Updated May 17, 2023

Introduction to Postgresql Count
There are many aggregate functions present in the PostgreSQL database. One of the aggregate function that is used to find the row count is the COUNT() aggregate function. This function counts the total number of rows according to the query statement and clauses. When it is used on a particular column, then only non-NULL values are considered. In this article, we will see how does COUNT() function works with *, a particular column for nun-NULL values, DISTINCT keyword, GROUP BY clause, and HAVING clause with the help of examples. We will begin studying and understanding the working of the COUNT() function by learning its syntax. In this topic, we are going to learn about Postgresql Count.
Syntax
SELECT COUNT (* | [DISTINCT] ALL | columnName)
FROM tableName
[WHERE conditionalStatements];The count function can accept different parameters. It can be passed with either “*” to count all the rows in the result set or with a column name preceded by the distinct or all keyword, to count distinct or all values in that specific column. By default, it is an ALL keyword when mentioned in a particular columnName. Using the DISTINCT keyword limits the result set to unique values within the specified columns. The table name specifies the table from which we want to retrieve the result and determine the row counts. ConditionalStatements are the conditions you wish to apply in the where clause and are optional.
Example of Postgresql Count
Let us begin by connecting to out PostgreSQL database and open the psql terminal command- prompt using the following statements –
sudo su – postgres
psqlEnter the password if prompted.
The above queries will result in the access to Postgres command-prompt as follows –
Now let us create one table and insert values in it.
CREATE TABLE educba (technical_id serial PRIMARY KEY,technology_name VARCHAR (255) NOT NULL,course_Duration INTEGER,starting_date DATE NOT NULL DEFAULT CURRENT_DATE,department VARCHAR(100));Firing the above query in our psql terminal command prompt will result in the following output –

Let us insert the value in the educba table without mentioning the starting_date column’s value while inserting.
INSERT INTO educba(technology_name, course_duration, starting_date, department) VALUES ('psql',35,'2020-04-07','Database');This gives the following output –

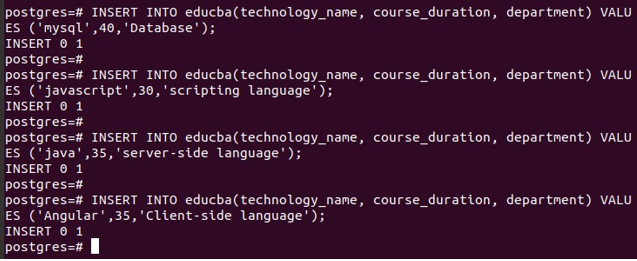
Let’s insert some more entries –
INSERT INTO educba(technology_name, course_duration, department) VALUES ('mysql',40,'Database');INSERT INTO educba(technology_name, course_duration, department) VALUES ('javascript',30,'scripting language');INSERT INTO educba(technology_name, course_duration, department) VALUES ('java',35,'server- side language');INSERT INTO educba(technology_name, course_duration, department) VALUES ('Angular',35,'Client-side language');That results in the following output –
Let us now check the contents of our table educba by firing the following SELECT command –
SELECT * FROM educba;That gives the following output –

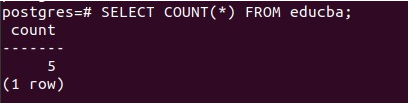
Let us retrieve the row count of the educba table using the COUNT() function. The query statement will be as follows –
SELECT COUNT(*) FROM educba;That results in the following output –
Now, let us count the rows with 35 days of course_duration using the following query statement –
SELECT COUNT(*) FROM educba WHERE course_duration=35;That results in the following output result –
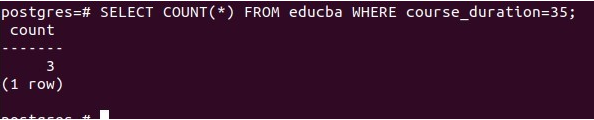
As there are three rows with psql, java, and angular as technology_name that have a course duration of 35 days, we got the row count as 3.
Using DISTINCT keyword
You can use the DISTINCT keyword in the SELECT clause whenever you want to get the unique row count of the particular column field. For example, suppose that we want to retrieve
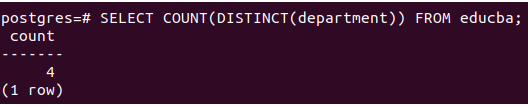
How many departments are used in the educba table then we can mention DISTINCT(department) in the SELECT clause using the following query statement –
SELECT COUNT(DISTINCT(department)) FROM educba;That results in the following output-
Using GROUP BY clause
Now, let us retrieve the count of rows grouped according to the course_duration. Following will be the query statement that will be used to get the count of records grouped based on the course_duration column –
SELECT COUNT(*),course_duration FROM educba GROUP BY course_duration;Those output will be as follows –

As three technologies are having a course duration of 35 and one technology counts with 40 and 30 days duration each, the above output is correct. But we cannot know which technologies are considered in that count. To do so, we can use GROUP_CONCAT() function.
Using string_agg function
The above query just retrieved the count of technologies grouped on course_duration used in the educba table. If we want the list of those technologies, then we can use the string_agg() function to get the comma-separated list of those technologies in the following way –
SELECT COUNT(technology_name) as technology_count, course_duration as duration_in_days ,string_agg(technology_name,',') as list_of_technologies FROM educba GROUP BY course_duration;The output of the above query statement is as follows –

Retrieving column count
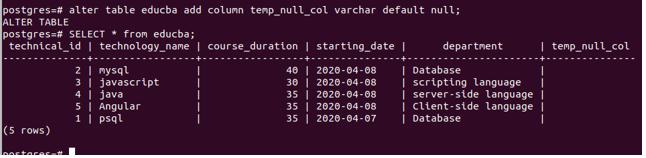
Firstly, let us add a new column to our educba table named temp_null_col column with the default null value. The alter table command is as follows –
alter table educba add column temp_null_col varchar default null;And for verifying the records of educba, we will fire the following command –
SELECT * from educba;Whose output is as follows –
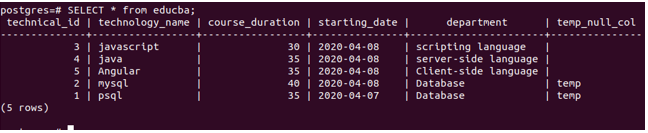
update educba set temp_null_col='temp' where department='Database';Whose output is as follows –

SELECT * from educba;That results in the following output –
Now, let us get the count of the column temp_null_col using the following query –
select count(temp_null_col) from educba;Whose output is as follows –
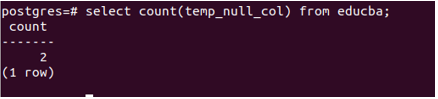
Considering only non-null values, the count of rows in the column temp_null_col is 2.
Conclusion
We can use the COUNT() aggregate function in PostgreSQL to get the count of the number of rows of the particular query statement. Internally, the query fires to obtain the result set containing all the rows that meet the condition. To determine the count value, the system performs calculations on the retrieved result set. Additionally, you can apply the COUNT() function to specific columns to retrieve the count of non-null values within those columns.
It can also be used with the GROUP BY clause to get the count of grouped results. To fetch the count of unique values, the DISTINCT() function can be used in the SELECT clause. Additionally, the string_agg() function can be employed to obtain a list of column values from other columns, excluding the column used for counting, providing a list of values considered in that count.
Recommended Articles
We hope that this EDUCBA information on “Postgresql Count” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
