Updated April 15, 2023
Introduction to Pandas value_counts()
Pandas value_counts() work returns an object containing checks of interesting qualities. The subsequent article will be in a plunging request with the goal that the primary component is the most oftentimes happening. Python is an extraordinary language for doing information investigation, basically in view of the phenomenal biological system of information-driven python bundles. Pandas is one of those bundles and makes bringing in and investigating information a lot simpler. Numpy is utilized for lower-level logical calculation. Pandas are based on the head of Numpy and intended for down to earth information examination in Python. Scikit-Learn accompanies many AI models that you can use out of the crate. In this topic, we are going to learn about Pandas value_counts().
Syntax and Parameters:
Pandas.value_counts(sort=True, normalize=False, bins=None, ascending=False, dropna=True)Where,
- Sort represents the sorting of values inside the function value_counts.
- Normalize represents exceptional quantities. In the True event, the item returned will contain the overall frequencies of the exceptional qualities at that point.
- Bins represents opposed to check esteems, bunch them into half-open canisters, a comfort for pd.cut, just works with numeric information.
- Ascending represents sorting the values in ascending order.
- Dropna represents the number of null values in the index. It helps in not counting these null values and instead gives a value NaN wherever it finds a null value.
How value_counts() works in Pandas?
Now we see how Value_counts works in Pandas with various examples.
Example #1
Using value_counts() function to count the strings in the program.
Code:
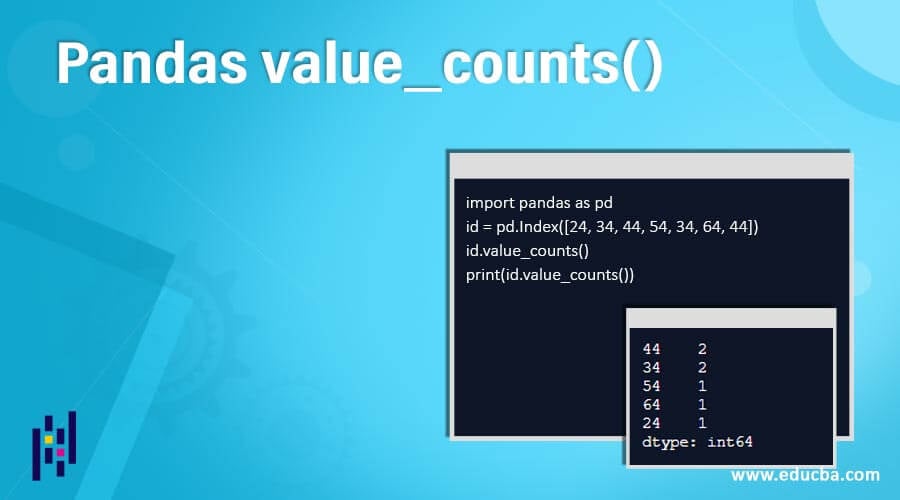
import pandas as pd
id = pd.Index(['Span', 'Vetts', 'Sucu', 'Appu', 'Span', 'Vetts'], name ='People')
id.value_counts()
print(id.value_counts())Output:
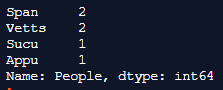
In the above program, we first import the panda’s library as pd, and then we create the index. In the index, we create 2 different columns that are one for the people, and the others are the names of these persons. After creating the indices, we define the value counts in order to implement and show the number of unique values in the program. Finally, the value_counts() function implements these parameters and returns to the series, and the output is as sown in the above snapshot.
Example #2
Using the value_counts() function to count all the unique integers in the given program.
Code:
import pandas as pd
id = pd.Index([24, 34, 44, 54, 34, 64, 44])
id.value_counts()
print(id.value_counts())Output:
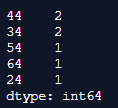
In the above program, we first import pandas as pd and then create the index. Here in the index, we add only integer values, and then we implement the value_counts() function to implements and show the unique integer values as shown in the above snapshot and then return to the series.
Information planning is the initial step after you have any kind of informational collection in your grasp. This is the progression when the pre-handling of crude information is done into a structure that can be examined rapidly and precisely. Exact information arrangement brings about a productive investigation. It disposes of blunders and manages missing information that could have happened during the information gathering process and improve information quality. Along these lines, a lot of a Data Scientist’s time is spent on information planning and highlight designing.
The value_counts() technique restores a Series containing the tallies of remarkable qualities. This implies, for any section in a dataframe, this technique restores the include of one of a kind passages in that segment.
The capacity restores the inclusion of every single special incentive in the provided record in dropping requests with no invalid qualities. Some of the time, getting a rate is a superior basis then the check. By setting normalize=True, the article returned will contain the general frequencies of the one of a kind qualities. The standardized boundary is set to False as a matter of course. The arrangement returned by value_counts() is in sliding request as a matter of course. We can turn around the case by setting the rising boundary to True.
As a matter of course, the tally of invalid qualities is avoided from the outcome. In any case, the equivalent can be shown effectively by setting the dropna boundary to False.
Value_counts() can be utilized to container constant information into discrete spans with the assistance of the receptacle boundary. This alternative works just with numerical information. It is like pd.cut work. How about we perceive how it functions utilizing the Fare segment.
Conclusion
Thus, I would like to conclude by stating that Information investigation is a significant part of the Machine Learning pipeline. The Pandas library is outfitted with various helpful capacities for this very reason, and value_counts is one of them. This capacity restores the include of one of a kind things in a pandas dataframe. In any case, more often than not, we wind up utilizing value_counts with the default boundaries. So, the series of Pandas value_counts() function returns to the series once the program is implemented.
Recommended Articles
We hope that this EDUCBA information on “Pandas value_counts()” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

