you are combining. Both default to None.
On characterizes use to this to tell merge() which segments or records (likewise called key segments or key lists) you need to join on. This is discretionary. In the event that it isn’t determined and left_index and right_index (secured underneath) are False, at that point, sections from the two DataFrames that offer names will be utilized as join keys. In the event that you use on, at that point, the segment or record you indicate must be available in the two items.
Conclusion
Hence, we would like to conclude by stating that Pandas’ Series and DataFrame objects are useful assets for investigating and breaking down information. Part of their capacity originates from a multifaceted way to deal with consolidating separate datasets. With Pandas, you can use consolidation, join, and link your datasets, permitting you to bring together and better comprehend your information as you dissect it. At the point when you need to join information objects dependent on at least one key likewise to a social data set, consolidate() is the instrument you need. All the more explicitly, blend() is most valuable when you need to join pushes that share information.
Recommended Articles
We hope that this EDUCBA information on “Pandas merge on multiple columns” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

