Updated April 10, 2023

Introduction to Pandas Set Index
Pandas set index is an inbuilt pandas work that is used to set the List, Series or DataFrame as a record of a DataFrame. Pandas DataFrame is a 2-Dimensional named data structure with columns of a possibly remarkable sort. Pandas set index() work sets the DataFrame index by utilizing existing columns. It sets the DataFrame index (rows) utilizing all the arrays of proper length or columns which are present. The document can displace the present record or create it.
Syntax:
Dataframe.set_index(keys, append, inplace, drop, verify_integrity)Where,
- keys define the name of the column or list of the columns.
- append is a command which appends the column if the index is true.
- drop is a Boolean value that drops the column if it is assigned to true.
- verify_integrity checks the new column index to duplicate it if it is true.
- Inplace replaces the column index values if it is true.
How does Set Index Work in Pandas with Examples?
Now we look at how to set the index in Pandas Dataframe using the set_index() function and also using different parameters.
Example #1
Code:
import pandas as pd
data = pd.DataFrame({
"name":["Span","Such","Vetts","Deep","Apoo","Sou","Ath","Pri","Pan","Pran","Anki"]
,"age":[25,26,27,28,29,30,31,32,33,34,35]
,"sal":[30000,40000,50000,60000,70000,80000,90000,95000,96000,97000,98000]
,"expense":[20000,30000,40000,50000,60000,70000,80000,85000,86000,87000,88000]})
data.set_index('name')
print(data.set_index('name'))Output:
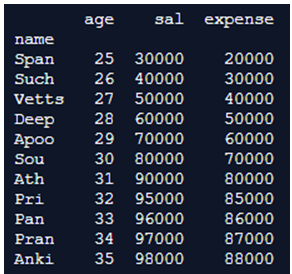
Explanation: Here, we first create a Dataframe of name, age, salary, and expenses and add the necessary values and invoke pandas with a nickname pd. After creating the dataframe, we are going the set the index using the function set_index(). Inside the brackets, we assign the column name which we want to set the index to which is ‘name’ in this case. So, we add the code, data.set_index(‘name’), and finally print the output. In the output, as you can see, the column ‘name’ has also been printed as a variable and it is completely separated from all the other columns. This is because it acts like just another index value and all the names act as index values for the rows.
Example #2 – Set_Index() Function Using the Inplace Parameter
Code:
import pandas as pd
data = pd.DataFrame({
"name":["Span","Such","Vetts","Deep","Apoo","Sou","Ath","Pri","Pan","Pran","Anki"]
,"age":[25,26,27,28,29,30,31,32,33,34,35]
,"sal":[30000,40000,50000,60000,70000,80000,90000,95000,96000,97000,98000]
,"expense":[20000,30000,40000,50000,60000,70000,80000,85000,86000,87000,88000]})
data_copy=data.copy()
data_copy.set_index('name', inplace = True)
print(data_copy)Output:
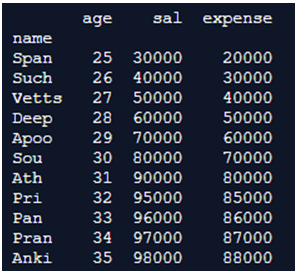
Explanation: In this program, we are going to set the index “set_index” by utilizing the inplace parameter. To do this, we are going to set inplace = True in our linguistic structure. Before we do that, however, how about we make a duplicate of information. The explanation that we will make a duplicate is on the grounds that when we use inplace = True, the set_index technique will overwrite the information. I would prefer not to overwrite information straightforwardly, so we will make a duplicate first. To duplicate the above index, we use the function copy(). Hence, data_copy() will consist of the same information as the original data. After duplicating the information, we use the set_index() function and the inplace=True parameter. By setting the inplace parameter to inplace = True, the code changes the DataFrame straightforwardly. It really composed over data_copy and supplanted it with this new form of the information with the new index.
Example #3 – Using the Drop Parameter
Code:
import pandas as pd
data = pd.DataFrame({
"name":["Span","Such","Vetts","Deep","Apoo","Sou","Ath","Pri","Pan","Pran","Anki"]
,"age":[25,26,27,28,29,30,31,32,33,34,35]
,"sal":[30000,40000,50000,60000,70000,80000,90000,95000,96000,97000,98000]
,"expense":[20000,30000,40000,50000,60000,70000,80000,85000,86000,87000,88000]})
data.set_index('name', drop = False)
print(data.set_index('name', drop = False))Output:

Explanation: At whatever point we set another index for a Pandas DataFrame, the column we select as the new index is expelled as a column. For instance, in the past models when we set name as the list, the name was not, at this point an “appropriate” column. This is because the program by default considers itself to be drop=True. Here, when drop=False, the usual index will remain the same in the different columns and also the changed index. Notice that “name” exists as the record for the data DataFrame, yet it in like manner exists as an area of the DataFrame. This is somewhat useful because there will be times when you would like to use a segment as the rundown, any way you will regardless of everything need it as a fragment too. For example, on the off chance that you are doing data discernment in Python (i.e., with Seaborn), there are a couple of mechanical assemblies that will simply work with a fragment; there are circumstances where the portrayal technique won’t work with the rundown. In these cases, it is satisfactory to have the alternative to set drop = False in case you need a variable as both the rundown and an area.
Example #4 – Using Multiple Variable in the Index
Code:
import pandas as pd
data = pd.DataFrame({
"name":["Span","Such","Vetts","Deep","Apoo","Sou","Ath","Pri","Pan","Pran","Anki"]
,"age":[25,26,27,28,29,30,31,32,33,34,35]
,"sal":[30000,40000,50000,60000,70000,80000,90000,95000,96000,97000,98000]
,"expense":[20000,30000,40000,50000,60000,70000,80000,85000,86000,87000,88000]})
data.set_index(['name','age'])
print(data.set_index(['name','age']))Output:

Explanation: In the above program, we use multiple columns and set them as indices. We doled out these factors as the record by passing them to set_index within a rundown. The contribution to set_index was the rundown [‘name’,’age’]. In the yield, you can see that the two column names and age are remembered for the new record.
Conclusion
Finally, we conclude by saying that the set_index() function creates a new Dataframe by making the given columns as indices using different parameters. To retain the index column as another separate column in the Dataframe, we use the parameter drop=False and in order to covert all the indices back to its original columns, we make use of the reset_index() function in Pandas.
Recommended Articles
We hope that this EDUCBA information on “Pandas Set Index” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

