Updated April 15, 2023

Introduction to Pandas split()
Pandas Split() gives a strategy to part the string around a passed separator or a delimiter. From that point onward, the string can be put away as a rundown in an arrangement, or it can likewise be utilized to make different segment information outlines from a solitary, isolated string. It works comparably to the Python’s default split() technique, yet it must be applied to an individual string. Pandas <code>str.split() strategy can be applied to an entire arrangement. .str must be prefixed every time before calling this strategy to separate it from the Python’s default work; else, it will toss a mistake.
Syntax and Parameters
Pandas.str.split(n=-1, pat=None, expand=False)Where,
Pat refers to string worth, separator, or delimiter to isolate string at.
‘n’ refers to quantities of max detachments to make in a solitary string; the default is – 1, which implies all.
Expand refers to Boolean worth, which restores an information outline with various incentives in various sections assuming True. Else it restores an arrangement with a rundown of strings.
How does the split() function work in Pandas?
Now we see various examples of how this split() function works in Pandas.
Example #1
Code:
import numpy as np
import pandas as pd
dfs = {'State':['Karnataka KA','Tamil Nadu TN','Andhra AP','Maharashtra MH','Delhi DL']}
dfs = pd.DataFrame(dfs,columns=['State'])
dfs.State.str.split().tolist()
print(dfs.State.str.split().tolist())Output:
![]()
In the above program, we first import pandas and NumPy libraries as pd and np, respectively. After importing these two libraries, we first define the dataframe. After defining and assigning values to the dataframe, we use the split() function to split or differentiate the values of the dataframe. Thus, the program is implemented, and the output is as shown in the above snapshot.
Example #2
Code:
import pandas as pd
dfs = pd.DataFrame({'Name': ['Span Rao', 'Vetts Pradeep',
'Such Athreya'],
'Age':[25, 27, 29]})
dfs.Name.str.split(expand=True)
print(dfs.Name.str.split(expand=True))Output:
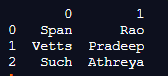
In the above program, we first import pandas as pd and then create a dataframe. After creating the dataframe and assigning values to it, we use the split() function to organize the values in the dataframe, as shown in the above code. Hence, the program is executed, and the output is as shown in the above snapshot.
This is a reasonable system for the current examination. In this post, you will figure out how to do this to address the Netflix evaluation question above utilizing the Python bundle pandas. You could do likewise in R utilizing, for instance, the dplyr bundle. I will likewise essentially dig into split objects, which are not the most natural items. The cycle of split-apply-join with split objects is an example that we as a whole perform naturally, as we’ll see; however, it took Hadley Wickham to formalize the technique in 2011 with his paper The Split-Apply-Combine Strategy for Data Analysis.
Before playing out our groupby and split-apply-consolidate system, let’s look somewhat more intently at the information to ensure it’s what we think it is and to manage missing qualities. The pandas DataFrame .information() strategy is priceless. You can drop pushes that have any missing qualities, drop any copy lines, and fabricate a pair plot of the DataFrame utilizing seaborn so as to get a visual feeling of the information. You will be shading the information by the ‘rating’ segment. Look at the plots and see what data you can get from them.
Such groupby objects are exceptionally helpful. Recollect that the .portray() technique for a DataFrame returns synopsis insights for numeric sections? Indeed, the .depict() technique for DataFrame Group By objects returns outline insights for each numeric segment, processed for each gathering in the split. For your situation, it is for each release year. This is a case of the applicant in split-apply-join: you are applying the .portray() technique to each gathering in the groupby. This record comprises of the first line numbers, marked by numbers. ‘1’ is absent as you dropped a few lines above. The record of df_med_by_year comprises of the qualities in the first section that you gathered by.
Note that we applied the str.split technique without determining a particular delimiter. Naturally, str.split utilizes a solitary space as a delimiter, and we can indicate a delimiter. Groupby objects are not natural. They do, notwithstanding, relate to a characteristic the demonstration of parting a dataset as for one its sections or multiple; however, we should spare that for another post about gathering by various segments and progressive records.
Conclusion
Hence, I would like to conclude by stating that regularly you may have a section in your panda’s information casing, and you might need to part the segment and make it into two segments in the information outline. For instance, one of the sections in your information outline is a complete name, and you might need to part into first name and last name. The split-apply-consolidate guideline isn’t just exquisite and reasonable; it’s something that Data Scientists utilize day by day, as in the above model. To acknowledge a greater amount of its uses, look at Hadley Wickham’s unique paper, The Split-Apply-Combine Strategy for Data Analysis.
Recommended Articles
We hope that this EDUCBA information on “Pandas split()” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

